



ロードマップでわかる!当世プロセッサー事情 第792回
大型言語モデルに全振りしたSambaNovaのAIプロセッサーSC40L Hot Chips 2024で注目を浴びたオモシロCPU
2024年10月07日 12時00分更新

HBMを搭載したSN40L
On ChipとOff Chipの速度差を減らすためにメモリーを3階層にする
現在SambaNovaはSN10に代わり、このSN30をメインに据えてサービスを提供している。先程ALCFの説明スライドで示したように、ALCFにはSN10ベースのシステムに加えてSN30ベースのものが導入されている。また2023年3月には理研への導入が発表されたし、他にもいくつかの企業や研究所がSN30をベースとしたシステムを導入している。2023年11月には東京オフィスも開設された。
また同社は2020年までにシード200万ドル、シリーズAで合計6330万ドル、シリーズBで1億5000万ドルと合計2億1530万ドルの資金をファンドなどから調達していたが、2020年2月には2億5000万ドルをシリーズCで、2021年4月には6億7600万ドルをシリーズDでそれぞれ調達している。このシリーズC/Dの資金で開発されたのがSN20/SN30と、今回説明するSN40Lである。
SN10~30まではTSMC N7で製造されていたが、SN40LではTSMC N5に移行したほか、新たにHBMを64GB搭載した。引き続きOff Chip、つまりパッケージの「外」にDDR5を最大1.5TB接続できるが、SN30まではOn ChipのSRAMとOff ChipのDRAMの速度差が大きすぎるという問題があり、これへの対処としてメモリーを3階層にした格好だ。
内部構造も少し変更になった。SN10~SN30まではPCUとPMUが別々に存在する形でメッシュを構成していたが、SN40LではPCUとPMUが一体化する形でメッシュを構成するようになった。
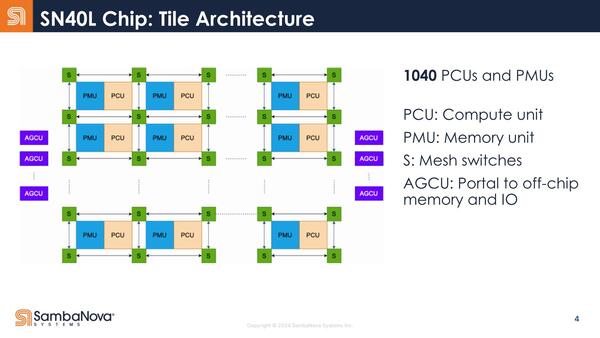
もともとSN10でPMUとPCUの間にスイッチを挟んだところで意味があるのか(つまりPCUが隣接しないPMUからデータを取り込むケースがどの程度あるのか)は不明だったが、こういう構造になったということはPMUとPCUが1:1で動作するケースがほとんどだったということだろう
ただPMUのサイズは1個あたり0.5MBで、これはSN10~30までと変化がない。PCUの内部構造もSN10とほぼ同じに見えるし、PMUの方も表現こそ違うがSN10のものと基本的には変わらないように見える。
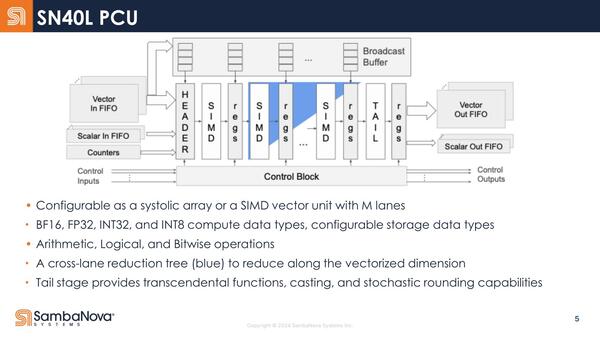
PCUの内部構造。サポートされるデータ型も同じ。強いてい追えば"Cross-lane reduction tree"は新しい気がする
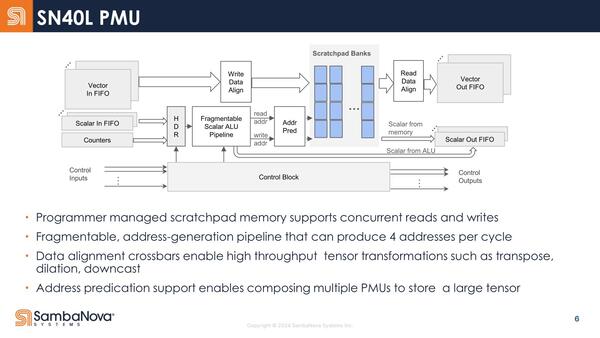
PMUの内部構造。Fragmentable Scalar ALU Pipelineは、SN10で3つ直接に並ぶFU/PRのことに見えなくもない。ただWrite Data AlignmentなどはSN10にそれらしいものが見つからない
ちなみに今回Top-Level Interconnectが公開されたが、この概念図を見る限りでは2つのダイからなるSN40Lは内部のメッシュを2つのダイで共有しているように見えなくもない。
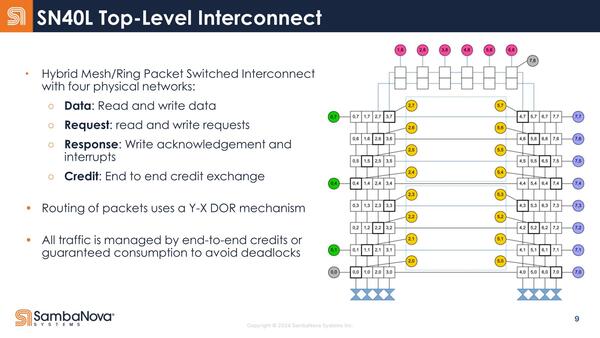
Top-Level Interconnectの概念図。SN10~30と40Lでは実装が異なっているように見える
ちょうどSapphire Rapidsが内部のメッシュを隣接するタイルまでEMIB経由で延長して、4タイルで1つの巨大なメッシュを構成していたが、SN40もそんな形に2つのダイにまたがる形で1つの仮想的なメッシュ/リングネットワークを構成しているようだ。
下の画像はSambaNovaが今年5月に出した"SambaNova SN40L: Scaling the AI Memory Wall with Dataflow and Composition of Experts"という論文に記載されていた図であるが、RDUタイル同士をつなぐ縦方向のメッシュはそのままDie-to-Die I/F経由で隣接ダイにつながり、一方横方向のメッシュはTLN(Top Level Network)経由でやはりDie-to-Dieでつながる格好に見える。
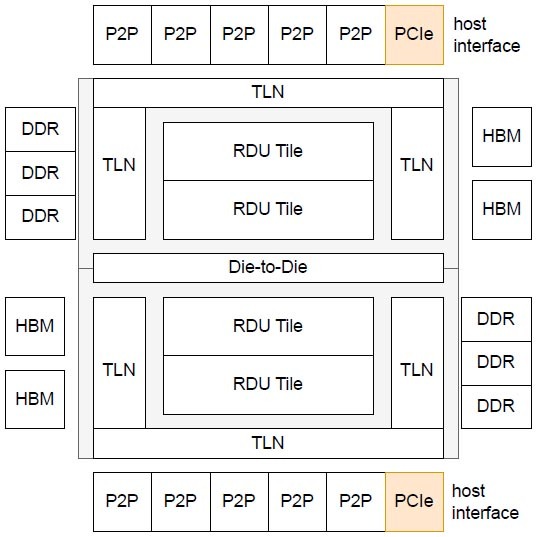
ちなみにSN10~SN30まではRDUタイルあたり160 RDUコアだったが、SN40では260 RDUコアに変更されているようだ
余談になるが、2つ上の画像にあるTop-Level Interconnectの概念図でP2Pと記載されている部分はおそらくイーサネットである。SN10世代ではSN10を2つ搭載するシャーシから、16本のQSFP28ポートが出ており、ここに100Gイーサネットをつなぐ構成になっている。
つまりSN10が1個あたり、100GbE×8である。これがSN30になるとQSFP56×18になっており、SN30が1つあたり200GbE×9という構成である。ここから考えるとSN40Lでは、400GbE×10が出るという感じになるのではないかと想像される。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































