



「知的」や「かわいい」を数値化して好みの(用途に応じた)声を簡単にデザイン
性別、年齢などを操作して声を自在に合成する「声デザイン技術」、東芝
2016年03月09日 16時31分更新

声デザイン技術
東芝は3月8日、用途にあわせて多様な声を簡単かつ自在に音声合成で作成できる「声デザイン技術」を開発したと発表した。
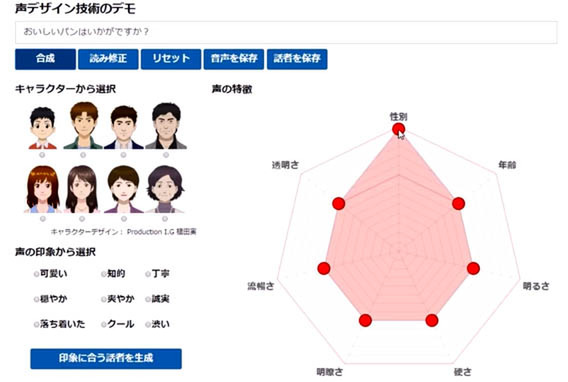
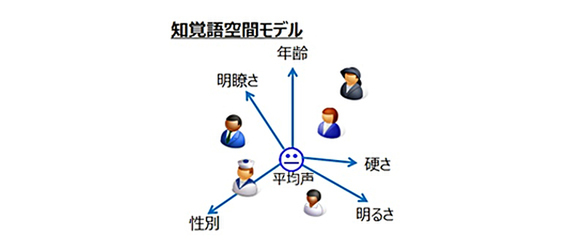
独自のモデル最適化方式により、性別・年齢・明るさなどの知覚的な声の特徴を示す複数の要素(知覚語)に分解してモデル化した「知覚語空間モデル」を開発。この空間モデルを操作できるGUIを試作し、各要素の強度を変化させて声を自由に作成できる。
声の「知覚語空間モデル」
さらに、求める特徴の声を簡単に作り出せるように、かわいい・知的・丁寧といった声の印象を表す印象語から「知覚語空間」の座標を定める「印象語変換モデル」も開発してGUIに組み込んだ。かわいい・知的などの印象語やキャラクターの顔画像からベースの声を選定し、さらに性別や年齢などで絞り込み、利用者のイメージに合った声を効率的にデザインできる。
同社では、クラウドサービス「RECAIUS(リカイアス)」に2016年度中に搭載することを目指して研究開発を進めるとしている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります











ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












