




Linuxベースのクラスターで構築された
最初のシステム「MCR」
下の画像がMCRの概要である。計算ノードはMPIを使って相互通信する仕組みで、それぞれローカルストレージは持つが、本格的なストレージはNFS(Network File System)の形で外部に置かれる。またI/Oもネットワーク経由の接続となっている。
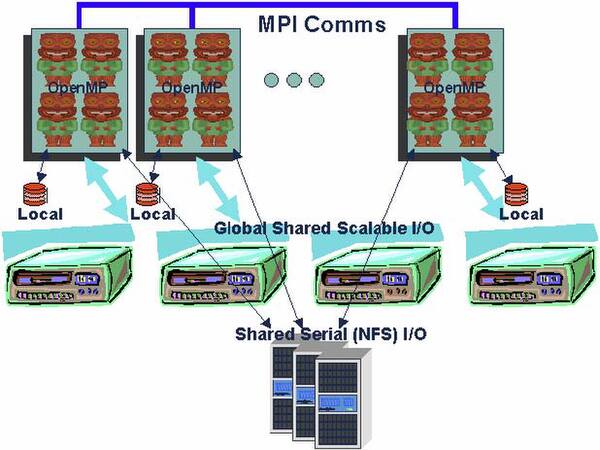
NFSというあたりがいかにも時代を感じさせる
画像の出典は、“M&IC Capability Cluster (MCR)”
実際の計算サーバーであるが、ハードウェアはPrestonia世代のXeon 2.4GHzをIntel E7500チップセットと組み合わせたものが、1116プロセッサー並ぶ構造が最終的に採用されたとのこと。
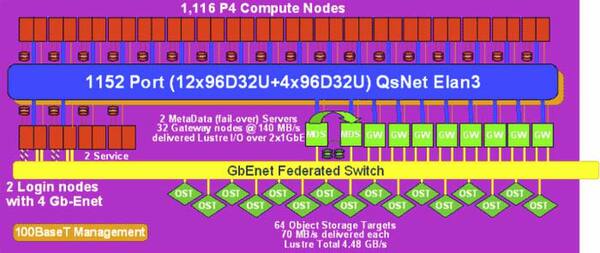
計算ノードはQsNet Elan3で相互接続され、これとI/Oやストレージはゲートウェイ経由でギガビットイーサネットで接続される構造だ
画像の出典は、“M&IC Capability Cluster (MCR)”
これに先立ちFoster Xeon+i860+Direct RDRAMや、Prestonia+ServerWorks GrandChampion LEの構成も試してみたが、FSB経由のメモリーアクセスがボトルネックになることが確認された。400MHz FSBではメモリーアクセスが遅すぎるので、多少マシな533MHz FSBの構成を選んだと思われる。
Pentium 4ベースという選択は、浮動小数点演算性能を重視したとの話。当時はまだOpteronが出る前だったため、妥当な選択と思われる。
この計算ノードはQsNetのElan 3で相互接続される。QsNetはASCI Qでも利用されたインターコネクトであり、元をただすとMeiko ScientificのElan-Eliteという話は連載329回で説明したとおり。
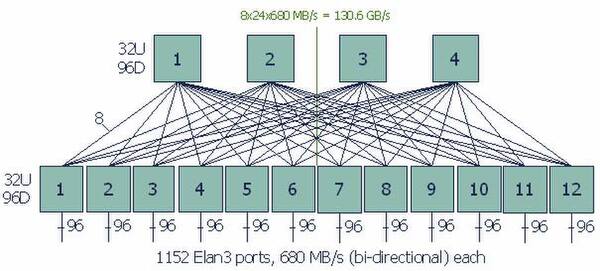
QsNetのElan 3で相互接続された計算ノード。この図では転送速度が双方向で680MB/秒となっており、片方向の350MB/秒というのはカタログスペックなのかもしれない
画像の出典は、“M&IC Capability Cluster (MCR)”
Elan 3は初代QsNet用のアダプターで、転送速度が片方向あたり350MB/秒、MPIを使った場合のレイテンシーが5ナノ秒とされていた。このElan 3アダプターと対になるElite 3を96ポート集約したスイッチを12個並べ、さらに上位にスイッチを4つ並べたFat Tree構造を取った。
このMCRは2003年3月に7.634TFLOPSを実現し、2003年6月のTOP500では3位につける好成績をたたき出す。ちなみに1位は地球シミュレータ、2位がASCI Qなので、これはかなり良い結果であった。
ただ、MCRは核実験シミュレーション「以外」をターゲットとしたシステムだったため、核実験シミュレーション向けのCapacity Computing用のシステムが別途必要、という判断がなされた。
このため、2002年にローレンス・リバモア国立研究所はIBMと契約、ASC Purpleの一部(詳細は不明だが、スイッチやシャーシ類と思われる)を流用しつつ、計算ノードの中身をDual Pentium 4 Xeonに置き換えたALC(ASCI Linux Cluster)を2003年から稼動させる。

ALCの概要。もともとASC Purple自身がPower 5を搭載したSystem P5 570を集約する構成だったため、これをXeonベースのものに置き換えただけであろう
画像の出典は、“LLNL ASCI Resources”
これとは別に、ローレンス・リバモア国立研究所はもう1つ、Thunderと呼ばれる新しいLinuxクラスターを2004年から稼動させ始めた。こちらはQuad Core Itanium 2 Serverを1024台集積した構成だ。こちらを手がけたのはCalifornia Digitalで、当時は社員数55人の小さな規模だったらしい。
内部構成はQuad Core(1.4GHz)のItanium 2(Tiger 4)を1002ノード、QsNet II(Elan 4/Elite 4を利用)で接続したものである。こちらは2004年6月のTOP500では19.94TFLOPSを叩き出し、ASCI Qを抜いて2番手(トップは相変わらず地球シミュレータ)に躍り出る。
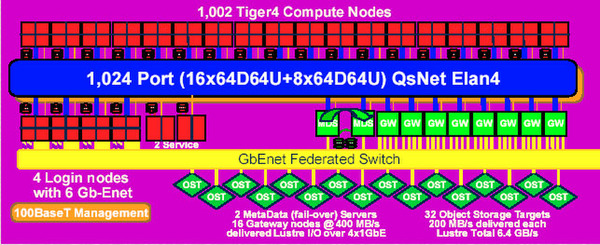
構成そのものが前述のMCRと同じなのは、ローレンス・リバモア国立研究所の意向があったものと思われる
画像の出典は、“Using Thunder”
もうこうなるとASCI Qの存在意義が本当に問われかねない状況になっていたことがよくわかる。ASCIそのものの用途は、2003年の時点で引退していたのも無理ないところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ

















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")












ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












