




クラウドファンディングで資金を集めParalleraを開発
製造の遅れで倒産寸前にまで追い込まれる
そこで同社は2012年、まずEpiphany-IIIをベースにした開発ボードを売ることを決定する。これがParalleraである。このParalleraの販売にあたっては、ちょうどこの頃急激に盛り上がったクラウドファンディングを利用することで資金的な問題をカバーする方策がとられた。
Kickstarterを利用し、最終的に5000バッカー、90万ドル弱を集めることに成功する。ちなみに筆者はこの際199ドルをプレッジし、Epiphany-IIIベースのParallellaを入手することにした。
さて、これでうまくいくかと思ったら甘かった。Paralleraボードの最初のプロトタイプは2013年5月に完成。このバージョンは消費電力が高いとかHDMIが動かないなど問題はあったものの、42枚のボードを組み合わせての分散処理テストにも成功。8月には5万個のEpiphany-IIIの量産に入るとともに、Epiphany-IVベースのParalleraボードの開発に入る。
というのは、そもそもKickstarterでは16コア版と64コア版の両方を募集していたからだ。ところがこちらの開発に難航。さらに製品版の製造の遅れなども加わり、倒産一歩直前に追い込まれる。
最終的にベンチャーキャピタルから3600万ドルの資金を得て、からくも倒産を回避するが、この前後に同社のエンジニアがほぼ全員辞職。Olofsson氏1人での再出発となった。それでもParalleraボードの開発はなんとか進み、筆者の手元には2014年4月に発送された。
当初の予定では2013年5月に発送予定だったので、ほぼ1年遅れではあるが、Kickstarterではよくある話ではある。2014年中に、64コア版を含む製品の出荷が無事に終わり、加えて冒頭にもあるようにRS ComponentsやDigiKey、US Amazonなどでの販売もスタートした。
2015年には世界中でこの16コア/64コア Paralleraボードの売り込みをしており、2015年5月には東京でPTC(Parallella Technology Conference)も開催されている(この時はOlofsson氏も来日したらしい)。
2016年には後継であるEpiphany-Vがテープアウトした。これはTSMCのN16FFプロセスをターゲットとし、1024コアを集積した構成である。ただこのEpiphany-Vの開発はDARPA(アメリカ国防高等研究計画局)の研究資金を利用しており、それもあってか最終的にこれが製造されたのは間違いないが、そのチップの行先の大半はDARPAだったのだろう。
Epiphany-IIIは28nmのNVIDIA GK110と
ほぼ同等の性能/消費電力比
ところでそもそもこのEpiphanyシリーズはどんな構成なのか? というのが下の画像だ。小さなRISCベースのコアが2次元メッシュでつながるという、ある意味良くあるメニーコアの構成である。一般的でないのは、当初からOff-Chip、つまり複数のチップを接続して並列動作を可能にするためのネットワークが初めから用意されていることだ。

これはEpiphany-IVの64コア構成の例で、Epiphany-I~IIIでは縦横4コアずつ、Epiphany-Vでは縦横32コアずつになる
実際、Paralleraボードの検証にあたっては42枚のボードを接続し、全体で共有処理ができることを確認したとしている。このあたりは、ボードを専用リンクでつなぐとどんどん処理性能を引き上げられるTransputerに似ているところがある。

さすがにOff-Chip Linkは1Bytes/サイクルでそれほど高速ではない
下の画像が実際の構成例であり、eLink(Off-chip Link)を使って複数のEpiphanyチップを接続することで性能を引き上げられる仕組みだ。
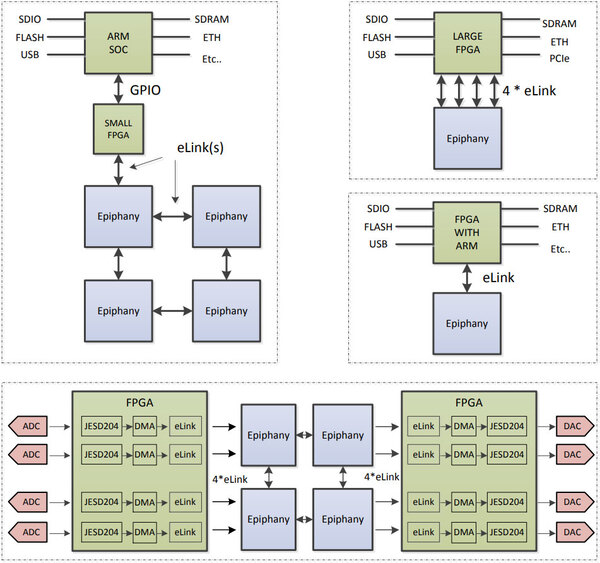
Parallellaボードは、右中央の“FPGA With ARM”とEpiphany-III/IVを1本のeLinkでつなぐ構成に相当する
個々のメッシュノードの内部は下の画像の通りで、4つのバンクに分割された32KBのSRAMとDMAコントローラー、2次元メッシュのI/F、それとeCoreと呼ばれるRISCコアからなる。

これはいずれもSRAM。ちなみにオフチップにDRAMを接続することも可能とはなっている(EpiphanyをOff-Chip Networkでつなぐのだろう)
そのeCoreの構造が下の画像だが、RISCコアと言いつつ右下にProgram Sequencerがあったりするあたり、汎用のRISC CPUコアというよりはDSP的な使い方を念頭に置いたものような気がする。説明によれば「汎用のCPUと同じようにループ制御やファンクションコール、割込み、アイドル、連続した命令の実行が可能」とされるが、こんなことを書く時点で普通ではないはずだ。
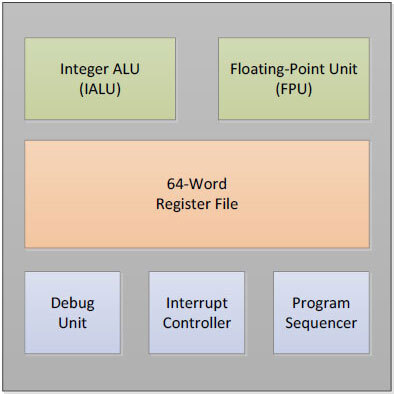
キャッシュの類は一切持たない。ちなみにすべてのメモリーは、他のメッシュユニットに接続されているものも含めて完全に共有メモリー構造になっている
このeRISC、命令パイプラインそのものはALUが6段、FPUが8段構成で、In-OrderながらDual Issue動作となっている。といってもALU×2やFPU×2は当然不可能で、IALU+FPU/IALUか、FPU/IALU2+Load/Storeのみである。
ただALUもFPUも1サイクルでの処理が可能であり、特にFPUでは1サイクルでMAC演算が可能なため、1GHz駆動のEpiphany-IIIなら32GFlops、800Mhz駆動のEpiphany-IVなら102GFlops(どちらも単精度)の演算が可能であった。これは結構すさまじい性能「だった」。
2012年と言えばGPUならNVIDIAのK20が単精度で3.5TFlopsほどの性能を叩きだしているが、こちらは消費電力235W。対してEpiphanyはIIIもIVもどちらも2Wでしかない。Epiphanyシリーズは最大4095コアまで接続可能になっているが、フル構成だとEpiphany-IIIベースなら消費電力は512Wになるが性能は8.2TFlops、Epiphany-IVベースだと128Wで6.5TFlopsになる。Epiphany-IIIベースで235Wだと3.7TFlopsほど。
やはり65nmプロセスのEpiphany-IIIはやや不利だが、それでも28nmで製造のNVIDIA GK110とほぼ同等の性能/消費電力比。Epiphany-IVはGK110に比べて3倍以上も効率が良い計算になる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ


















&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")











ゲーミングディスプレー、200Hz・1ms・昇降式多機能スタンドで3万2980円は断然買いでしょう")












