




今回は少し毛色を変え、前回と同じくShort Courseの中からSK HynixのSoo Gil Kim博士(Fellow&VP, SOM&ACiM based on emerging memory, component research for memory technologies)による"Current Landscape and Future Outlook of Emerging Memory Technologies"というセッションの内容をご紹介したい。
微細化にも限界が見えてきたメモリーの現状
半導体市場が次第に拡大しているということはメモリーの市場もまた広がっているという話ではある。
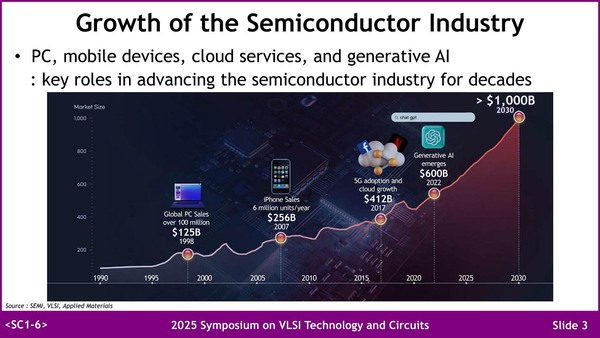
一時期はAIブームがそろそろ天井という意見もあったが、最近はまた天井が抜けた論が多い。ちなみに筆者はさすがにそろそろ限界では? と思っている(理由:主に電力供給がひっ迫し始めているため)。本当に2030年に$1000B(一兆ドル)を超えるのだろうか?
メモリー市場の拡大というのは、容量と帯域の両方へのニーズが高まるという意味でもあり、これに向けてプロセス微細化と電圧低下を利用して対応してきた、というのがこれまでのDRAM業界である。
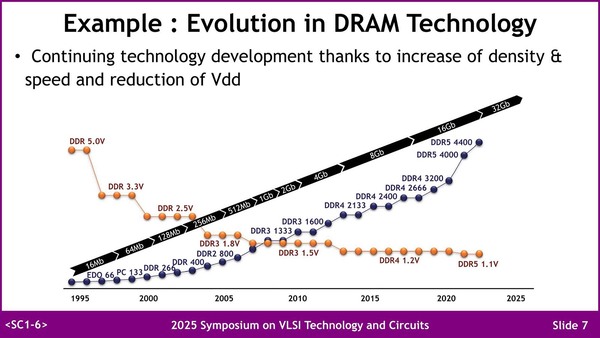
よくここまで微細化を進めたものだという気はする
ただDRAM/NANDに共通する話だが、そろそろ微細化にも限界が見えてきた感は否めない。DRAMの方はそろそろ現在の6F(Feature size)2の限界に来てるし、NANDの方は3Dになってからプロセスそのものは20nm台で、それを高層化する形で容量を増やしているからだ。
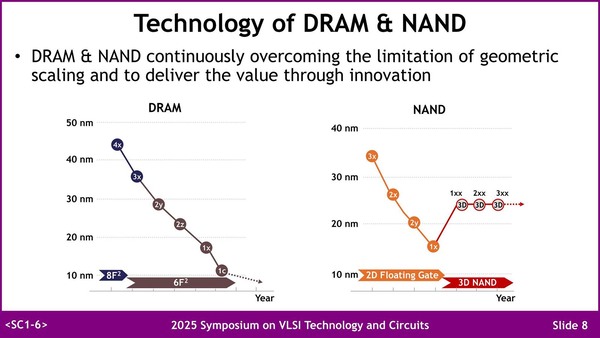
微細化にも限界が見えてきた
まずDRAMに関しては現在研究がなされているのが4F2構造と、3D積層である。4F2の方はずいぶん昔から話題というか研究テーマとして挙げられており、2010年代には何度も学会に発表が成されているが、信頼性の問題などから現時点でも量産には至っていない。
一方3D DRAMは比較的最近話題になっているもので、SiベースのトランジスタをIGZOベースに置き換えるなどすることで3D構造を構築する目途が立ったとしている。ただあくまでまだ目途どまりであり、量産に持ち込めるのは実際には2030年代になるだろうといった見方もある。
一方のNAND Flashの方も、現在は300あまりのNAND層を一発で構築してきたが、そろそろ一気に製造するのは難しくなってきた。そこで、複数枚のNAND層を貼り合わせる方向に舵を切るとともに、従来よりも低コストで実現できる張り合わせ方法の検討を始めている。
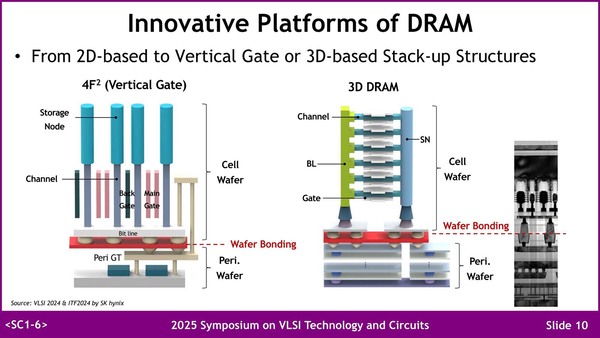
IGZO(InGaZnO)を使ったDRAM構造は、2024年12月にKioxiaが論文を発表して話題を集めていたりする

すでにNAND層とコントローラー層を別々に製造して貼り合わせることは行なわれているほか、中国YMTCはXtackingと呼ばれるNAND層の張り合わせ技術を採用している
AI向けのメモリーは容量が課題
NANDよりも高速でDRAMよりも低コストなメモリーが必要になる
さてここまでは枕の話であって、本題はここから。ここまでは従来型のメモリーの話であるが、AI向けになるとまた話が違う、という議論である。
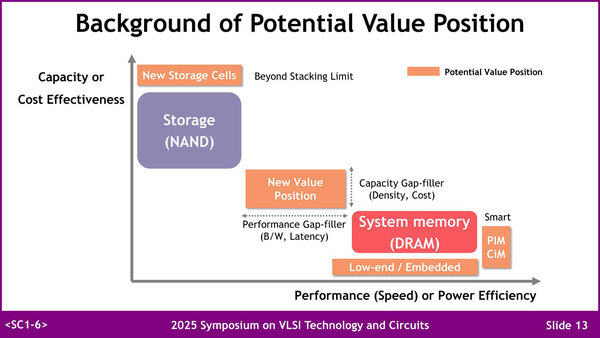
最近SanDiskがHBF(High Bandwidth Flash)と呼ばれる、HBMのDRAMをFlashに置き換えた規格を定めることを発表したが、これなどはまさしくこのNew Value Positionに向いた構成と言えるだろう
HBM3/3e世代が最大12層で1層あたり3GBくらいなので1スタックあたり36GBになり、例えばAMDのInstinct MI400はこれを12スタック積んでシステムメモリーを432GBとしているが、言うまでもなくこれは非常に高価な選択である。
別のアイディアはSRAMを大量に積むことだが、CelebrasのWSEのようにウェハーまるごとを使っても40GB程度であり、外部にMemoryXと呼ばれるメモリーサーバー(というのだろうか?)を設け、これをSwarmXという専用のネットワークでつなぐとかいう騒ぎになる。
結局のところSambaNovaのSC40Lのように、HBMとは別にDDR5を外部に接続するわけだが、それでも容量は1.5TBほどでしかない。現在のLLMには十分な容量だが、この先もこれで足りるとは誰にも断言できない。この調子でLLMのパラメーター数が増えていくと、いずれはこれでも足りなくなることが見て取れる。そこで、NANDよりも高速でDRAMよりも低コストなメモリーが必要、という話になる。
この新しいポジション向けの選択肢として考えられるものにはいくつかあって、HBM以外にPNM/PIM/CiMといった構成が考えられる。
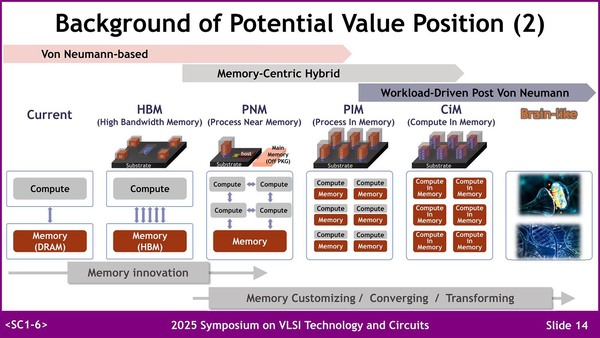
CiMは、演算器の数に比例するだけのメモリー量しか確保できないので、必然的にメモリーを増やす=演算器を増やすとなり、逆に高度な演算器を実装しにくいという弊害がある。もちろんConvolution程度「だけ」でいいならそこまで難しくはないだろう
PNMの例としては連載673回に紹介したインテルの"An 8-core RISC-V Processor with Compute near Last Level Cache in Intel 4 CMOS"、PIMの例としてはSamsungのPIM(連載606回および連載636回)がそれぞれいい例だろう。
CiMはこの連載で取り上げたことはないのだが、メモリーセルそのものに演算機能を持たす(演算器にメモリーの仕事もさせる)例としては、Connex Technologyが2006年に発表したCA1024に搭載されたArray Processorが、AIプロセッサーではないがこれに該当するだろう。
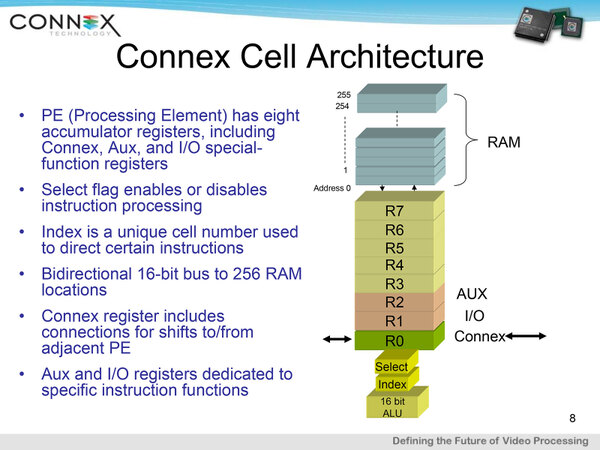
Connex Technologyの独自の構造。個々の演算器と256bitのメモリーが1つのセルを構成。全体では32×32で1024個のセルを持つ。同社は2007年にBrightScale, Inc.に社名変更したが、その後の行方は不明
HBMについてはもう説明は要らないだろうが、PNMの例として出てきたのがCXLだったのには少し驚いた。

もうHBM4のサンプル出荷が始まっており、こちらは最大16層の積層が可能。現在は1層あたり3GBだが、この先に4GBは一応視野に入っている模様で、この場合1スタックあたり最大64GBの容量となる
といってもこれはCXLメモリーという意味ではなく、CXLのアクセラレーターで、内部にメモリーとAIプロセッサーが搭載されているというものだ(写真左下の"Application og CXL memory to PNM)。

連載668回で説明したSK HynixのGDDR6-AiMにCXLのI/Fをつないでホストから制御しやすくしたものと思われる
これはSK HynixのGDDR6-AiMをベースとしたものだが、外部メモリーとしてCXL経由でホストメモリーを利用できるようにするという実装例だ。そしてPIMの方はGDDR6-AiMがそのまま出てきた。
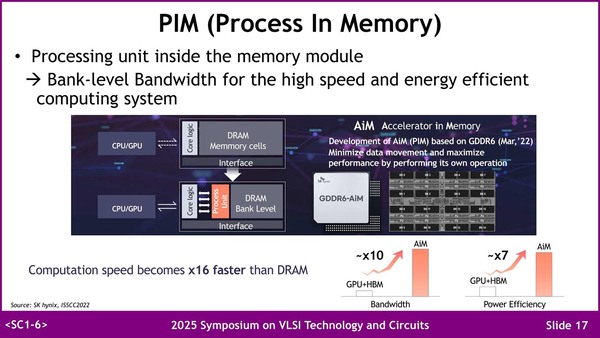
SamsungのPIMもそうだが、DRAMチップを2分割し、半分のエリアにはDRAMセルの代わりに演算器を格納することで、ローカルメモリーへのアクセスを高速化するという試み。局所的なデータアクセスだけで済む演算は滅法早い
ただこれらのメモリーは(CiMを除くと)基本現在のDRAMの延長にあるわけだが、もっと容量を増やしつつコストを下げるためには、別種のメモリー技術が有望、という話になっている。ここではPCM/SOMとSTT-MRAM、FRAM、そしてACiMの4つが紹介された。

もっと容量を増やしつつコストを下げるためには、別種のメモリー技術が有望。ちなみにSK HynixはSOM(Selector Only Memory)をPCM(Phase Change Memory)の延長として扱っている。それはともかくACiMはやや違う気がする
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")










































