




配線層はN3世代のものを踏襲するも
SOICへの親和性がさらに高まる
配線に関しては、こちらも詳細は明らかにされなかったが、MoL(Middle of Line:M4~M14位の配線層)の抵抗値と寄生容量の積を55%削減し、これにより動作周波数にして6%の改善が実現したとしている。
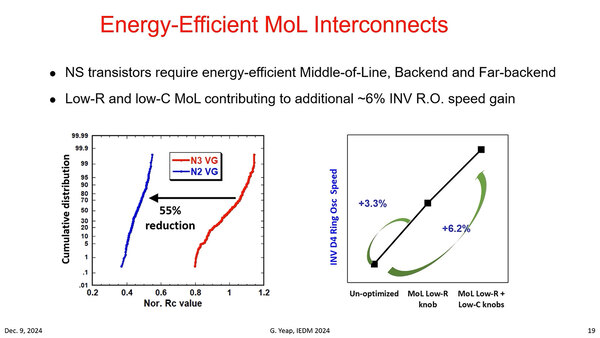
抵抗と寄生容量でRC回路が構成され、このRC回路の時定数が律速条件になるという話は連載464回で説明した。つまりRCの積を55%削減したら、時定数が6%減ったということである
また、M1/M2はN3/N3Eと比較して全体の寄生容量を10%減らせたとしている。ただ配線層、基本的にはN3世代のものを踏襲しているようだ。加えて垂直方向の接続を行なうVIAに関しても、抵抗値で25%、RCの積で20%の削減を実現したとする。
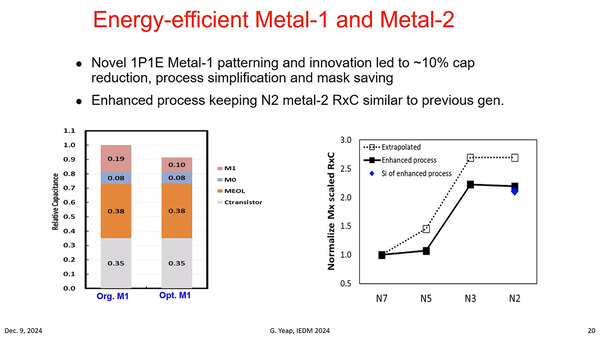
M1の寄生容量がおよそ半分になったことで、全体としては10%削減になった

VIAも、抵抗値で25%、RCの積で20%の削減。ただし、これがどういう配線構造や材料を利用したのかは未公開のまま。193i 1P/1E(One Patterning/One Etching)なので、ArFのシングルパターニングで実現しているようだ
その配線だが、N2では3次元集積化技術SOICへの親和性がさらに高まったらしい。まず従来だとアルミだったバックエンドの配線はすべて銅ベースになり、SOICを簡単に実現できるようになった。配線も最小で4.5μmにすることが可能になったとする。

N2ではSOICへの親和性がさらに高まった。Zen 3の3D V-Cacheの場合、17μmピッチだったことを連載651回で説明している
ただ以前Zen 3の3D V-Cacheの時にはKOZ(Keep Out Zone:熱などによる歪の影響を避けるために、なにも配線しない領域)が6.2μm×6.3μmとけっこう大きかったのだが、そもそもの配線ピッチが4.5μmまで縮小すると、KOZはどのくらいになるのだろうか? というのはやや疑問だ。
配線全体の断面が下の画像だ。配線層の総数が18層なのがこれでわかった。ちなみにN3では確か16層(M0~M15)だったので、MOLが2層増えたかたちになる。

TSMCはN2にBSPDNを持ち込まないので、配線と電源供給は同じく上層からになる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























