



ロードマップでわかる!当世プロセッサー事情 第581回
謎が多いGeForce RTX 3000シリーズのプロセスとGDDR6X NVIDIA GPUロードマップ
2020年09月21日 12時00分更新

ビデオメモリーに採用された
Micronの独自規格GDDR6X
GeForce RTX 3000シリーズの発表にあわせ、Micronも正式にGDDR6X SGRAMを発表した。Micronによれば、そもそもデータバスにPAM-4(Pulse Amplitude Modulation-4)を用いるという話は、2006年から手掛けてたという。
もっともこれは製品というよりも研究開発のレベルの話である。実際の製品化に向けた開発のスタートは、2017年だったそうだ。

製品化に向けた開発は2017年にスタートしたと、Micronの“Feeding the Beast: the Making of GDDR6X”でTim Hollis氏(Fellow and Signaling Expert)が発言した
さてまず基本的な話。これまでPCに使われる主要な信号伝達方式はNRZ(Non Return to Zero)という方式で、信号が0か1かのどちらかしかない、というものだ。
“Non Return to Zero”の意味は「『信号がない』という状態がない」の意味である。信号レベルが0だったら、それはデータが0であると見なされ、信号がないとは見なされない。ところがこの方式では、1回の転送で1bit分のデータしか転送できない。
そこで、信号レベルを0と1でなく、-3/-1/1/3と4値にすれば、1回の転送で2bit分が転送できる。これがPAM-4である。実際にはもっと多いPAM-8(信号レベルが8段階、1回の転送で3bit送れる)やPAM-16(信号レベルが16段階、1回の転送で4bit送れる)なども実用化されている。
この仕組み、最近のNANDフラッシュを考えてもらうとわかりやすい。NRZというのはSLC NAND、PAM-4がMLC NAND、PAM-8がTLC NANDというわけだ。
実はネットワークの世界では、このPAMは次第に広く利用されるようになってきた。100Gbpsを超えるイーサネットでは、PAM-4を併用して1レーンあたり50Gbpsや100Gbpsを実現するのが普通になってきた。
あるいは現在使用策定中のPCI Express Gen6も、信号速度そのものはGen5と同じ32GT/秒であるが、PAM-4を併用することでレーンあたり64Gbpsを達成する見込みである。技術そのものはかなり昔からあったもので、それほど珍しい話ではない。
さてそのMicronであるが、もともとGDDR5とGDDR6の間にGDDR5Xを挟む形で、独自規格のメモリーを出すことにそれほど抵抗はなかった。

Micronのロードマップ。一番左はピン1本あたり、真ん中はメモリーチップ1個(=32bit)あたり、右はシステム(=メモリチップ12個)あたりの帯域を示す
GDDR5Xの場合、後追いでJEDECの標準化も行なわれたが、結局これを採用したのはNVIDIAのGeForce GTX 1000シリーズのみだったこともあってか、MicronによればGDDR6XをJEDECで標準化するプランは今のところないとされる。
さてそのGDDR6Xであるが、これはGDDR7の策定が遅れており、その一方でGDDR6はピンあたりが16Gbpsが限界となっているため、これ以上の帯域を得ようとすると以下の対策が必要となる。
| 帯域を得るための手段と課題 | ||||||
|---|---|---|---|---|---|---|
| 手段 | 課題 | |||||
| HBM2/2Eに移行 | Silicon Interposerが必須となる関係で、チップそのもののコストが上がるうえ、HBM2/2Eのコストも高い。またチップ製造の後工程の段階でメモリーチップの容量が決まってしまうので、OEMがメモリーの容量を変更できない(NVIDIA側で2種類のメモリー容量を持つチップを準備する必要がある)。 | |||||
| チップの数を増やす | 今ですら384bit(=12個)のチップを無理やりGPUの周りに苦労して配している状況であり、これを増やすとなると配線距離を伸ばしてGPUから少し遠いところにメモリーチップを置く形になる。
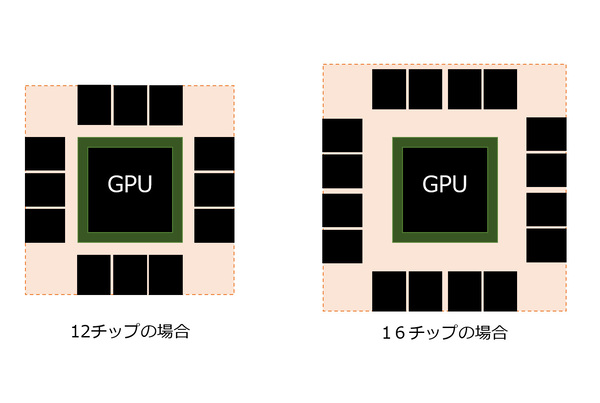
チップの数を増やすには、配線距離を伸ばしてGPUから少し遠いところにメモリーチップを置くことになる |
|||||
したがって、HMB2/2Eと多チップ化のどっちもどっち、という状況に対する解が、PAM-4を使うことで帯域を引き上げて解決する、というGDDR6Xだったわけだ。
さて、GDDR6XでPAM-4を使うことのメリットは他にもある。1回の転送で2bit送れるということは、転送速度自体は半分に減らせるという意味でもある。
下の画像はMicronが提示する、16GbpsをNRZとPAM-4で送った場合の波形を比較したものだ。ここで信号の合間をEYEと呼ぶのだが、そのEYEの高さ(EYE Height)と幅(EYE Width)が信号伝達では重要になる。
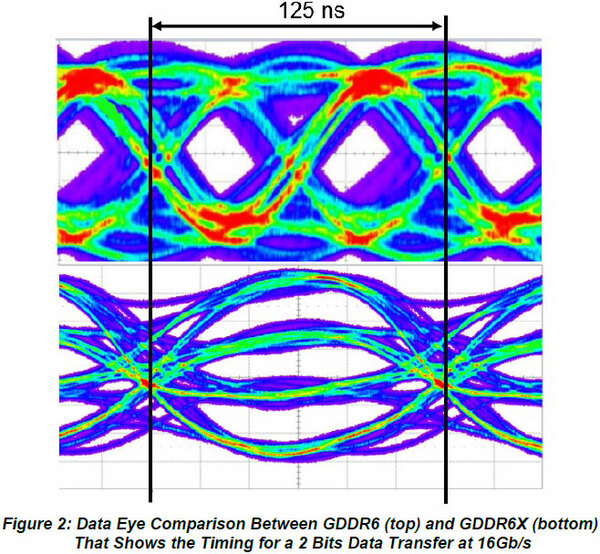
NRZとPAM-4の波形を比較したもの。PAM-4の場合、EYEが3つに増えるので、この3つのEYEがすべてきちんと高さと幅を取れるようにしないといけないのが難しいところではある
下図でNRZ(上)とPAM-4(下)を比較すると、EYE Heightそのものは確かに半分ほどに下がる。その一方でEYE Widthそのものは2倍に広がることになり、より長時間のSampling & Holdが可能になる。
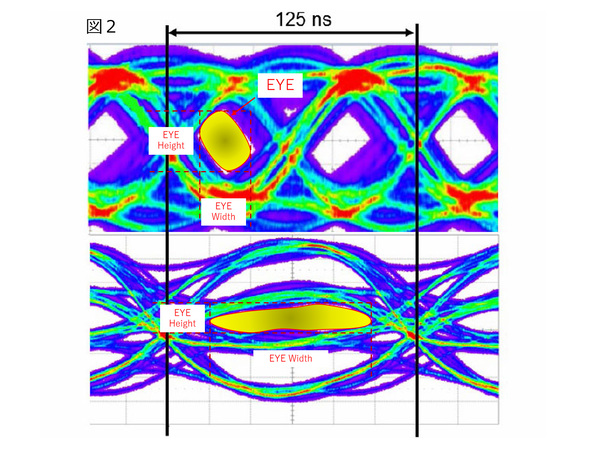
EYE Heightは半分ほどに下がるがEYE Widthが2倍に広がる。これにより、より長時間のSampling & Holdが可能になる
また信号のバラつきそのものもPAM-4の方が少ない。これは信号の周波数そのものが半減していることに起因するため、実はPAM-4でもそんなに信号伝達は難しくないことが見て取れる。
さらに言えば、信号速度が落とせる分、信号伝達に必要な電力が減るというメリットがある。実際Micronによれば、14GbpsのNRZと21GbpsのPAM-4で1bitを転送するのに必要な電力は、PAM-4の方が15%少ないとしている。
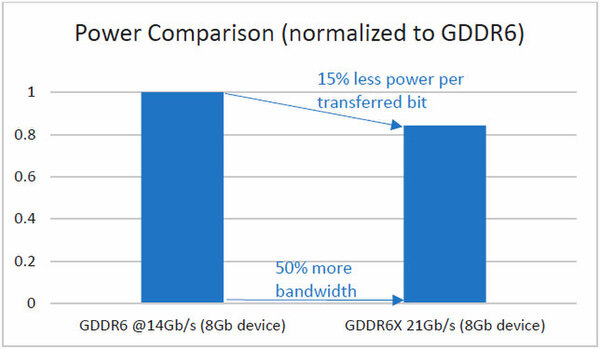
1bitを転送するのに必要な電力は、PAM-4の方が少ない。もっともこれは1bitあたりの電力なので、2bit分を転送する実際の消費電力という意味では21Gbps PAM-4は14Gbps NRZの70%増し、ということでもある
ところでこのPAM-4のエンコードやデコードのために、メモリーチップに複雑な回路を入れるのはコスト的に難しい。このためGDDR6XのPAM-4のエンコードは下の画像のようなシンプルな方法で実装されている。
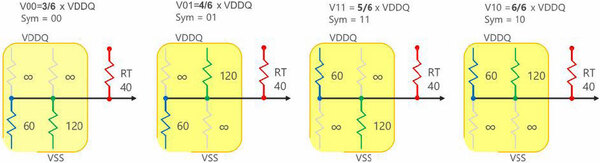
抵抗による電圧降下だけで信号を作る形。VDDQは1.25Vないし1.35Vなので、その1/6の電圧で区分けする形になる(VDDQ×0, VDDQ×1/6、VDDQ×2/6は使わない)
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ



















の1台が今ならオトク!")

























")













