
今週はIDFの開催に合わせて明らかにされたKaby Lakeのアップデートや、14/10nm FinFETプロセスの状況などを紹介しながらインテルのCPUアップデートを……と思ったのだが、IDFの裏番組でAMDがZenのアーキテクチャーと動作デモを行なうという、なかなかインパクトのある発表会を開催したので、急遽こちらの情報をもう少し掘り下げて解説したい。

Zenのアーキテクチャーの推定は連載332回と連載333回で説明しているが、今回の発表はこの推定がまるっきり違ったわけではないことを裏付けてくれるものとなり、筆者的には胸を撫で下ろしていたりする。
ということで、まずは発表資料から説明していきたい。ちなみにスライドは超横長(3:1フォーマット)で構成されていて、そのまま掲載すると横が長すぎで縦方向が潰れてしまうので、スライドの一部を抜き出す形で掲載させていただいている。
「Summit Ridge」のクロックあたりの命令実行数が40%向上
まず下の画像がコア全体の構成となっている。x86のデコーダーは4 issueであるが、やはり予想通りμOp Cacheを1次キャッシュとは別に装備する形になっている。
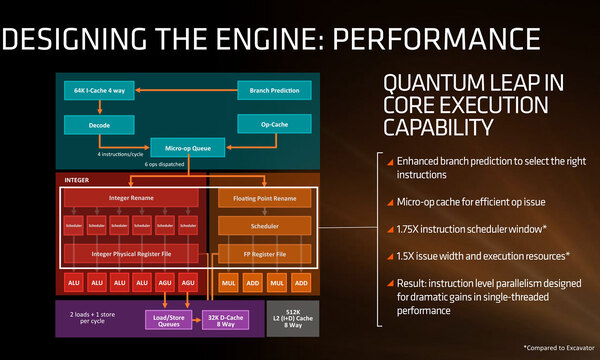
Zenの構成図。もともとZen世代ではIPCを40%向上させるとしており、確かにこの程度の構成は必要になるだろう
画像に“Micro-op Queue”と記されているのは、要するにDispatch Unitであって、最大6つのμOpを発行可能である。
実行ユニットはALU×4、AGU×2、FPU×4の10個であるが、おもしろいのはALU/AGUについては各実行ユニット毎にスケジューラーが別に用意されていることだ。
AGUはともかくとしてALUに関しては、4つのALUが対称性が高い(どのALUでも同じように命令を処理できる)と想像される。逆にFPUに関しては、必ずしも対称的な構成ではない※ため、まとめてスケジューリングを行なわないといけないと判断される。
※:連載333回でも書いたが、特にFMA命令の処理ではFP3がボトルネックになるというか、FP2の実装がなぜかFMAに関して欠落しているという問題がある。
ちなみにその他の特徴としては「分岐予測をさらに強化」「Scheduler WindowをExcavator比で1.75倍に」といった事柄が挙げられており、1スレッドあたりのIPCを大幅に引き上げられたとする。
一方キャッシュ周りだが、命令1次キャッシュは64KB、データ1次キャッシュは32KBとなっており、さらに統合2次キャッシュが512KB用意される。ここまではコア毎のキャッシュで、それとは別に外部に共有3次キャッシュが最大8MB搭載される形だ。

明記はされていないが、もうExclusive Cacheの構成はやめて、一般的なInclusive Cacheになったと思われる。コアあたりのBandwidthが5倍、という話は計算方法がよくわからないので留保にしておきたい
なんというかインテルのCPUの構成に非常に近くなっている。実のところ、性能だけ考えればこの方がずっと良い。
それにも関わらずAMDがこれまで複雑なキャッシュ構成にしていたのは、伝統的にCPUパイプラインに要するトランジスタ数が多すぎて、インテルと同じキャッシュ構成を取ろうとするとダイサイズが大きくなりすぎてしまうので、どうしてもキャッシュ容量を少なめにせざるを得なかったという経済的な事情による部分が大きい。
ただZen世代では14LPPのお陰で、キャッシュをインテルと似たような構成にしても、現実的なダイサイズで収まるようになった、というあたりではないかと思われる。
そのキャッシュの帯域であるが、完全に32バイト/サイクルでコア~3次キャッシュまでがつながることになった。
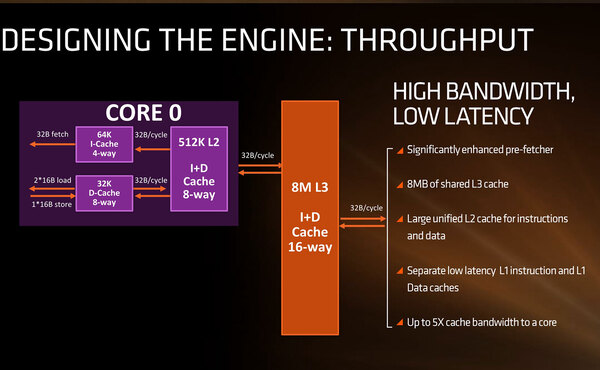
これを見ると、1次キャッシュの帯域を32バイト/サイクルまで引き上げた結果、発熱過多に陥ったBarcelonaコアを思い出してしまい、ドキドキする
これは特にSSE/AVX命令の処理などでのスループット向上に明確に貢献すると思われる。もっともこのSSE/AVXに関しては、Skylake世代とは異なりAVX256命令を1サイクルあたり1命令(FMAを1命令と数えた場合)実行する構成であることが帯域からも確認できる。
データ1次キャッシュは16バイト/サイクルのLoad×2と16バイト/サイクルのStoreを同時に行なえる構成になっており、これはAVX256命令1個分に相当するからだ。
SkylakeはAVX512命令を実行するために、Load/Storeユニットを合計4つ搭載しているが、ここまで無理する必要はないと判断したようだ。
またSMT(Simultaneous Multi Threading)構成を取ることは前から明らかになっていたが、改めて確認された。2つのスレッドにあわせ、Program Counterなどの「プログラムからアクセスできる」レジスターだけは二重で用意されるが、内部は共通という、ハイパースレッディングなどと同じ実装方式である。

実際これだけ実行ユニットが多いと、プログラムによっては十分に実行ユニットを使いきれないケースもあるはずで、そうした場合にSMTの構成は効果的である
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ













