



ロードマップでわかる!当世プロセッサー事情 第803回
トランジスタの当面の目標は電圧を0.3V未満に抑えつつ動作効率を5倍以上に引き上げること IEDM 2024レポート
2024年12月23日 12時00分更新

画期的なプロセス技術をインテルが次々と開発
性能を上げるための最初の手段がマルチコア化であるが、トータルの性能は上がってもレイテンシー、別の言い方をすればシングルスレッド性能はむしろ落ちることになる。
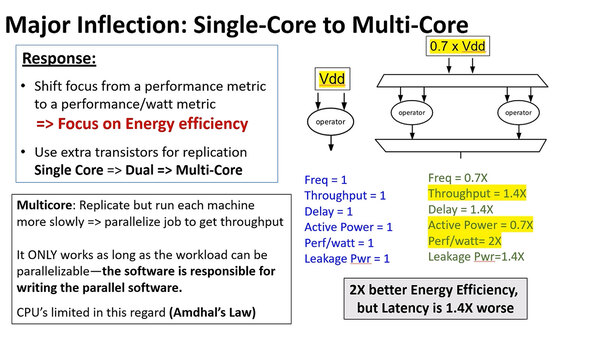
動作周波数を上げる手段がマルチコア化。左の問題の一番下にもあるが、コア数を無暗に増やしても性能が頭打ちになるというアムダールの法則も効いてくる
当然トランジスタそのものの改良も続けられてきた。まずは90nm世代で歪シリコンが導入されたが、45nm世代ではHKMG(High-K Metal Gate)、22nm世代ではFinFETが導入された。

歪シリコンは電荷の移動速度を向上させる手段だったが、同時に莫大なリーク電流が発生してしまったため、インテルはPentium 4の動作周波数の5GHz到達を断念し、Socket 478からLGA775に急遽切り替えることで電源供給の安定化を図り、また続く予定だったTejasをキャンセルした。連載118回でこのあたりの話をしている
このFinFETの導入までは、間違いなくインテルがプロセス技術の最先端を走っていた。ちなみに講演ではこの後、HKMGとFinFETがいかに画期的な技術であったかのスライドが2枚ほど続くが、これはこれまでも説明してきた話なので割愛する。
これに続くものがGAA(Gate All Around)で、Ribbon FETという名称で今まさに開発をしている最中であるが、逆に最中過ぎて細かい情報を出せないためか、Intel 20A/18Aに関する言及はすっぱり落ちている。Intel 20Aのキャンセルの話などはいろいろ生々しすぎるためだろう。おそらくあと10年くらいすれば、「なぜIntel 20Aがダメだったのか」という振り返りの話がでてくるかもしれない。
ここから今後のプロセスに関する話となる。まずトランジスタの構造で言えば、Ribbon FETの先にStacked Ribbon FETがCFETとして利用されるという見通しを示した。

以前のCFETはRibbon FETとはまったく違う構造がしばしば議論されてきたが、最終的にはRibbon FETを重ねる方向になっている模様
連載236回で、CMOS(Complementary Metal Oxide Semiconductor)はP型とN型の2種類のトランジスタを組み合わせて構成される(よってComplementary:相補型という呼び方をされる)という話をしたが、プレナー型にしてもFinFETにしても、NMOSとPMOSを平面的に2つ並べて間を配線でつなぐことになるので、トランジスタ2個分の面積を必要とする。
ところが積層すると、面積がトランジスタ1個分で済むので、トランジスタの密度が倍になることになる(実際はそこまで向上せず、1.5倍程度だが)。ただ「トランジスタの密度向上にともない、効果的な放熱手段が必要」と書いてあるように、単純に重ねて終わりという話ではない。そもそも重ねるのも大変だし、間の配線の構築も必要であることを考えると、決して難易度は低くない。
これが先程触れたサブスレッショルド領域での問題。速度以外に、ノイズなどの影響を極めて受けやすくなるので、これをどう回避するかも問題である
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ







































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")



























