




10月20日~29日にかけてLinley Processor Conference Fall 2020がオンライン開催となった。このカンファレンス、同じメーカーが複数の発表を別々に行なうという例はこれまでもあったのだが、(ほぼ)同じ内容の発表を2回行なうという例は今回が初めてではなかったかと思う(一応建前としてはチップ単体と搭載カードと別製品の体裁は取っているが)。
これが可能だった理由は、イベントのプレミア・スポンサーになっているからだろうか。ちなみにプレミア・スポンサーはスポンサー費用が一番高価で、3社がリストアップされているが、うち2社はARMとインテルである。
というわけで、残る一社としてプレミア・スポンサーを務めるとともに2回の発表を行なったのはFlex Logicである。読者の中でこの会社のことを良く知っているという方はそうはおられないと思う。
独自のFPGAファブリックのIPと、最近ではReconfigurable(再構成可能)のロジックIPを提供しているIPベンダーということになるが、ここ数年はAIのそれもEdge Inference向けに注力しており、今回発表されたのはInferX X1という独自のAI推論チップである。
ダイサイズあたりのスループット最大という
独特な性能のAI推論チップInferX X1
そのInferX X1、Flex Logicによれば「ダイサイズあたりのスループット最大」という、あまり他では見ない独特な性能の高さのアピールの仕方をしている。同社のInferX X1は、独自のReconfigurable Tensor Processorに4MBのSRAM、それとLPDDR4Xチップ1個を組み合わせた形で構成される。
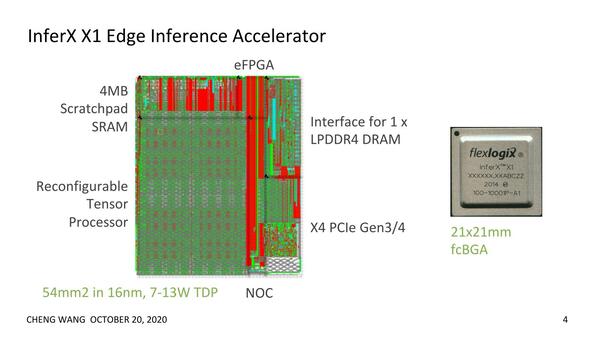
「InferX X1」は、4MBのメモリーを実装していることもあって、16nmで54平方mmなので、決して小さいわけではないが、比較対象はもっと巨大なので十分競争力があるというのがFlex Logicの見解だ
Flex Logicの見解というのは、現在のEdge AIというとNVIDIAのJetson Xavier NX(Edge Embedded System向け)やTesla T4(Edge Server向け)がリーダーになっているとしたうえで、そのXavier NXやTesla T4と比較しても、十分に高速というのが同社の説明である。そのうえで、単位面積あたりの処理性能で比較すると圧倒的というのが同社の見解だ。
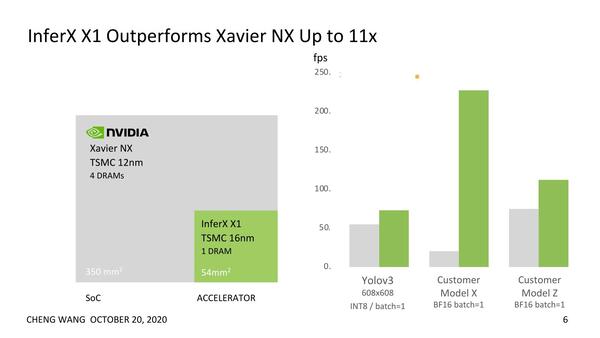
左はチップのダイサイズ比較、右が実際に推論を行なった際の速度である
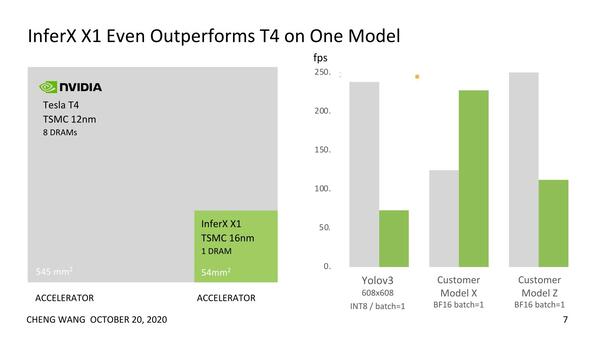
Telsa T4との比較がこちら。Customer Model Zではやや性能的に負けている
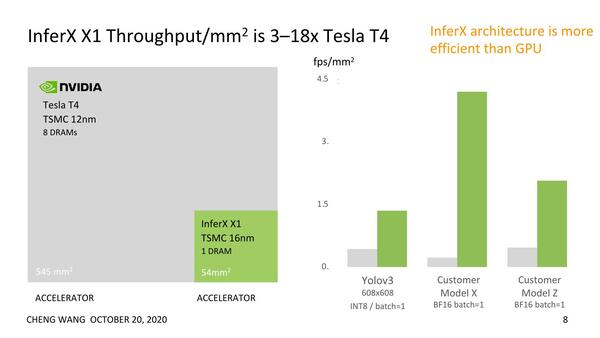
ダイサイズの1平方mmあたりのフレームレート、という指標はある意味斬新ですらある
もちろんこれは、Flex Logicが最終的に売りたいのはチップだけでなく、このX1のIPも可能であれば売りたいと考えているからでもある。チップそのものを売るのであれば、端的に言えば製造プロセスやダイサイズは顧客にとっては直接には関係ない話であって、性能と価格、消費電力が要求に見合っていれば内部がどうかというのはわりと関係ない。
ところがFlex Logicが狙っているのは、将来顧客が自社製品を独自に作るにあたり、そこに内蔵するAIアクセラレーターとしてInferX X1を採用してもらうことである。
そのためには、単に性能が高いだけではだめで、AIアクセラレーターが占める面積をどうやって抑えるか、外付け部品をどこまで減らせるか、といったことが重要なファクターになる。先の画像のダイサイズ1mm2あたりのフレームレートはこうした観点で見ると、非常に重要な指標になるわけだ。
ただ、実はIPだけを提供するビジネスでは、なかなか使ってもらえないというデメリットもある。当たり前の話で、IPを組み込んでASICを作るなりFPGAに実装するなりしないと試すこともできないため、特に競合製品が山ほど湧いてきている昨今では、顧客がベンチマークを行なう前の検討段階で落ちてしまうこともあり得る。
実際に顧客に評価してもらうためにはどうするかというと、それこそ評価ボードを提供するなりFPGAでの実装を提供するなり、ということで顧客が簡単に自分のアプリケーションを載せて、その性能がニーズを満たせるかどうかを評価できるようにする必要がある。
加えて言えば、自社の製品を広範に使ってもらいたいとなると、自身でASICを作る気がない顧客に対するソリューションも必要になる。具体的には、現在Tesla T4をベースにEdge Serverを構築しているような顧客だ。こうした顧客にも使ってもらえるようにしたいとなると、単に評価ボードのレベルでは厳しく、最終製品への組み込みも可能なものが必要になる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















