




第2世代EPYCで80の世界記録を達成
話が逸れてしまったので戻したい。性能の話であるが、AMDは第2世代EPYCで80の世界記録を達成した、と発表している。
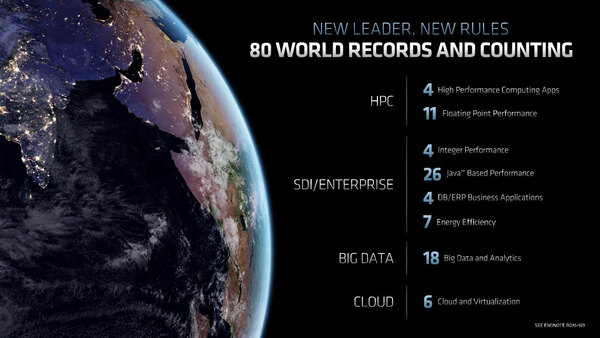
第2世代EPYCが達成した世界記録80種類の内訳
この80の内訳はAMDのウェブサイトで細かく説明されているが、以下の具合に、SPECjbbやTPC系のサーバーワークロード向けのテストが多めとなっている。
| 第2世代EPYCが達成した80の世界記録 | ||||||
|---|---|---|---|---|---|---|
| テスト項目 | テスト数 | |||||
| SPEC CPU 2017 | 13テスト | |||||
| SAP | 2テスト(*2) | |||||
| SPEC Accel Open ACC/OpenCL | 4テスト | |||||
| SPEC MPI 2007 | 1テスト | |||||
| SPEC OMP(G) 2012 | 1テスト | |||||
| SPECjbb2015 | 26テスト | |||||
| SPECpower_ssj2008 | 7テスト | |||||
| SPECvirt_sc2013 | 1テスト | |||||
| TPC-DS | 3テスト | |||||
| TPC-E | 2テスト | |||||
| TPC-H | 7テスト | |||||
| TPCx-HS | 6テスト | |||||
| TPCx-IoT | 2テスト | |||||
| TPCx-V | 3テスト | |||||
| VMmark | 2テスト | |||||
(*2) ウェブサイトのリンクにミスがあり、そのままアクセスしても404エラーとなる。正しくは https://www.sap.com/dmc/benchmark/2019/Cert19044.pdfである。
こうしたベンチマークとは別に実アプリケーションでも、Xeon Platinumと比較してより高い性能を実現できるというのがAMDの主張である。

Xeon Platinumとの比較。このうちいくつか(Altair Radioss、Blenderなど)は会場で実際にデモも行なわれていた
ちなみにHPCの分野では、今年1月のCESにおける基調講演の概略をAMD HEROESで書かせていただいたが、ここに出てきたイリノイ大のNAMDベンチマークに関しては、その後4月にインテルがData-Centric Innovation Dayというイベントの中で、Cascade Lake-APで10.65ナノ秒/日の性能をアピールして「1ソケットで7nm EPYCより高速」と説明していたが、Cascade Lake-APを1ソケットとするのは(嘘ではないが)無理がある気がする。
さらに言えばXeon Platinum 8180が8.40ナノ秒/日だったのに、コアの数が倍のXeon Platinum 9282がたったの10.65ナノ秒/日でしかないあたりも不思議である。
AMDの担当者にこの件を聞いたところ、「消費電力が違うから比較にならない」と一言で終わりであった。HPCの市場でも、実際TCO (Total Cost of Ownership:総保有コスト)が大きなポイントとなっていることを考えると、消費電力は同等にそろえないとまずいような気はする。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ











、バッテリー駆動時間は13時間超え。もう欲しくなる要素しか見つからないッ!")








ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")
















