



AWS Fargateを使った大規模常時接続に立ちはだかった壁の数々
「1億台の常時接続」を実現せよ! Nintendo Switchのプッシュ通知システム全面刷新の裏側
2024年06月27日 15時00分更新

ECS on Fargateの機能強化で満たされた一部要件
林氏は、「ECS on Fargateで大規模な常時接続システムを実現するためには、様々な要件が求められる。旧システムをリリースした当初のECS on Fargateではそのための機能が不足していた」と説明する。だがその後、ECS on Fargateの機能強化によって、一部の要件は実現可能になっていく。
そうしたECS on Fargateの機能強化のひとつが、「TCP接続を維持するためのチューニング」機能だ。
プッシュ通知システムは、スリープ中でもNintendo Switchとの接続を維持している。スリープ中のバッテリー消耗を防ぐため、「TCP keepalive」で負担を軽減したり、TCP再送関連の挙動に気を配ったりという工夫が必要だった。
ECS on Fargateでは、こうしたTCPの挙動を細かくコントロールするためのカーネルパラメーターの調整が、2023年8月より可能になった。

TCP接続を維持するためのチューニングが可能に
もうひとつのアップデートが、NLBの「クライアントIPの保存」だ。
インフラコストの観点から、1タスクあたり数十万の同時接続が求められる中では、NLBの「ポートアロケーションエラー」の発生がボトルネックになる。
クライアントIPの保存が“無効”になっていると、NLBによってソースのIPアドレスとポートが付け替えられる。その結果、ロードバランサーノードへの同時接続数が5万5000を超えたあたりでポートアロケーションエラーが発生してしまうという。
このクライアントIPの保存が2021年に可能になったことで、このボトルネックを回避できるようになった。
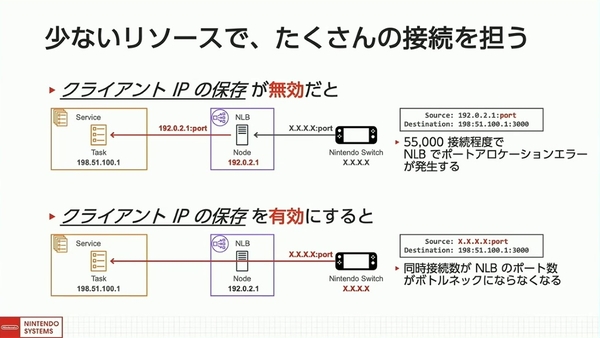
クライアントIPの保存が無効の場合と有効な場合
ただし、クライアントIPの保存を有効にするとポートの共有という問題が発生してしまう。
NLBは、AZごとにロードバランサーノードを作成して、それぞれ別のIPアドレスを割り当てる。クライアントが名前解決をした際には、これらのIPを複数返答することで負荷分散を実現している。この仕組みにより、複数のNintendo Switchが同一のNATを経由して異なるロードバランサーノードに接続すると、宛先のIPが異なるためNATがソースポートを共有し、通信が切断されてしまう可能性があるのだ。
同社はサービスの品質低下と天秤にかけ、AZをまたいだ「クロスゾーン負荷分散」を無効化することで、この問題を回避した。
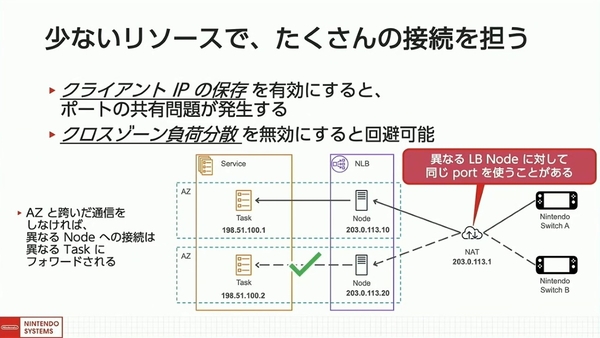
クロスゾーン負荷分散の無効でポート共有問題を回避
このように、ECS on Fargateの機能強化で一部の要件は満たされた。それでも足りない要件は、補完する独自の仕組みを実装することになった。その仕組みのひとつが「デプロイツール」の自作である。
デプロイツールの自作で、大量接続を安定かつ高速に再接続
システム開発部の坂東氏は、「デプロイツールを自作した一番の目的は、デプロイ時の負荷分散を行うこと。常時接続で最も負荷の高い処理は“接続の開始処理”だ」と強調する。デプロイ時には、すべてのタスクが入れ替わって再接続処理されるため、すべてのタスクに対して均等かつ、接続処理が重ならないよう分散させることが理想になる。
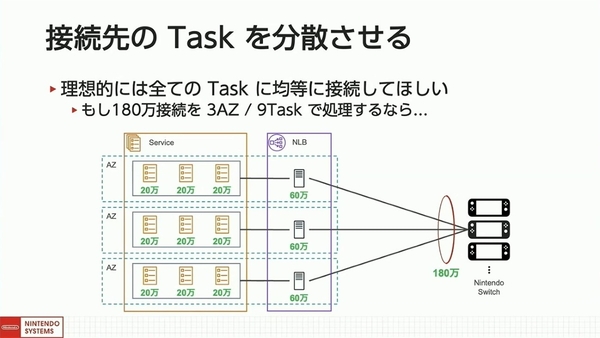
接続先のタスクを均等に分散させることが理想
接続のタイミングを分散させる方法については、リプレイス前から実装している、一定の速度で再接続を促す「ドリップ処理」を踏襲(参考記事:Nintendo Switchのプッシュ通知を支えるテクノロジー)。新たに取り組んだのは、不均等な接続先のタスクを分散させることだ。
タスクが不均等に接続される要因は2つある。ひとつは、AZにおいてタスク数が均等に配置されないことだ。例えば、5つのAZを横断して50台のタスクをデプロイした場合、あるAZにはタスクが1台しか配置されないのに、ほかのタスクには16台が配置されるといった事態が起こりうる。「このような不均等な配置は容易に起こり得る」と坂東氏。
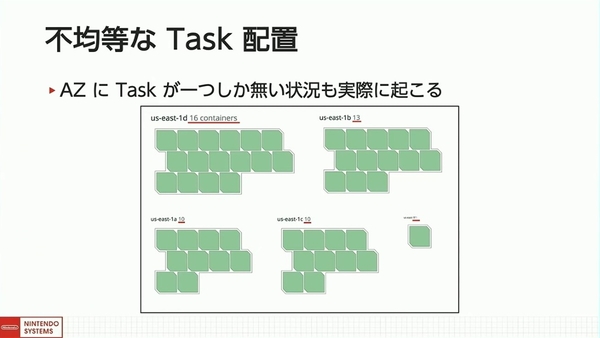
不均等なタスク配置の問題
もうひとつの問題は、起動タイミングのばらつきによる問題だ。NLBでは負荷に応じて動的にリクエストを割りあてる「least connection」アルゴリズムをサポートしておらず、かつ常時接続サービスは、一度接続が開始されるとリバランス(再配置)の機会が発生しない。そのため、一部のタスクの起動が遅いと、早く起動したタスクに接続が偏ってしまう。
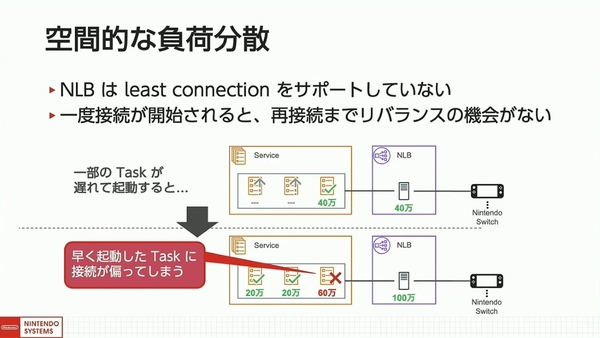
起動タイミングのばらつきの問題
これらの要因から、常時接続サービスのデプロイでは「再接続はゆっくりしてほしい」「タスクはAZに均等であってほしい」「タスクはなるべく同時に起動してほしい」という3つの要求を満たす必要がある。古いタスクを新しいタスクに切り替える手順に沿って解決策が解説された。
デプロイが始まる前は、すべての接続が古いタスクに向いている。ここで新しいタスクを立ち上げると即座に新規接続が流れてしまうが、新しいタスクは、AZによって不均等な状態である可能性がある。
そこで、「ヘルスチェックの状態を制御する」仕組みを実装し、AZに対して均等にタスクが配置されているかをチェックできるポイントを設けた。具体的には、新しいタスク内のアプリコンテナをヘルスチェックさせ、Amazon S3上に特定のオブジェクトが存在しない限り失敗させることで、タイミングを制御した。
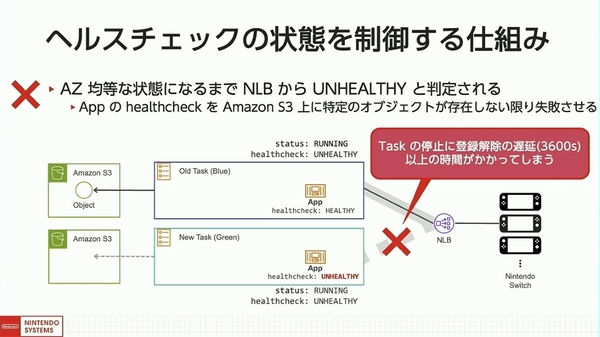
ヘルスチェックの状態を制御する仕組み
新しいタスクが起動すると、デプロイツールはタスクが均等に配置されているかを確認し、過剰なタスクを停止させることで均等になるよう調整する。「感覚的には、1、2回停止して回ることで、均等にタスクを並べることができる」と坂東氏。
しかし、NLBに登録されたタスクを停止すると、ECSサービスが、NLBの登録解除の遅延設定の時間だけ待機して、リバランスに大幅な時間を要してしまう。この問題の解決には、ECSサービスが、タスクのすべてのコンテナが起動完了するとNLBに登録するという仕組みを利用した。タスクのアプリに、ヘルシーになるまでペンディング状態を維持するサイドコンテナを追加することで、NLBの登録を意図的に防いだ。
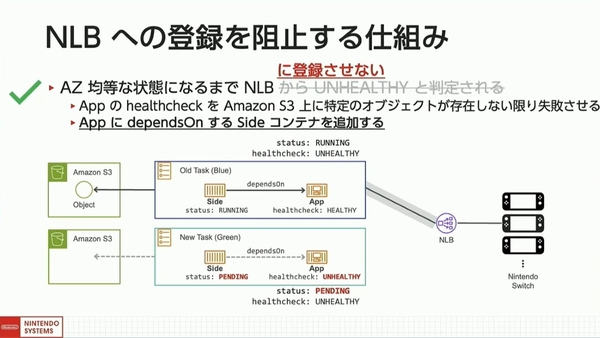
NLBへのタスクの登録を防ぐ仕組み
タスクがAZに均等配置されると、S3上にオブジェクトを置いて、アプリのヘルスチェックが成功し、ペンディングしていたサイドコンテナが起動して、NLBにタスクが登録される。そして、新しいタスクに新規の接続が流れる。
一方で、新しいタスクへのルーティングが開始されると、古いタスクの停止処理が開始される。ここで古いタスクへのすべての接続が、瞬時に切断されてしまうと、分散されない再接続処理が発生してしまう。この問題の解決には、タスク内のアプリがNLBからの登録解除を検知する機能と、前述のドリップ処理を実装することで解決した。
古いタスクを停止すると、まずはNLBから登録解除される。アプリは自身のタスクが登録解除されたことを検知すると、つながっているNintendo Switchに対して、一定速度で再接続要求を出すことで再接続処理を分散させる。再接続要求を出し終えると、アプリのプロセスが終了して、ECSサービスによって削除されるという流れだ。

デプロイ時に再接続する仕組み
ここまでのデプロイのプロセスは、もちろん手動ではなく、GitHubのCI/CDツールである「GitHub Actions」のワークフローとしてすべて自動で実行される。デプロイは約30分で完了し、接続中に届いた通知も、再接続が完了すると受け取る仕組みで、ユーザーへの影響もない。負荷試験では、実際に1億台の接続を維持した状態で、挙動に問題ないかどうかを確認したという。

デプロイはGitHub Acionsで自動化(右下図は、負荷試験で1億台の接続を維持した状態でデプロイを実行した際のタスクの接続台数の推移)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
クラウド
食糧不足や医療危機などの社会課題に、今あるAIで立ち向かうテクノロジストたち -
ビジネス・開発
AWSのAIが実現する「JR東海のリニア新幹線」と「電通デジタルの次世代マーケティング」 -
サーバー・ストレージ
ANAグループ4万人が“データの民主化”を実現した「14の秘伝」 -
ビジネス・開発
ゼネコン現場社員が3年でここまで開発、戸田建設の内製化は「外部頼みでいいのか」から始まった - この連載の一覧へ



