




SoICは2.5DのUCIeと比較して
2~3桁高い配線密度を実現できる
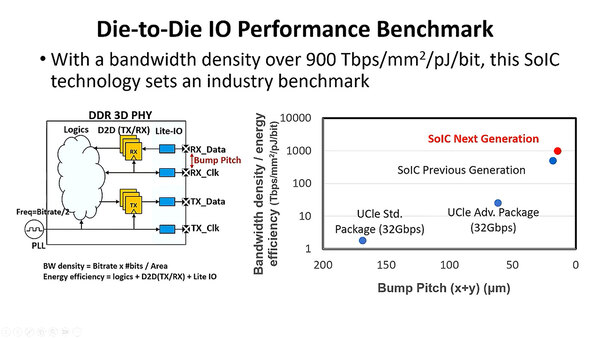
発表ではこのあとSanity Check(どこまで正常に動作しているか)の結果なども示されたが、これは割愛して最後にベンチマーク結果を説明しよう。これは実際にどの程度の性能を出せるか比較したもので、SoICは2.5DのUCIeと比較して2~3桁高い配線密度を実現できる、としている。
UCIeそのものは別に3Dもサポートされているのだが、ここで出ているStd PackageとAdvanced Packageはシリコンインターポーザー前提の2.5Dの接続のものである
この最後の話についてだけ、もう少し解説しておきたい。もともとのUCIeはシリコンインターポーザーを前提とした2.5Dでの接続のみだったが、2024年8月にリリースされたRevision 2.0でUCIe-3Dと呼ばれるSoICタイプの接続にも対応するようになっている。
スペックからこの3つのパッケージの仕様を抜き出してまとめたのが下表である。
| の3つのパッケージの仕様 | ||||||
|---|---|---|---|---|---|---|
| Standard Package | Advanced Package | UCIe-3D | ||||
| Supported speeds (per Lane) |
4,8,12,16,24,32GT/s | up to 4GT/s | ||||
| Bump Pitch | 100μm~130μm | 25μm~55μm | < 10μm(Optimized) 10~25μm(Functional) |
|||
| Channel reach | 10mm(short) 25mm(long) |
2mm | 3D Vertical | |||
| BER | 1e-27 (<= 8 GT/s) 1e-15 (>= 12 GT/s) |
1e-27 (<= 8 GT/s) 1e-15 (>= 12 GT/s) |
1e-27 | |||
2.5Dタイプでは最大32GT/sまでの接続が可能なのに対し、UCIe-3Dは最大でも4GT/sと控えめなのは、なにしろ配線数を猛烈に増やせるからである。Standard/Advanced Packageの場合、配線はx16を基本にx32/x64あたりまでが想定されているが、UCIe-3Dは例えばx4096なども可能であり、信号速度を上げるとむしろ消費電力が上がってしまうので、信号速度は控え目にして、その分配線数を増やした方が得策である。
そもそも上の画像を見ると、SoICの方は簡単な送受信バッファを用意しているだけで、UCIeのI/Fを使っていないのがわかるかと思う。UCIeは基本的に外部バスの延長というか、間にプロトコル変換が入る形で互換性を高めるような工夫がなされているが、UCIeのこの例は内部バスをそのまま延長して接続するような構造である。
連載659回でAMDの3D V-Cacheの配線を説明し、これを元にした内部構造の推定もご説明したが、SoICを利用するとL3用SRAMの内部配線をそのまま延長させられる。
これが可能なのは、3次元方向の接続なので、配線距離が1mmにも満たないからというのが大きい。そして配線距離が短いということは、信号駆動のための電力も非常に抑えられたものとなる。実際PHYといってもESD保護用のクランプと、そのあと信号を正規化するアイソレーション回路だけで済んでいる。
ところがUCIeの場合はもっと配線距離が長くなるから、ちゃんとドライバーも必要だし、それだけ消費電力が増えることになる。UCIeを使わずに独自規格で接続してもこのあたりは変わらない。
水平方向の接続に内部バスの信号をそのまま出すことは不可能か? というと、そうとは限らない。その実例がSapphire RapidsやGranite Rapids、そしてSierra Forestなどで、これらはいずれもCPUコア同士をつなぐリングバスを外部まで引っ張っている。
ただ結果として例えばSapphire Rapidsは疑似的にであるが内部バスの長さが南北・東西方向ともに40mmもの長さになってしまっている。これだけの長さを引き回すと、当然信号の劣化が激しいから、これを補うためにバッファをあちこちに入れたり(これは通信のレイテンシー増加につながる)、信号の電圧を上げたり(これは消費電力増加につながる)という、好ましくない副作用を発生することになる。
チップレットの原理的な欠点は、チップの数が増えると水平方向の配線がどんどん長くなることで、これを避ける一番スマートな方法が縦方向の積層というわけだ。TSMCが次世代SoICで900Tbps/mm2/pJ/bitという高い高密度配線を実現できたというのは、要するに3D積層すると配線長が最小に抑えられることが大きい。
だからといってむやみやたらになんでもかんでも3D積層というわけに行かないのが目下の問題ではあるのだが、1つの方向性を明確に示したものとは言えるだろう。
この連載の記事
-
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 - この連載の一覧へ

















の1台が今ならオトク!")




























")













