



Snowflakeイベントで語られた、手痛い教訓と全社データ活用の歩み
請求書には“想定の50倍”のコストが… デンソーのデータ基盤チームがハマった落とし穴
2025年09月12日 10時30分更新

Snowflakeのアカウントの請求書を見たデータ活用基盤の担当者。そこには、目玉が飛び出るほどの金額が記載されており、原因を調べると想定の50倍を超える「データ転送(エグレス)」が発生していた――。
2025年9月11日、12日に開催された「SNOWFLAKE WORLD TOUR TOKYO 2025」。デンソーによるセッションでは、冒頭の「通信コスト急増事件」の当事者である近藤忠優氏が登壇。同社の全社データ活用の歩みに加えて、事例披露の場では珍しい失敗談と再発防止策、そこから得られた手痛い教訓までが共有された。

デンソー ITデジタル本部 デジタル活用推進部 近藤忠優氏
今では5000人超の社員が利用する“データ活用基盤”
まずは、デンソーが取り組むデータ活用の推進とそれを支える基盤整備について語られた。
デンソーは、昨年創立75周年を迎えた、世界の自動車メーカーに部品やシステムを供給するサプライヤー企業である。日本を代表するサプライヤーとして、現在は、電動化やコネクテッドカー、先進安全・自動運転の領域に注力しており、ファクトリー・オートメーションや農業などの非車載事業も展開する。
そんな同社がデータ活用において掲げるビジョンが、「あらゆる職場で、当たり前に、データ利活用で意思決定している会社になること」だ。このビジョンの実現に向け、近藤氏が所属する「デジタル活用推進部」は、データを活用できる状態にするための道具や環境、ルールの整備を担っている。そして、特に注力してきたのが「データ活用基盤」である。
かつてのデンソーは、各部門やプロジェクトがデータ基盤の開発から保守運用までを独自に手掛けていた。そこでデジタル活用推進部が、データ基盤の開発・運用を引き受けることで、データ分析やその業務適用に専念できる環境を築いている。
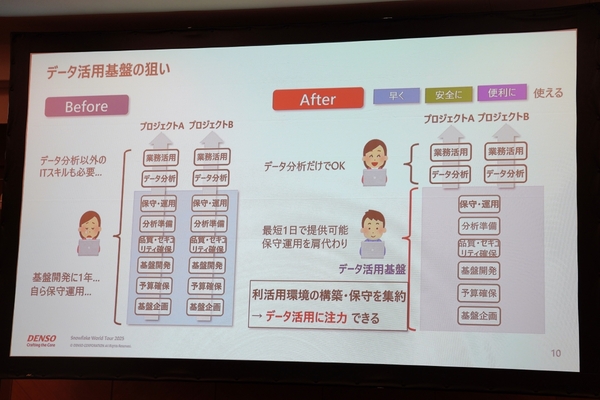
データ活用基盤の狙い
このデータ活用基盤はSnowflakeを軸に構築され、用途・ユーザーレベルにあわせて3つの基盤を全社展開している。最初に展開されたのが、全社管理のデータレイクである「BDAP」だ。基幹システムのデータを吸い上げており、BIツールから接続するだけで全社の業務を可視化できる。
さらに、社員のニーズに応える形で、部門やプロジェクトごとに構築するデータレイクを追加した。ひとつが、独自の業務データとBDAPのデータを組み合わせて、部門内の業務効率化を推進するための「CDAP」だ。もうひとつが、車両データなど大規模データを分析するプロジェクト向けに高性能な計算環境をセットで提供する「Sandshrew」である。
2020年からデータ活用基盤の全社展開が始まったが、今では総ユーザー数は5699人に上り、国内外17社のグループ会社が利用し、取り扱いデータ量は210TBに達している。
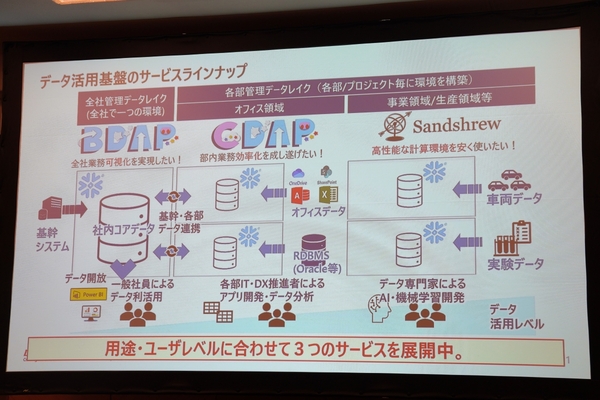
データ活用基盤のラインアップ
データ活用基盤に、Snowflakeを選択したのは、「パフォーマンス」と「コスト」面で優れていたからだ。最も大規模な車両データの分析を想定したベンチマークにて、Snowflakeがトップクラスのパフォーマンスを発揮。加えて、局所負荷がかかる分析業務に対して、無駄のないリソース管理や料金体系だった点も評価している。

Snowflakeを採用した理由
想定の50倍を超えるデータ転送コスト、原因はシンプルだった
ここからは本題となる「通信コスト急増事件」の詳細だ。
まず事件の背景には、デンソーが、マルチクラウドで多様なデータ基盤を利用することを前提とした環境を模索し始めたことがある。ここまでSnowflakeを軸にデータ活用基盤を整備し、社内浸透も達成してきた。
一方で、領域ごとに、業務特性や独自のニーズから、他のデータ基盤を導入するケースも一定数あったという。さらに、領域横断のデータ連携の要望も増えてきたことから、Snowflakeと他のデータ基盤との連携を検証することになった。近藤氏が担当したのが「Microsoft Fabric(以下Fabric)」とのデータ連携だ。

事件の背景
近藤氏がその検証作業を進めていたある日、Snowflakeから請求書が届く。すると、検証用アカウントに対して、途方もない金額が請求されていた。「社内で最大規模のプロジェクトでも、この金額の4分の1から3分の1程度。『えっ、ナニコレ!?』となったのを、今でも鮮明に覚えている」(近藤氏)
一旦落ち着き、請求明細をみてみると「データ転送」のコストが突出していた。さらには、検証中のFabric環境へデータ転送が繰り返されていたことが分かり、犯人が近藤氏であることが確定した。そのデータ転送量は、1か月で実に「520TB」に達していた。なお、Snowflakeでは、AWSやAzure、Google Cloudから構築するリージョンを選択でき、リージョン間やクラウドプラットフォーム間でデータ転送する際に、容量に応じて移動元にコストが発生する。
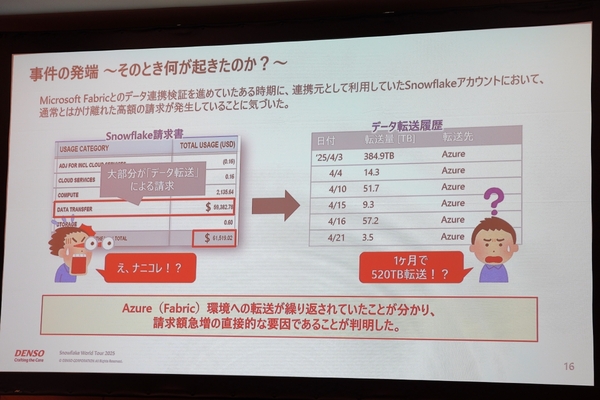
Snowflakeの請求書を見て目玉が飛び出た近藤氏
たしかに近藤氏は、データ連携の検証作業の中で、Snowflake上のテーブルをFabricにコピーしていた。ただし、テーブルの容量は「10TB」と把握しており、「当然、転送されるのも10TBで、この程度なら安心」(近藤氏)と考えていた。
しかし、実際に転送されたのは、その想定の50倍以上にあたる520TBである。なぜ予想外のデータ転送量が発生したのか。
原因はシンプルで、Snowflake上のテーブルデータは圧縮されているが、Fabricへの転送時にはそのデータを解凍して送る仕様だったからだ。「発覚時はそれどころではなかったが、Snowflakeはこんなにも高圧縮で保管していて、ストレージコストを抑えているのかと感動した」と近藤氏。
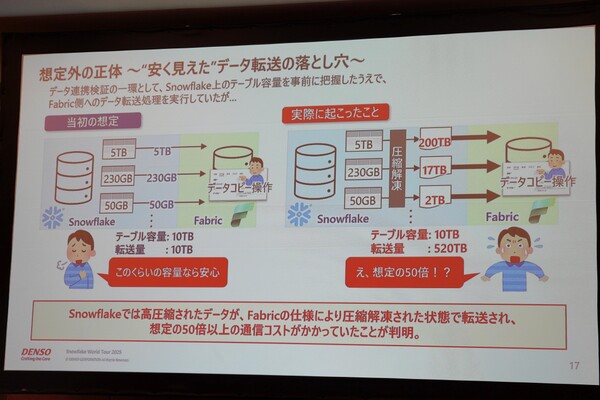
近藤氏がはまったデータ転送の落とし穴
そして、二度と同じような事件が起こさないよう、再発防止策を講じることとなる。



