




プロトタイプはTSMCの28nm HPC+プロセス
実際のGSPの内部構造が下の画像である。2017年の発表時点では、個々のプロセッサーの詳細は説明されていない。

GSPの内部構造。個々のプロセッサーは1スレッドを実行するシンプルなものの模様。ただ具体的な演算能力などは不明
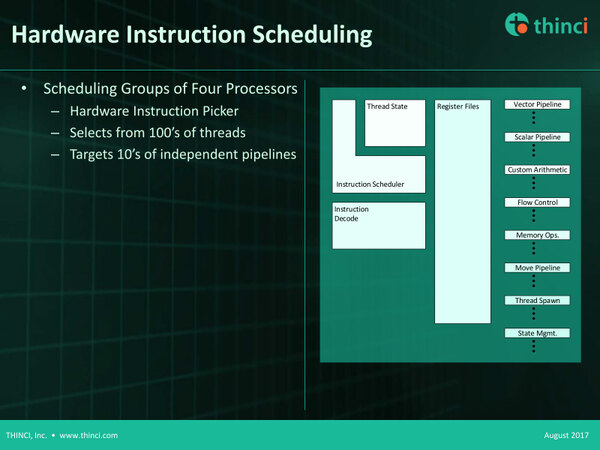
個々のプロセッサーの概略。これだけみると、Single IssueのIn-Orderの構成になっているように見える
全体としてみると、4つのプロセッサーコアを搭載するQuadという処理単位が複数個並び、その外側に2次/3次キャッシュが付く構造になっている。特徴的なのは以下のとおりで、トポロジー(構造)に特に制約は設けられていない。
- 全体のスレッドスケジューリングは、Quadの手前のThread Schedulerで処理される。
- Thread Schedulerはデータ依存性を理解し、実行リソースが利用可能で入力データが用意されているスレッドを選んで、個々のQuad内のプロセッサーに割り当てる
- リダクション命令が用意される。要するに複数要素を一つにまとめて結果を出すというもので、Convolutionにおける総和がまさしくこの例となる。これが並列に実行できるので、総和の計算(1回のConvolutionに必ず1回発生する)を大幅に高速化できる
- システム全体では、平均100あまりのスレッドがIn-Flight(稼働可能)状態に保たれ、そこから数十(これはQuadの数次第)のスレッドが並列実行される
- 原理的にGSPというか個々のプロセッサーでは、扱うデータタイプや精度、グラフのトポロ・Streamデータではなく、長期間滞在するデータ(例えばConvolutionの計算の際の総和)に対し、2次元配列としてアクセスする機能を持つ。これはメモリーアライメントと無関係にアクセス可能
- メモリーに対して2次元アクセスが可能
2017年の発表時にはTSMCの28nm HPC+プロセスを使って試作されており、スタンドアロンのPCIeアクセラレーターとSoC内部の組み込みの両方が可能ながら、SoCモードでは2.5Wで動作するという見積もりがなされていた。
ただこの時点では性能そのものは公開されておらず、2.5WはともかくとしてどこまでAIのアクセラレーターで使い物になるのかは未知数という評価だったと記憶している。
おそらくまだプロトタイプだったためもあるのだろう。ダイにブルーでマスクが掛けられており、これだともうなにがなんだかという感じ
DFPのWave Computingと同じ
Tailwood CapitalがThinCIに出資
ここで冒頭の話に戻る。デンソーは2016年にまずThinCIに出資しているが、2018年には追加出資している。またNSI-TEXEの設立は2017年9月であり、そこからDFPの開発をスタートしているわけで、中核にはこのGSPのグラフ制御の技術があったものと推察される。
実際GSPのストリームプロセッサーという構成そのものは、限りなくData Flow Processorに要求される方式そのものである。余談であるが、Data Flow ProcessorといえばAIの世界ではWave ComputingのDFPがいろいろな意味で有名であるという話を連載568回でした。
Wave ComputingはTailwood Capitalが出資者であり、それもあってTailwood CapitalのマネージングパートナーであるDado Banatao氏がWave Computingの会長を務めているわけだが、実はThinCIにもTailwood Capitalは出資しており、それもあって同社の取締役にもBanatao氏が名前を連ねているあたりがなんとも、という感じである。
ついでに言えばBanatao氏の名前が最初に出てきたのは連載20回。実はS3の創業者であり、また連載381回では触れていないが、C&Tの創業パートナーでもある。根っからの起業家体質の方で、その意味ではWaveは失敗だったのだろうが、立ち上げた会社が全部成功するわけでもないだろうから、そのあたりは割り切っているのかもしれない。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ


















の1台が今ならオトク!")


























")













