




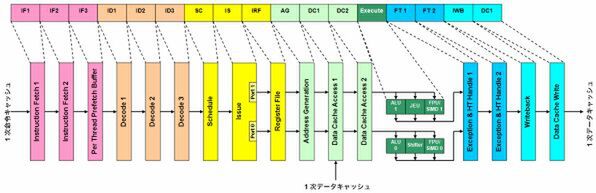
Atomのパイプライン構造図
アウトオブオーダー方式のパイプラインだと、実行ユニットの処理結果はそのまま「Re-Order Buffer」に戻されて、命令完了処理が行なわれる。しかしAtomはインオーダー方式なので、処理のあとには命令完了処理が必要になる。まず「FT1」「FT2」ステージは、実行結果による例外処理のハンドリングや、ステータスレジスタなどの更新をスレッドごとに行なう。
それに続く「IWB」は、更新されたRegister Fileを書き出す。レジスタ間演算の場合、Register Fileの書き出し先は別のレジスタになるので、このステージで処理は終了する。演算結果をメモリーに書き出す場合は、さらに「DC1」ステージに移る。これはデータキャッシュへの書き出しである。これでやっとパイプライン終了である。
このように、Atomのパイプラインステージ全体は、16ステージと結構長めである。ただし、アウトオブオーダー方式のパイプラインなら、AG/DC1/DC2ステージがパイプラインに組み込まれることはない※2。Executeに続く部分も、Re-Order Bufferの後処理としてパイプライン外で処理される。これらを考慮すると、実質的にはAtomも10段程度のパイプラインとなり、とりたてて長くはない。
※2 データキャッシュからのフェッチをスケジューラーの中で待つため。
タイトすぎて性能向上が困難
22nm世代では別アーキテクチャーに?
当時は鳴り物入りで登場したAtom。しかし前述のとおり、一応2命令同時実行の実行ユニットを持っているとは言え、実質は1命令/サイクルの処理しかできなかった。3命令同時実行のPentium Mと比較すれば3分の1で、4命令同時実行のCore 2以降と比べればさらに性能は劣る。ラフに言えば、2GHz駆動のAtomと600MHz駆動のPentium Mが大体同程度となるので、「2GHz」という数字に期待を持っていた消費者の期待を裏切ることになったのは、インテルが大々的にAtomをアピールしすぎた反動もあったのかもしれない。
前回でも触れたとおり、インテルの45nm SoCプロセスは期待された性能を実現できず、そのうえ32nmへの移行も難航した。そのため長くAtomは性能を改善できないままラインナップだけ増やすことになる。消費者から「Atomでは……」と言われるようになってしまったのは、可哀想でもある。本来はもう少しアグレッシブに性能改善してゆくはずだったのだが、そうしたプランも先送りになってしまった。
Atomの設計があまりにタイトすぎて、性能を上げるためには内部の大改造が必須となることも、性能向上が進まない要因であるだろう。2命令同時実行に最適化しきった関係で、例えば命令発行ポートと実行ユニットを追加して3命令同時実行にするのは、現在のAtomの設計では至難の業だ。また、命令フェッチの帯域が現状でぎりぎりなので、仮に3命令を発行しても性能は出そうにない。だからといってここにまで手をいれると消費電力がぐわっと増えることは目に見えている。
インテルは22nm世代のAtomである「Silvermont」で、新アーキテクチャーを導入すると公表している。これが現行のインオーダー方式を継承したものか、それともAMDの「Bobcat」(AMD E/CのCPUコア)のようにアウトオブオーダーを使うものか、まだ判然としない。時間的に言えば、2008年あたりからもう一度フルスクラッチで新CPUの設計を始めても、Silvermontには十分間に合う。筆者は今回解説したパイプラインは現行Atomまでで、Silvermontはアウトオブオーダーを採用するのではないかと考えている。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ








































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















