




演算性能を上げるために
細かい並列性を高める
さて、問題はNumeric Processorの方だ。当時もうすでに演算性能を高めるためには並列度を上げるしかないことはわかっており、方法論としては荒い並列性(Coarse-grained parallelism)と、細かい並列性(Fine-grained parallelism)の2つがあることも知られていた。
荒い並列性は、要するに超並列処理につながるマルチプロセッサーの方向で、一方細かい並列性はベクトルやSIMD、あるいはVILWである。実装でどちらが楽かという観点で言えば、数を並べれば済むぶん荒い並列性の方が良い。
ところがこの当時はまだ並列実行のFortranはあまり一般的ではなかった。したがって、既存のFortranで書かれたアプリケーションをそのまま移植しても性能は期待できない。
実際にはこの当時、マルチプロセッサーや超並列システムを利用するためには、その機種専用のライブラリーを呼び出す形で処理を並列化できるようにプログラマーが明示的に記述する必要があり、またFortranコンパイラ自身も大きく手をいれないといけない。
当然これには人手が必要で、それは当時の同社には手に余ると判断したようだ。結局同社は細かい並列性を高める方に走った。
念のために書いておくと、「細かい並列性を高めるほうはコンパイラに手を入れる必要はない」ということはまったくない。
新規のプロセッサーを作るわけだから、命令セットの最適化を含む大量の作業が必要になる。ただそれでも「荒い並列性を実装することを考えたら、ずっと楽」というだけの話である。
細かい並列性を高めるというのは、同時実行できる命令を増やすということである。Cydra 5の実行ユニット(Function Unit)は、下図の構造になっている。
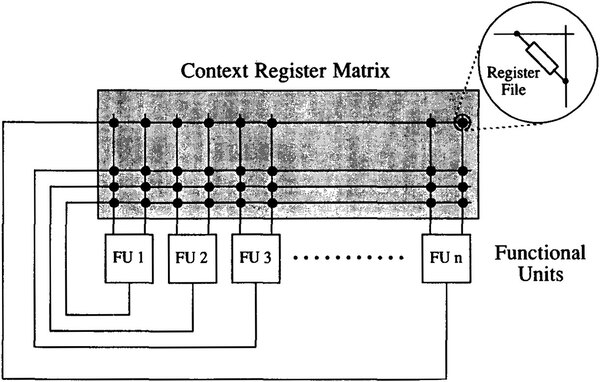
実行ユニットの構造。ちなみに同社はこの方式をSIMOMD(Single Instruction, Multiple Operation, Multiple Data)と称し、略称をMultiOpとしている
これはなにをやっているかといえば、例えばY=A×B+Cを計算する場合、FU1でA×Bの乗算を行ない、次のサイクルではその結果をFU2のレジスターファイルに格納する。
FU2は結果が格納されたらそれとCを取り込んで(A×B)+Cの加算を行ない、その結果をFU3のレジスターファイルに格納する。
次のサイクルで、FU3は結果を取り込んでその結果をメモリーに書き出す。つまりパイプライン動作を簡単に実行できることになる。
MAC演算のパイプライン化そのものは珍しくないが、Cydra 5では自由に実行ユニットの結果をつなげてパイプライン化できるというもので、このあたりの仕組みは汎用プロセッサーというよりはDSPのような感じだ。
このFUの構成をもう少し描いたのが下の画像である。FPUのうちAdder/Integer ALUは4サイクル、Multiply/Integer Div/Integer Sqrtは5サイクル、Memory Data Port 1/2は17サイクルのレイテンシーで動作するが、内部は完全パイプライン化されている。
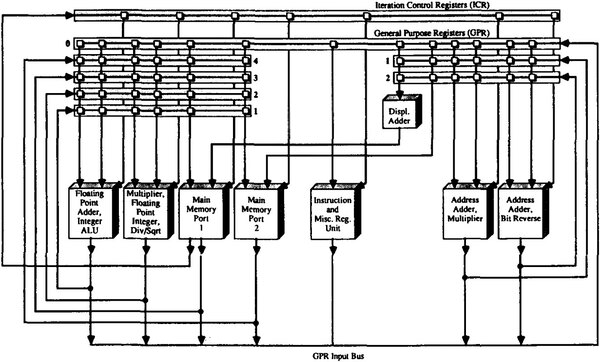
Function Unitの構成。ちなみに左半分がData Cluster、右半分がAddress Clusterと称される
先ほどの例で言えば、まずA×Bの乗算をFloating Point Multiplierで実行すると、5サイクル後に結果が出てくる。これはフィードバックループを通して2番の列のGPR(General Purpose Register:汎用レジスター)に格納されるので、これとCの値をFloating Point Adderは取り込み、3サイクル後に(A×B)+Cの演算結果が出力される。
この値は再び1番の列のGPRに書き込まれるので、これをMain Memory Portの1か2のどちらかが取り込み、17サイクル後にメモリーに書き出し終わる。
ちなみに、Numeric ProcessorとMain Memoryの間はそれぞれ100MB/秒の帯域を持つポート3つで接続されており、例えば読み込み200MB/秒、書き出し100MB/秒といった使い方ができる。
これは単純な演算であれば単精度(32bit)で25MFLOPS、倍精度(64bit)で12.5MFLOPSに相当する性能である。
実際には先のMAC演算のようなケースでは演算数が倍になるため、単精度なら50MFLOPS、倍精度なら25MFLOPSが可能になる計算で、これはCydra 5の構成図に出てきたNumeric Processorの性能ときっちりマッチしている。
当然ながら、こんな複雑な実行ユニットを自動的に最適化するのは当時の技術では不可能であり、ソフトウェア任せとなる。この結果、Cydra 5のNumeric Processorは下の図のように32バイトもの長さのVILW構成となっている。
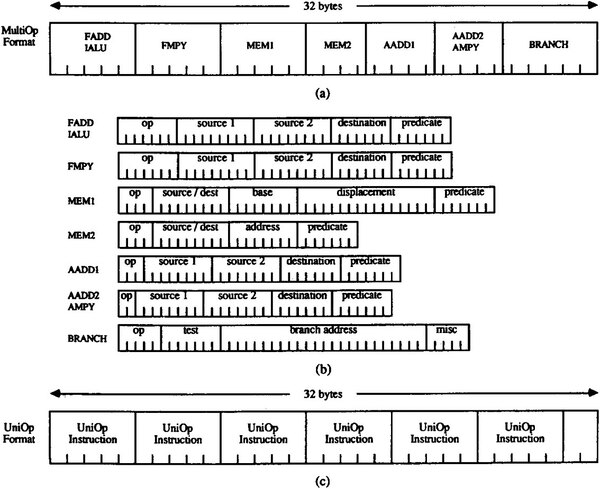
上のMultiOp((a)と(b))は、並列性を最大限に利用したい場合に利用する。ただ、並列性がない場合には無駄が多くなるので、別にUniOp(c)というフォーマットも用意した。こちらは複数のFUのどれか1つだけを動かすのに利用される
この長大な命令の中で、それぞれのFUに対してどんな演算を行ない、その結果をどこに書き出すかをすべて指定することで、効率的に実行しようとした。
このあたりをCPU任せにせず全部ソフトウェア側でやるというのは、FPSのAP-120Bと発想的には同じである。
当時の技術ではそのあたりのスケジューリングや調停を、CPU任せにするのは不可能だったのは仕方ないところだろう。
→次のページヘ続く (目標のスペックを達成するも会社が倒産)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































