




14nmプロセスのZenコアは
実行命令数が40%向上
さて、ここからはFinancial Analyst DayにおけるCTOのMark Papermaster氏のプレゼンテーションを見てみたい。
まずZENコアであるが、こちらはFinFETをターゲットとしたプロセッサーであることが明言された。つまり、GlobalFoundriesの14LPEか14LPPが考えられることになる。

x86系の次世代コアであるZENの概要
どちらかというのは現時点では不明であるが、時期的には14LPPでも不思議ではない。またHigh-Bandwidth, Low Latency Cache Systemとは、K7以降で長らく採用されてきたExclusive Cache(Victim Cache)の構成を捨て、Inclusive Cacheを採用することのようだ。
またIPC(instructions per clock:クロック周波数あたりの実行命令数)に関しては、Excavatorコアと比較して40%の改善があるとしている。
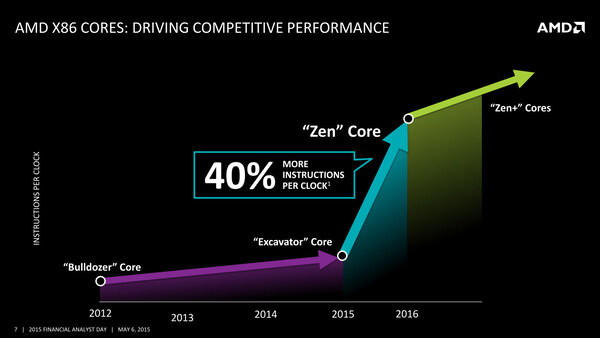
クロック周波数あたりの実行命令数は、Excavatorコアより40%向上しているという
実のところBulldozer~Piledriverの構成では、デコーダーは4命令/サイクルとしながらも2コアでデコーダーが共有だったので実質2命令/サイクル未満の効率だった。Steamrollerではデコーダーそのものは分離したものの、実質2命令/サイクル程度のデコーダーだったため性能面での改善はほとんどなかった。
ZenではSMT(Simultaneous Multithreading)をサポートする構成になっているため、最低でも3命令/サイクル。実際にはSMTをサポートするオーバーヘッドを考えると、4命令/サイクル程度のデコーダーと最低でも3つの整数ALU、Load/Storeユニットが2つ以上は含まれる、それなりに重厚なコアになるだろう。
もっともこれはかつてのK7~K10の世代では結構なエリアサイズになるだろうが、14nmプロセスならば大したエリアサイズにはならない。K12も4命令/サイクルのCPUになるとされているから、少なくともこれと同等以上の規模になることは間違いなさそうだ。
そのK12はまだ詳細は明らかにはされていない。ただ、以前ARMの関係者に「Cortex-A72はなぜ4命令のOut-of-Order構成にしなかったのか」と尋ねたところ「AMDやBroadcomはそういう構成だが、我々は3命令のままで性能を改善できる」という返事が返ってきたあたり、少なくとも4命令/サイクルの構成であることは間違いなさそうだ。

ARM系コアのK12は、まだ詳細が明らかになっていない
Kaveri-Refreshこと
Godavariを投入予定
Zenコアに関する発表はこの程度であるのだが、以下若干の余談をお届けしよう。Finantial Analyst Dayにあわせて、AMDはCarrizo/Carrizo-Lを発表した(関連記事)。
こちらはモバイル向けということで、おそらくA8-7410/A6-7310/A4-7210がCarrizo、E2-7110/E1-7010がCarrizo-Lと思われるが、これに続きCOMPUTEXの前後にKaveri-RefreshことGodavariを投入する予定だ。
いくつかのニュースサイトがすでにGodavariのラインナップを報じている(例えばWCCF Tech)が、AMD自身がこれの一部を公式に明らかにしている。
やはりFinancial Analyst DayにおけるCEOのLisa Su氏の“COMPUTING AND GRAPHICS BUSINESS”というスライドの一部で、今年のAMDの製品も競争力はまだ維持していると紹介しているのだが、ここで“Core i5と比較して40%以上グラフィックが高速”としている製品が、AMD A10-8700Pであった。

2015年のAMD製品は競争力を維持しているとCEOのLisa Su氏は語った

AMD A10-8700PはCore i5と比較して40%以上グラフィックが高速と記されている
GPUコアはRadeon R6 graphicsだそうで、微妙にWCCF Techのスライドとはあってないのだが、型番的にはGodavari世代のものであろう。
このスライドにはAMD FX-8800Pという製品もあるが、これはCarrizoベースのモバイル向けAPUのようで、3DMarkの結果からすると定格1.7GHz/最大2.1GHzであり、GPUのCU(Compute Unit)数は8つ(つまりシェーダ数は512)と思われる。これらの製品の詳細はCOMPUTEXのタイミングで明らかになると思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















