




前回に引き続き、Lunar Lakeのコンピュートタイルについて解説しよう。残るのはGPUとNPU、それと周辺回路周りである。
Xe-LPやXe-LPGで省かれていたAI関連の命令が復活
Meteor Lake世代は、GPUにXe-LPGが搭載されていたが、Arrow LakeではXe2に進化した。

スケジュールがまだ変わっていなければ、今年の年末に出るであろうBattlemageベースのディスクリートGPUもXe2ベースになる「はず」だ
そのXe2の進化ポイントが主に効率(Efficiency)の向上、というのは単にLunar Lakeの実装に当たっては効率の向上に係る部分の機能を実装したという話なのか、それともXe2世代全体の特徴が効率の向上のみ(性能向上はEU数の増加で担う形とし、その際のスケーラビリティの確保などは効率向上の中に含まれる)であるのかは、現時点では判断できない。
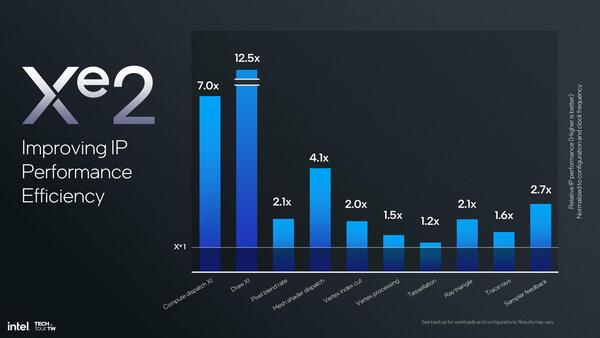
比較対象がXeのなんなのかが不明。Xe-LPGではなさそうで、Xe-LPとの比較かもしれない
ただこの効率、コンポーネント単位では(コンポーネントによって差が大きいが)1.2~12.5倍改善しているとする。また、Xe世代では1つのレンダー・スライスあたりXeコアが4つで、あとはレンダー・スライスを何個搭載するかでシステム全体の構成が決まる格好だったが、Xレンダー・スライス2ではレンダー・スライスの数だけでなく、個々のレンダー・スライス内部のXeコアの数も可変になった。

最初の製品であるLunar Lakeに関しては、レンダー・スライス内にXレンダー・スライスコアが4つであり、これはMeteor LakeのXレンダー・スライス-LPGコアと変わらない
そしてXeコアの内部も変更になった。

XeコアのうちVector Engine側の理論上のピーク性能はMeteor Lakeから変化がない
Meteor LakeのXeコアの内部構造とは、以下の違いがある。
- 256bit×16のVector Engineが512bit×8に変更された
- XMX Engineが復活した
- 新たに64bit Atomic Opsがサポートされた

Xeコアの内部構造
このうちXMX EngineにHA、もともとXeコアにはXMXエンジンが搭載されており、ところがXe-LPやXe-LPGではそこまでAI関連命令が必要ないということで省かれていた経緯がある。
ではなぜXe2では復活したか? といえば、AI PCということで単にNPUを強化するだけでなく、現在のアプリケーションではGPUを使ってAI処理をするものも多く、こうしたものでも性能を発揮させるためにはXMXがあった方が有用だから、というあたりが理由と思われる。
後述するが、Lunar LakeのGPUはトータルで67TOPSの処理能力を持つとしており、これはNPUの処理能力である45TOPSを超える。この67TOPSの処理能力の大半はXMXによって実現しているので、AI PCを名乗る以上外すわけにはいかない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























