



ロードマップでわかる!当世プロセッサー事情 第765回
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ
2024年04月01日 12時00分更新

GB200 Grace Blackwell Superchipは
Grace Hopper比で2.5倍~6倍の性能
さて今回のメインとなるのは、このBlackwellを利用したシステムの話だ。前回示したロードマップにもあるように、本来B100をベースに、ArmベースのGrace CPUを組み合わせたGB200やGB200NVLというソリューションと、x86と組み合わせるB100とB40というソリューションの2つが用意される。
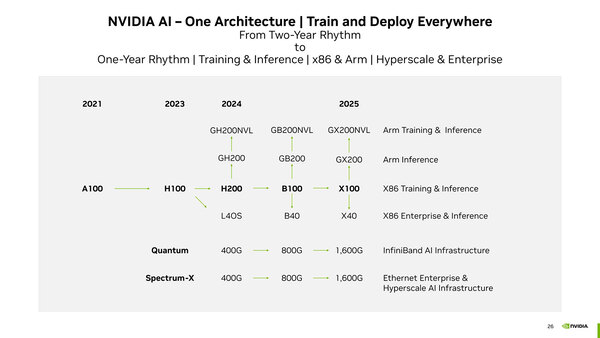
NVIDIAのロードマップ
現時点で公開されているのは、以下の3種類のみである。
- B200×2+Graceを組み合わせた、GB200 Grace Blackwell Superchipと、これを36枚組み合わせたGN200 NVL72
- B200×8を1枚のキャリアボードに搭載した、HGX B200
- B100×8を1枚のキャリアボードに搭載した、HGX B100
まずGB200 Grace Blackwell Superchipというのが下の画像だ。その下の拡大図を見ると、Grace Hopper比で2.5倍~6倍の性能という数字が出てくるが、FP6やFP4を使った場合の数字ということを考えると、この性能が本当に発揮されるのかどうかはTransformer Engineの頑張り次第という感じがする。

B200の搭載メモリー量(HBM3e)は192GBなので、GraceにはLPDDR5xが480GB分搭載される。これはGrace Hopperと同一スペックである

下の方に見える7つのソケットと、右端の2つのソケットはPCIeのOCuLinkのものに見える。ボードの上に垂直にカードを差すのは実装密度の観点から現実的ではなく、OCuLinkを使って外部に引っ張り出すのが一般的だから理解はできる。それにしてもB200とGrace周囲のVRMの配置がエグい
基調講演ではこの開発用のボードも披露された。

右手に持つのが開発用のもので、全体的にかなり広い。左手の方が製品のモックアップである
このGB200 Grace Blackwell Superchip(ボードなのにチップ呼ばわりするのもどうかと思うが)を2枚、1Uのブレードに収めたのがBlackwell Compute Nodeであり、このブレードを18枚集積したのがGB200 NVL72となる。

Blackwell Compute Node。当然のように液冷である

Blackwell Compute Nodeを18枚集積したGB200 NVL72。9枚×2ではなく、10枚と8枚になっているのがおもしろい
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")









































