




MACユニットを高速に回すことに特化
さてそのEthos-Nシリーズの基本構成であるが、内部そのものは非常に単純である。Inference(推論)向けであり、かつ幅広い用途に使われることを考慮してか非常に簡単である。端的に言えばMACユニットをどれだけ高速に回すかしか考えていない。
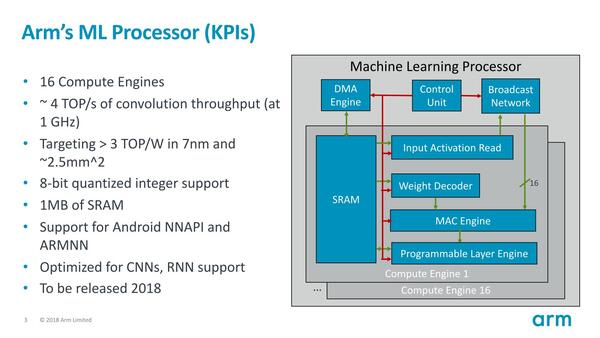
Ethos-Nシリーズの基本構成。これはEthos-N77のもので、Ethos-N37/57/78ではコアの数がSRAMのサイズが異なる
扱うのもINT 8のみという割り切った構成である。ただし7nmプロセスで2.5mm2程度のダイサイズで、かつ3TOPS/Wをターゲットにするという、シンプルにしてぶん回すだけではやや難しい性能ターゲットとなっている。これを実現するためにEthos-Nシリーズは以下の4つの原則を掲げている。
- 固定スケジューリング
- 畳み込みの効率化
- 帯域削減
- プログラマビリティー/スケーラビリティー
まず固定スケジューリングだが、エリアサイズ削減(余分な回路を入れて回路規模を大きくしない)と消費電力削減のために、動的なスケジューリングはComputation Engine側で一切実行しない。
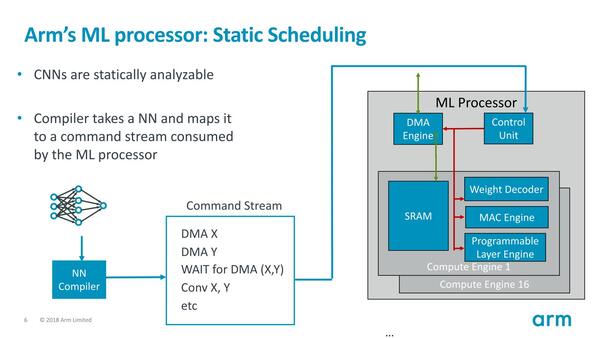
Computation Engine側で動的なスケジューリングは行なわない仕組み。要するにあらかじめソフト側で完璧にコマンドを組み立てておかないと効率が悪いという話でもある
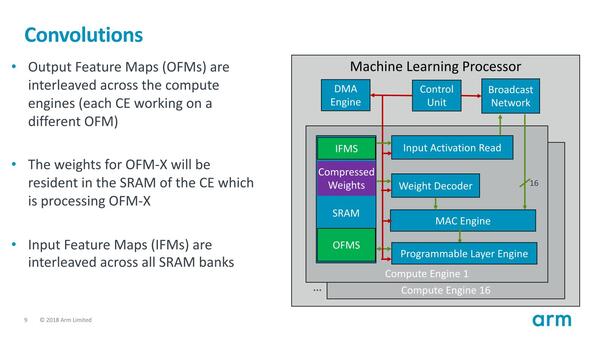
その一方で、疎行列で計算を省くといった工夫はない。このあたりは、そうしたメカニズムを入れることでむしろ機構が複雑化することを避けたのだと思われる。さらに固定スケジューリングでは、高速化してもあまり意味がないという話もある
次の「畳み込みの効率化」であるが、畳み込みはデータに重み(Weights)をかけて、その結果を合算する形になる。やっていることは単純だが、なにしろ扱うべきデータ量が多いし重みの数も非常に多く、結果外付けのDRAMに格納しておくことになる。
これは部品点数の点でも消費電力の点でも不利なため、内蔵のSRAMに、特に重みは圧縮して格納することで、畳み込みの計算の際に外部DRAMアクセスの必要を排除し、効果的に演算ができるようにしたというものだ。
ちなみに入力画像(IFMS:Input Feature Maps)が大きい場合、当然入力領域を分割して複数のCompute Engineで処理することになるが、畳み込みの計算の処理そのものは複数のCompute Engineはまたがない(それをやるとむしろオーバーヘッドが大きくなると判断したのだろう)。
ただ畳み込みの計算を終わらせて出力(OFMS:Output Feature Maps)を作成する際には、再び複数のCompute Engineの結果をまとめて処理する形になる。
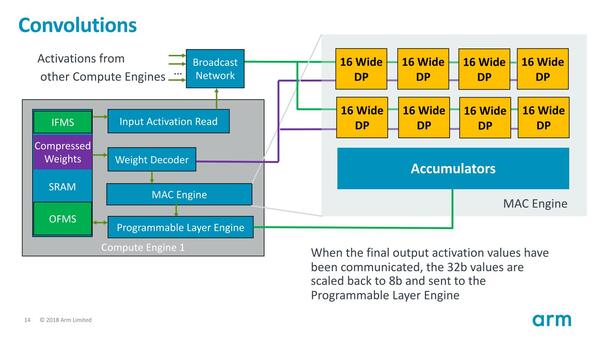
ちなみにこの中で一番ブン回るのがMACユニットになるので、ここは16nmおよび7nmプロセスに最適化してある、と説明されている
帯域削減は上でも触れたが、外付けのDRAMを接続するとそれだけで消費電力が倍近くなる。
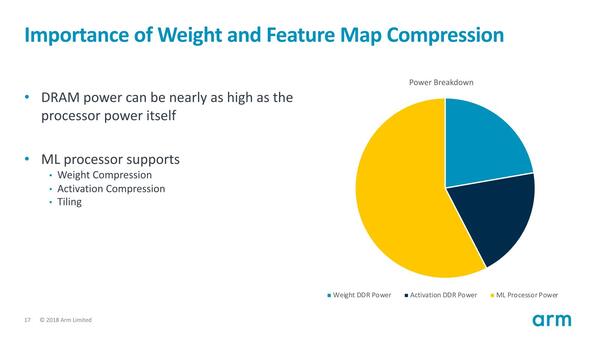
これはArmの試算であるが、外付けのDRAMを使うようにすると4割以上消費電力が増えるとしている
そこで内蔵SRAMを搭載することでDRAMの必要性を排除するわけだが、ただSRAMでも容量が大きくなれば消費電力はそれなりにかかるし、回路規模が大きくなるからエリアサイズ増大に直結してコストが上がることになる。
これを避けるためには、無駄な容量を使わないように工夫する必要がある。そこでSRAMへのWeightやFeature Mapの格納はすべて圧縮するようにした。もちろんこうなるとCompute Engineの側に圧縮/伸張エンジンが必要になるのだが、これによる消費電力増や回路規模増大を加味しても、SRAMの必要容量を減らせることのメリットの方が大きいと判断されたわけだ。
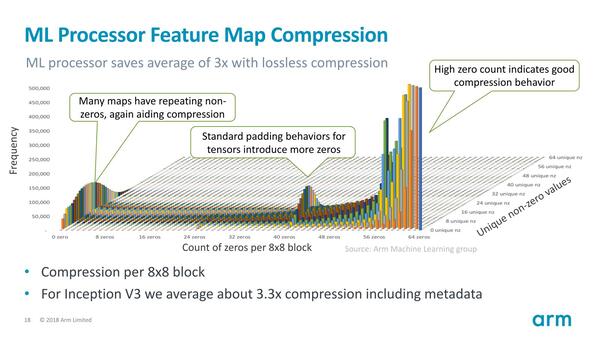
Feature Mapの場合、特に疎のデータが多いケースでは圧縮が効きやすいこともあって、平均で3.3倍の圧縮率が実現できたとする
また、これはハードウェアというよりはソフトウェア側の話になるが、プルーニング(ネットワークそのものの圧縮)をすることでメモリーを削減している。
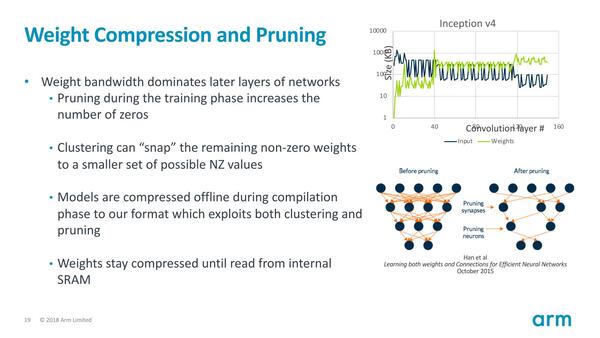
Weightも当然圧縮をかける。プルーニングは右下の図でわかるように、精度を落とさずにネットワークそのものを簡単化する技法であるが、Ethosの場合はこれはソフトウェア側で対応するものになっている
加えて言えば、SRAMベースであるからアクセス時間が正確に見積りできる。これを利用して、コンパイラの段階で各々の処理で必要となる帯域をきちんと見積って最適化を図ることで、帯域を削減できる余地があるとする。
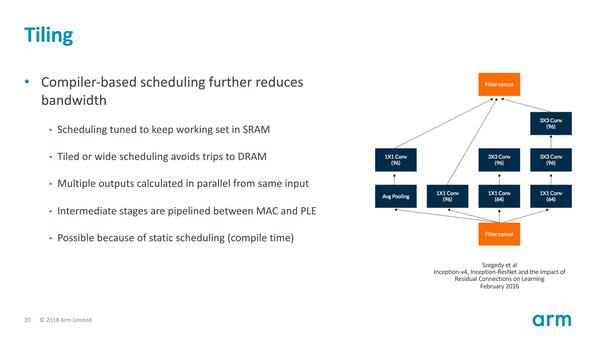
最適化することで帯域を削減できる余地があるという。もっともこれもソフトウェア側がどこまで最適化を図れるか次第ではある
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第886回
PC
CFETの足を引っ張るPMOSを救え! imecが提案する新絶縁層と、あえて精度を緩める「Notch Alignment」の妙手 -
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 - この連載の一覧へ














ディスプレーってなにがすごいの?一般的な平面モデルとの見え方の違いや曲率(R)の意味、選び方を解説")







&アスペクト比77:36って聞きなじみないけど使いやすいの?")

とBTO PCならではの特注PCパーツに大興奮")

















