




精度重視のためサポートするのは
INT 8ないしBFloat16のみ
さて価格や性能はおいておくとして、Flex Logicはどうやってこれを実現したか? であるが、基本的な流れは下の画像の通り。64サイクルが一つの区切りになっており、Load/MAC/Saveをパイプライン式に行なえるようになっている。

TPUを2次元構造に並べるベンダーもいくつかあるが、常に2次元を使い切れるとは限らないのが欠点。一方で1次元構造なら、効率は良いものの複雑なネットワークでは通信のレイテンシーが大きくなるという問題もある
ちなみに同社の基本的な発想は精度重視だそうで、それもあって例えばFPGAなどで多用されるBinary(Int 1)やInt 4などのデータ型は使われず、サポートされるのはINT 8ないしBFloat16になっている。
BFloat16では指数部8bit/仮数部7bit(+符号)なので、INT 8の演算エンジンがそのまま流用できるので、都合が良いということだろう。上の画像でINTだと64 MACsなのにBF16だと32 MACsというのは、2つのMACユニットで1つのBFloat16を処理しているのだと思われる。
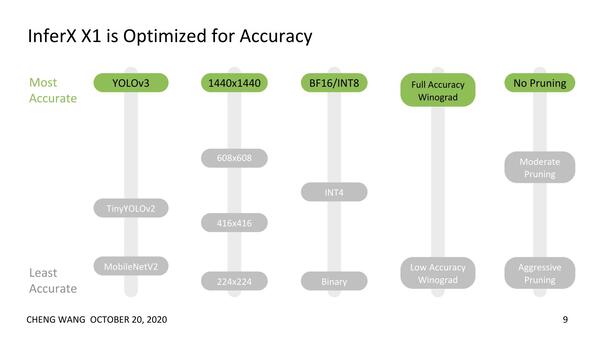
InferX1は精度重視。Winogradは畳み込み演算を高速化するアルゴリズムのこと
このTPUが16個と、他にFPGAロジック(図中のEFLX Logic)や2MBのL2 SRAM、それとXFLX Interconnetが組み合わさって1つのブロックを形成。InferX X1にはこれが4ブロック実装されるので、TPUは合計で64個、L2 SRAMは8MBとなる。
おのおののTPUにはMACユニットが64個あるので、トータルで4K MACsということになり、それなりの演算密度ではあるのだが、InferX X1の最大の特徴はこのXFLX Interconnectにある。

L1 SRAMは、64×256個のWeightを格納するためのものなので、16KBに収まっている。これが4つで(ブロックあたり)64KBに過ぎない
上の画像にも“Tensor Processors are Reconfigurable”とあるが、なにがReconfigurableか? というとTPUそのものではなく、TPU同士をどうつなぐかを動的に変更できるというものである。
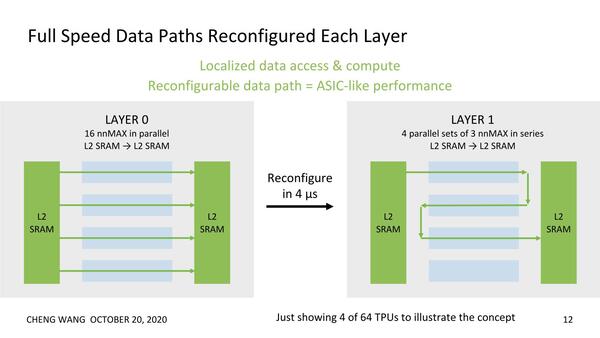
例えばある層では、16個のTPUが並行して動作するが、別の層では3つのTPUを連結して動かすという場合に、XFLX Interconnect内のつなぎ方を動的に変更可能になる
Reconfigurationは4μsで(つまり1秒間に最大25万回)変更が可能とされている。これで十分かというと、扱うデータ量やネットワークの層数に依存するが、例えば100fpsを実現したいと思うと、1枚あたり2500回のネットワーク変更が可能なので、普通に考えれば十分であろう。
ちなみにこうした複数のTPUを連続して動かすケースでは、ある段のTPUの出力が(そのままメモリーなどを介さずに)次のTPUに渡せるので、メモリー帯域の節約にもなるしボトルネックの削減にもなるとしている。
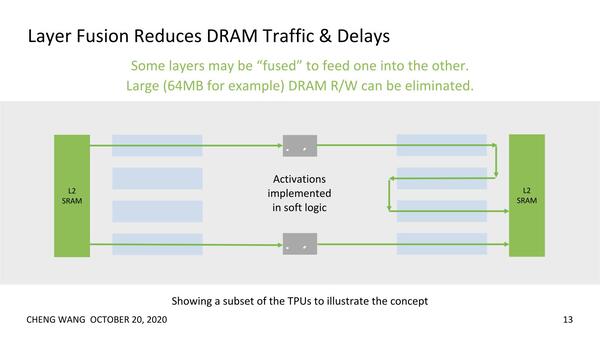
TPUで扱えないような特殊な処理は、EFLX Logicを利用して実装可能である。これが“Activation impremented in soft logic”の意味である
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















