
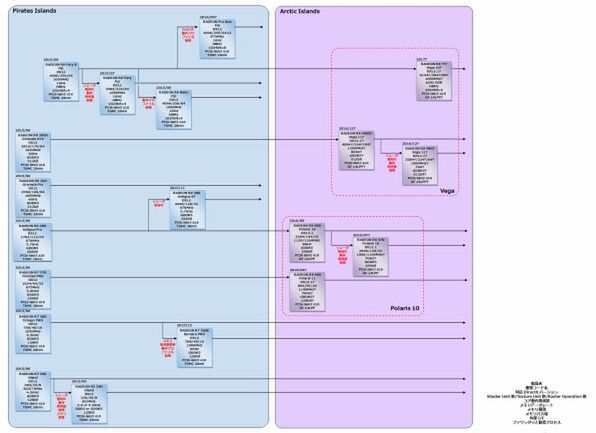
2015年~2017年のAMD GPUのロードマップ
筆者が予想するRadeon RX 490のコアはVEGA 11
Radeon RX 490/Radeon RX 490X(この名称も正確には不明だが)は、最大で64CU/4096 シェーダー構成になるとする情報が多い。この数字そのものは、まず間違いないだろう。
CUあたりの性能はPolaris世代で15%ほど改善されており、さらに動作周波数も無理なく1.2GHzあたりまで引き上げできているため、同じ64CU構成のFijiコアと比較して40%ほど性能が改善する計算だ。
これならGeForce GTX 1070/1080あたりとは十分競合できるだろう。ただしHPC用のFirePro Sシリーズなどの後継としては、これは不十分である。
そこで筆者は、10月に前倒しされたと噂されるRadeon RX 490相当のコアは、VEGAの小さいほうのバージョンと目されるVEGA 11ではないかと考えている。
大雑把に言えば、ダイサイズは400mm2程度。GlobalFoundriesの14LPPが現在このサイズのダイを高い歩留まりで製造できるのか? という疑問はあるのだが、逆にこの先はもっと大きなダイが予定されているわけなので、がんばって製造しても不思議ではない。
このVEGA 11が今年10月に製品をもし出せるとすると、逆算するとエンジニアサンプルのダイはもう評価を開始している時期である。実際、Polaris 10/11の設計が一段落した時点で、すぐにVEGA 11に着手したと考えれば、辻褄はあう。
ではVEGA 10はどうだろうか。NVIDIAで言うところのGP100コアに対抗できる規模のものになるだろう。図には暫定で96CU構成で搭載したが、実際には100CUくらいの構成で、そこから歩留まりを上げるために4CUほど無効化、なんて可能性もあるだろう。
ただ、これを一枚岩なダイで製造できるのか?という疑問は当然湧いてくる。仮に100CUとし、かつダイサイズがおおむねCU数に比例すると考えると、100CUでは640mm2を超えるものになる。
もちろんFijiコアはすでに600mm2を実現していたが、あれは実績と定評のあるTSMCの28nmプロセスだから実現できた話で、もしGlobalFoundriesの14LPPでいきなりこれを作れるかどうかはわからない。
もちろん可能性としては、VEGAがTSMCの16FF+になるという話もあり、これが実現できれば610mm2のGP100をすでに量産しているため実現の可能性はあるのだが、このあたりがはっきり見えなくなっている。
では、GlobalFoundriesだと作れないのかというと、そんなことはなく、俗に2.5D接続などと言われている方式を使ったマルチチップ構成を取れば容易である。
たとえば50CUのダイを2つ用意し、これを半導体と同じくシリコンを使った配線層(Silicon Interposer)の上に乗せて結合する方式である。すでにAMDはFijiの世代で、HBMの接続にこのSilicon Interposerを利用している。
広く業界を見ると、たとえばXilinxはこれを利用して4つのFPGAのダイを1つのチップとして構成した製品を数年前から出荷している。そのうえ、HiSiliconはプロセッサーとI/Oを別々のプロセスで製造し、間をSilicon Interposerで結合している。
あるいはMarvellはMochiと呼ばれる新しいチップ間インターフェースを開発し、製品に採用しているが、これも物理的にはSilicon Interposerである。
これはあくまで可能性のひとつであって、本当にこうした実装になるかどうかは不明だが、やってやれないことはない、という例として紹介しておく。
話を戻すと、そんなわけでVEGA 10は100CU近い巨大なダイになる。当然フルに活用するためには広帯域メモリーが必要であり、間違いなくHBM2の構成になるだろう。問題はVEGA 11のメモリーシステムだ。
図ではRadeon RX 490Xとした製品の構成は、Radeon RX 470の構成を倍にした程度である。ということは、必要となるメモリー帯域もせいぜいが512GB/秒程度あればいい計算になる。
一方HBM2の場合、1GHz DDRで1024bit幅なので、1個あたり256GB/秒、2つで512GB/秒になるため、この構成を利用する可能性もある。ただ512GB/秒であれば、8GHz GDDR5の512bit構成でも実現できることになる。
ちなみにHBM 1という可能性は皆無だ。帯域的にはHBM1を4つつめば512GB/秒だが、HBM1ではメモリースタック1個あたり1GB以上の容量が搭載できない。
すでにRadeon R9 300シリーズやRadeon RX 480がハイエンド8GBになっている現状では、HBM1という選択肢はありえないことになる。
ではGDDR5とHBM2では現状どちらが高価かというと、HBM 2の方であって、VEGA 11に関してはGDDR5を利用するというシナリオを図には記した。
実際このクラスだと消費電力も相応に多いだろうから、Radeon RX 480のカードサイズは維持するのが難しい。ある程度カードサイズが大きくなるなら、GDDR5を16個搭載するのも無茶ではないだろう。
AMDはVegaに続き、2018年中旬にNaviと呼ばれる次のコアを用意するとロードマップでは示しているが、こちらに関しては現状一切情報がない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ













