




競合の30倍の性能を謳う
機械学習用アクセラレーターMosaic
話を元に戻すと、MLSoCの大半は通常のIPで賄えているが、唯一SiMa.aiが自分で設計したと思われるのがMosaicという名前のMLA(Machine Learning Accelerator)である。
MLSoCにはこのMosaicが1つ搭載され、5Wの消費電力で50TOPSの性能である。計算として正しいかどうかは微妙だが、先のGroqの場合、1PetaOps/秒の処理性能で、ResNet-50を利用して毎秒1万8900枚の画像を処理できる(*1)とされる。
1PetaOps/秒=1000TOPSなので、50TOPSというのはその20分の1で、毎秒945枚の画像をResNet-50で処理できる計算になる。もっとも実際にはこんな処理性能は無理(後で数字が出てくる)ではあるが、それなりの速度での画像認識が可能となっている。
ただSiMa.aiはこのMosaicの詳細は明らかにしていない。内部の説明は下の画像1枚だけだ。
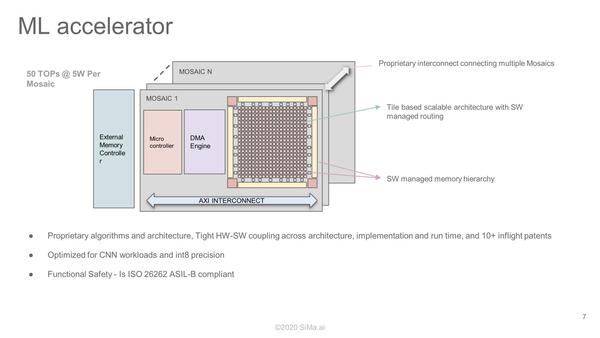
Mosaicの概要。S/W managed routingというあたりが肝の1つな気もするが、現在これに関して10以上の特許出願中とあるので、特許が取れるまでは詳細は公開するつもりがなさそうだ。Edge向けということでINT 8のみのサポートというのは、用途を考えれば不思議ではない
Mosaic単体でISO 26262 ASIL-Bに対応できるというのはけっこうすごい話で、これを2つ並べてロックステップ動作させれば理論上はASIL-Dも行けるはずだが、通常のプロセッサーはともかくこうしたアレイプロセッサーでロックステップが簡単にできるのかは不明である。
独自バスを使うことで複数枚のMosaicを連携して駆動できるようだが、そうしたアクセラレーターを出す予定があるのかどうかも現状では不明である。
ソフトウェアとしては、既存のフレームワークやランタイムと互換性を持たせたエリアと、Mosaicを駆動するエリアの2層構造からなる、というのはこの手のアクセラレーターとしてはごく普通である。
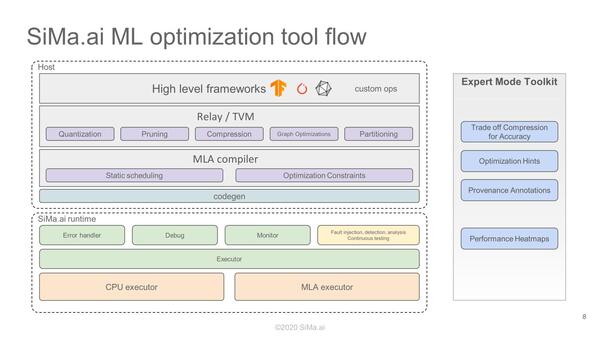
ここで言うCPU executorは、おそらく前の画像に出てきたMicro controller(とDMA Engine)用で、その前の画像に出てきたARM Subsystem用ではないと思われる
さて性能であるが、シミュレーションを利用したいくつかのテスト結果がこちら。
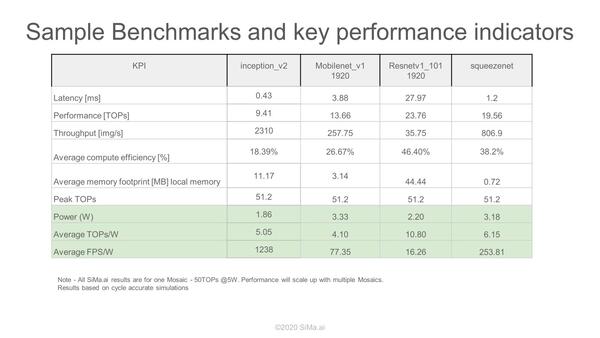
Groqの1万8900枚/秒という数字、画像サイズはもう少し小さい(256×256ピクセル?)と思われる。この数字も、画像サイズが小さければもっとスループットがあがりそうだ
ResnetV1_101では、画像のスループットが35枚/秒、Mobilenet_v1では257.75枚/秒とされるが、画像サイズがフルHD(1920×1080ピクセル)だとするとこれは超高速である。
しかも平均効率が40%以下、というのは「効率を上げればもっと性能があがる」と考えられるが、その一方で「効率を上げるのが難しいアーキテクチャーである」という見方もできるわけで、このあたりはもう少し詳細な情報がほしいところだ。
他にもいくつかのベンチマークを行なった結果も示されており、さまざまな用途で高い性能/消費電力比を実現できるとしている。
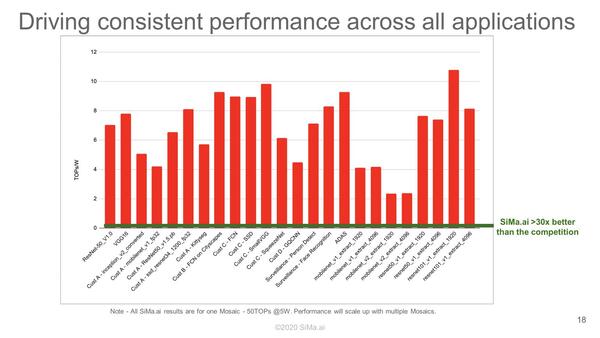
この場合、「競合」になにを想定しているのかがわからないので、30倍と言われても素直に受け取るのは難しい
AI向けアクセラレーターの場合、10TOPS/Wというのは1つのマジックナンバーで、これを実現できると言いつつ、実際に作るとここまで性能が出ないということは珍しくない。その意味では、シミュレーターではなく実際のチップでこれが実現できたら素晴らしい成果と言えるのだが。
ちなみにSiMa.aiはMLSoCの用途の一例として、半自動運転車や荷物運搬ロボット、セキュリティーカメラなどを想定しており、チップが出荷されれば評判になりそうだ。

こうした業界の顧客が高性能・低消費電力のAIチップを求めているのは周知の事実である。例えば最後のセキュリティーカメラの場合、現状では2~4台程度のカメラの映像を、まとめて複数枚のGPUカードを差した組み込み向けサーバーで処理するという実装が行なわれている
問題はその出荷時期がまったく見えないことだろうか? 今年のAI Hardware Summitに同社は参加しておらず、現時点ではアップデートがない。ただ10月20日からスタートする秋のLinley Processor Conferenceでは同社のKavitha Prasad氏(VP of Systems Solutions)が講演を予定しているそうなので、ここに期待したいところだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ





































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























