




電気食いのデコード段を省電力化した
Loop Stream Detector
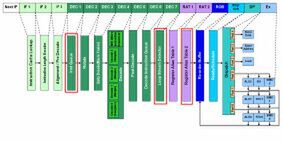
図1 Nehalemの内部構造図。赤枠内がMeromからの主な変更部分
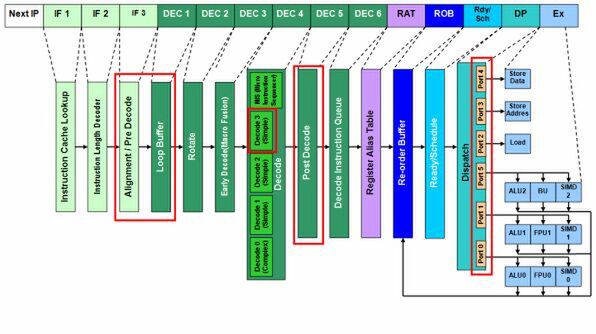
図2 Meromの内部構造図
大きな変更のあったNehalem世代ではあるが、そのパイプラインを見てみると、基本的にはMeromからの小変更であることがわかる。
まずMeromでは、「Loop Buffer」という部分でx86命令を18命令分格納し、ここで繰り返し処理を検出すると、繰り返し中はフェッチを止める、という処理を行なっていた。対するNehalemでは、これをデコードの最後に移動させ、名称も「Loop Stream Detector」(LSD)に変更した。LSDではμOpベースで28命令分を格納し、この範囲内で繰り返し処理があった場合は「IF1」~「DEC 6」を止めて、LSDから「RAT1」以降にμOpを供給することになる。
この変更のメリットは明白で、繰り返し処理が検出できた場合はフェッチのみならず、デコード段のほとんどの処理も停止できることだ。一般的に、CPUのパイプラインの中で比較的消費電力が大きいのがデコードである。特にx86の場合は、かなり複雑になってしまったx86命令の解釈に、結構な電力を費やしている。定量的な数字ではないのだが、以前インテルのアーキテクトに聞いた話では、インテルプロセッサーの場合平均して(CPUコア全体の)4割程度の消費電力を、デコード段で費やしているという。これをクロックゲーティング技術で止めることができれば、当然消費電力を引き下げることが可能になる。つまりNehalemでの変更は、フェッチのみが止まるCore 2に比べて、ずっと効果的である。
ただしMeromの時には、「IF3」のアライメント/プリデコードの結果を、いったんDEC 1のLoop Bufferで受けてから、「DEC 2」のローテートにまわしていた。NehalemではこれをLSDとして「DEC 7」に移したので、デコード段の頭にバッファはいらない……というわけにはいかなかったようだ。DEC 1には新たに「Inst Queue」が追加されている。Inst Queueはそれほど多くの命令を保持するものではなく、x86命令を8つ程度保持するもののようだ。
省電力増につながる帯域幅の強化は見送り
Nehalemでの次なる変更が、「ハイパースレッディング・テクノロジー」(HT)である。ご承知のとおり、HTはNetBurstアーキテクチャーで初めて実装されたもので、NetBurstアーキテクチャーの初代である「Willamette」コアの「Pentium 4」から、すでに実装されていた。細かい仕組みはいずれNetBurstの説明の際に譲るが、重要なのは「実行ユニットやスケジューラーそのものは2つのスレッドで共用するが、レジスタに関してはスレッドごとに分ける」という実装が必要な点だ。
Nehalemの場合、このレジスタの割り付けがパイプライン1ステージ分では完了しなかったようで、「Register Alias Table」(RAT)のステージが1段増やされて、2段構成になっているようだ。
こうしたインオーダー部の強化がなされた一方、アウトオブオーダー部は意外にも大きな変更がない。細かい数字で言えば、以下のような変更はある。
- リオーダバッファの強化。96エントリ→128エントリ
- Ready/Scheduleの強化。32エントリ→36エントリ
これらにより、実行待機状態にできる命令数そのものは増えているのだが、それを処理すべき実行ユニットの方は、特に変化がないままとなっている。そもそもフェッチ部が相変わらず128bit幅(16byte/サイクル)でしか命令フェッチをしていないし、これにあわせて1次データキャッシュも128bit幅で接続されているため、IPCの大幅な改善は難しい。もっともこれに関しては、インテルは承知のうえだったようだ。
インテルは次のSandy Bridgeの世代で、256bit幅のSIMDであるAVX命令を導入する。そのタイミングでCPUパイプラインと1次キャッシュの帯域幅を、256bit(32byte/サイクル)に拡張することを、Nehalemの時点で決定していたようだ。逆にNehalemの世代では、帯域幅を256bit化してもそれを使い切るのは難しいうえ、むしろ256bit化することで消費電力が増えることを嫌ったという趣旨の発言を、NehalemのCPUアーキテクトの1人であるボブ・ヴァレンティン(Bob Valentine)氏に聞いたことがある。
一方で、65nm世代でいち早く1次キャッシュからCPUパイプラインへの帯域幅に256bit化してしまったAMDの「Barcelona」は、その代償として恐ろしいほどの消費電力増に悩まされた。時系列的に言えば、Barcelonaが世間に登場するはるか以前にNehalemは設計を終了しているはずなので、「Barcelonaの状況を見て256bit化を後送りにした」わけではない。しかし、恐らくNehalem設計チームはBarcelonaの状況を見て、「ああ、やっぱり」と考えたのではないかと思う。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ












の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















