



ロードマップでわかる!当世プロセッサー事情 第869回
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度
2026年03月30日 12時00分更新


インテルはこれまでもDNN(Deep Neural Network : 深層学習)プロセッサーをいくつか試作している。直近の発表は2022年のVLSI シンポジウムではIntel 4を利用したCNC(Compute Near LLC)の実装である。
この時の仕組みは、LLCのすぐそばにCompute Unitを置くことで、疑似的にPIM(Processor In Memory)に近い効果を得られるようにするというものであった。ただこれは現在のPIMにも共通する話だが、以下の制約が付いて回ることになる。
- SRAMとCompute Unitを同一プロセスで構築すると、微細化してもSRAMのサイズが減らないので効率が悪くなる。だからといって大きめのプロセスを使うと、計算密度が上がらない。
- DRAMと組み合わせるのはComputationの側に制約が大きい。
- SRAMにしてもDRAMにしても、別ダイにしてチップレットなどを使うのは、結局データ移動の消費電力が大きくなるから効率的ではない。
解決案はあって、ComputationとSRAMを別々のダイで製造し、3D実装すればいい。これを実行してしまったのが、インテルがISSCC 2026のPaper 10.6で"A Hybrid-Bonded 12.1 TOPS/mm 56-Core DNN Processor with 2.5Tb/s/mm2 3D Network on Chip"として発表した内容になる。
ちなみにインテルは今回Paper 30.9で"A 147TOPS/W, 250TOPS/mm2, Fully Synthesizable, Digital Compute-in-Memory Accelerator Supporting INT8×INT8 with Zero-Point Quantization in Intel 18A Technology"という論文も発表しており、Intel 18Aで製造しているところは似ているのだが、構造もチップも異なるので、並行して複数のDNNプロセッサーの研究をしていたわけだ。
PIMの課題を3D積層で解決
DNNプロセッサー研究の変遷
さてこちらの発表だが、タイトルの通り56コアのDNNプロセッサーであるが、その設計動機と具体的な構造が下の画像である。
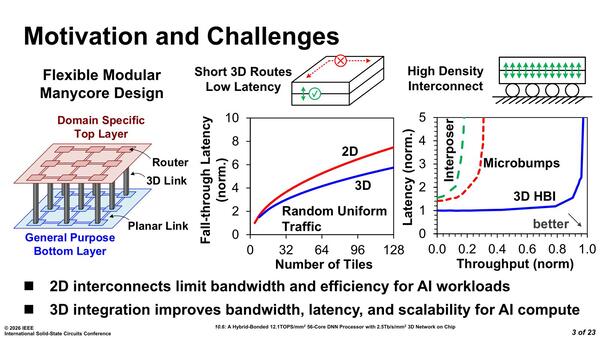
DNNプロセッサーの設計動機。同じ規模のSRAMなり、なんなりを実装するのであれば、3D化する方がレイテンシーが小さくなるというのは、特にPIMにおいては重要なポイントとなる
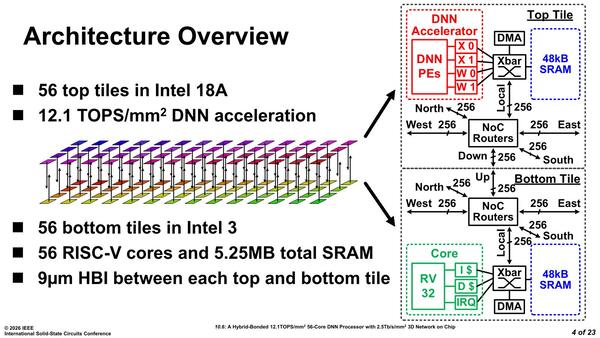
具体的な構造。DNN PEとRISC-Vのコアがどちらも56個あるので、その意味では112コアと称するのが正しい気もするのだが、DNN PEはあくまでもRISC-Vコアのアクセラレーターという位置付けなのかもしれない。ただDNN PE同士も相互接続している時点で少し違う気もする
RISC-Vコアの方は、2017年のVLSIシンポジウムで発表されたコアを若干手直ししたRV32(32bit RISC-V)のもので、DNN PEはインテルの独自設計によるものである。
RISC-VコアとDNN PEはルーター経由で接続されており、またどちらにも48KBのローカルSRAMが接続されている。つまり1コア相当あたりで96KB、これが56コアで5376KBとなり、5.25MB SRAMになる。DNN PEはIntel 18A、RISC-VはIntel 3で製造され、間は9μmピッチのHybrid Bondingで接続されている。これはFoveros Direct 3Dベースであろう。
下の画像がNOCの構造である。この図では上下左右方向のメッシュしか見えていないが、1つ上の画像でNoCを確認すると、ローカル接続以外にNorth/South/East/WestとUpないしDownの5方向のリンクが用意されており、この図で言うとTop TileやBot(Bottom) Tileの奥行き方向もちゃんと接続されている3次元接続のメッシュ構造だ。
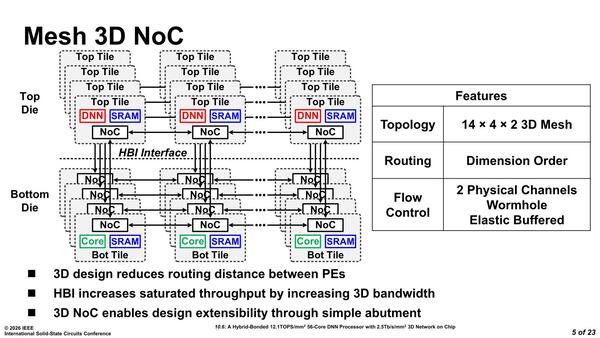
NOCの構造。56コアを7×8ではなく14×4という構成にした理由を知りたいところである。Hop数で言えば、最長のケースではむしろ増える(7×8では14Hopで済むが、14×4なら17Hopになる)一方、あまりメリットが思いつかない
ルーターの構造は下の画像のとおり。6方向のメッシュではあるが、バス幅は64bitと結構大きいためか、中央にクロスバーを入れているのは妥当な構成だと思える。
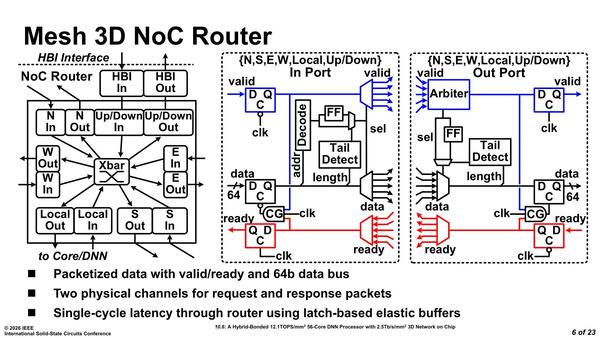
パケットサイズは64bitではなく64Byteの模様(64Bと書いてほしかった)。これはCache Lineのサイズに合わせたとのこと。なので1パケットの転送には8サイクルかかる計算になる
Tail Detect(自身がメッシュの最後端であればそれ以上先にパケットを転送しない)制御がOut Portに入っているのはわかるのだが、In Port側にも入っているのが今1つ理解しにくい。単純に末端の先からはデータが来ないので、In Portの入力を無効化するだけかもしれない。なお、この図、In PortとOut Portが逆ではなかろうか? と思うのだが、論文の図も一緒なので間違いではなさそうだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























