




AI推論エンジンにDSPとプロセッサーを統合
さてそのQuadricが考える現在のAIプロセッサーの問題とは、純粋にAIの推論だけを考えればGraph Processorが処理に適しているわけだが、実際にはその前後にDSP(Digital Signal Processor)あるいは通常のプロセッサーが必要、という話である。
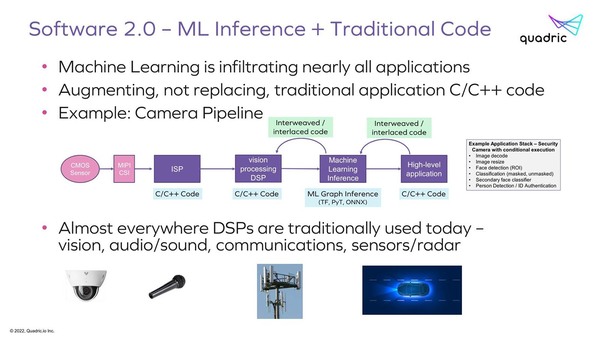
これは映像をAIで処理するような例だが、音声とか無線などでも構図は同じ、とする。まぁ実際同じである
そういうこともあって、純粋なAIのアクセラレーターはともかく、特にエッジ向けのAI推論向けプロセッサーは下の画像のような構成になっていることが多い。
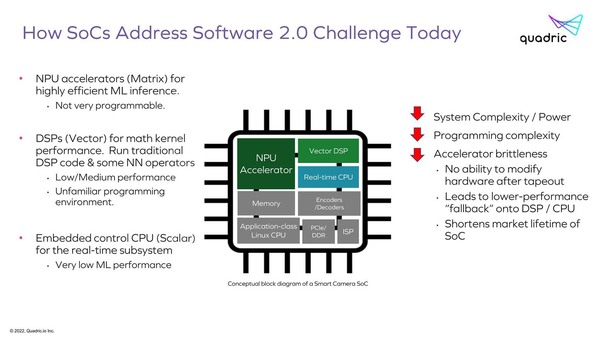
エッジ向けのAI推論向けプロセッサーの構成。ここでRealtime CPUとApplication-class Linux CPUの両方を持つかどうかはケースバイケース。通常Linuxなどが動くアプリケーションプロセッサーは別に用意するパターンの方が多いように思う
ただ当然こうした構成にすると、性能を確保しようとするとそれぞれのエリアサイズが肥大化するのでコスト上昇につながるわけで、コストを抑えるためには必然的に性能も抑える必要性がある。
「ではAI Inference EngineにDSPとRealtime Processorの機能を統合してしまえばいいのでは?」というのがGPNPU(General Purpose Neural Processor Unit)ことChimeraプロセッサーというわけだ。自分たちで“キメラ”と名付けるあたり、ある程度ゲテモノであることは理解してはいるのだろう。
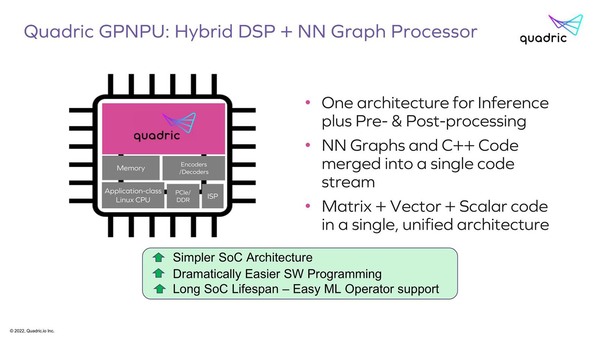
GPNPUの理論。「混ぜるな危険」一歩手前、という感じではある
そのChimeraの中身が下の画像だ。命令長が64bitというあたりは、おそらくはVLIWのような構成になっており、通常のMPU/DSP命令(上段)とArray Processor(下段)が同時に動作する、ということに見えなくもない。
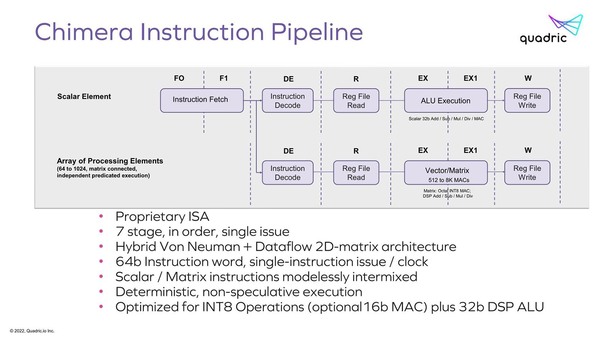
Chimeraの構造。ここまで分離してるなら、そもそも別のプロセッサーでいいのでは? というのが率直な感想だ
ただMatrixの方はデータフロー的に動くというあたりでもう理解ができなくなっている。データフローの場合、「普通は」すべてのProcessor Elementが独立して動くMIMD的な構成にするわけで(さもないとデータフローでなくなる)、あるいは実は64bitの命令といっても先頭にMPU/DSP命令か、Matrixかのbitが付いていて、Matrixの場合は即時実行するのではなく各MatrixのProcessor Elementに命令をロードするだけという可能性もあるのだが、パイプラインを見るとそれも違うように思える。
どう動くのかがさっぱり見えてこないあたりが困ったものだが、Chimeraの名に恥じない構成ではあると思う。下の画像がシステムの構成図であり、これだけ見ると良くある構成である。

上の画像にデータフローの文字がなければ、右のPEは単にSIMDのように動くベクトル・アクセラレーターと見なしてもよさそうではある
Scalar Elementからのライトバックだが、これもLocal Register Memoryから2次キャッシュへDMAエンジンが用意されており、これを利用して書き出す格好になる(このスライドでは省かれている)。
PE(Processing Elements)の方も同様に、Distributed LRM(Local Register Memory)にまずPEから書き出し、それがDMA経由で2次キャッシュにライトバックという順当な構成である。
ただそのChimeraを利用した場合の処理パスを見ると、例えばFace detectの出力はDistributed LRMから一度2次キャッシュに書き出され、NMSはもう一度2次キャッシュから今度はScalar Element側のLRMにデータを読み込んで処理をする、という少し複雑なパスを通ることになる。
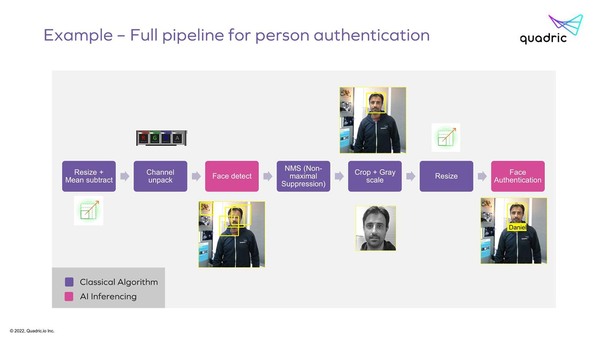
Chimeraを利用した場合の処理パス。ただこれも細かい話をすると、NMS以外の処理はハードウェアの専用ロジックにする方が普通だと思う
これ、素直にScalar ElementからDistributed LRMにアクセスできる(あるいはその逆)パスを用意できればもっとシンプルになりそうな気はするのだが、今度は内部構成が複雑になりすぎるのであえて諦めたのかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























