




ばらばらな災害情報を収集・整理・加工するレスキューナウ
続いて「危機管理情報の活用 その現状とレスキューナウの取り組み」というテーマで講演したのが、レスキューナウ代表取締役社長の朝倉一昌氏だ。

レスキューナウ 代表取締役社長 朝倉一昌氏
冒頭、朝倉氏は防災・減災分野のIT活用を考えるための参考として、地図メーカーのゼンリンとNAVITIMEを取り上げた。Google Mapの地図メーカーとしては契約が終了したゼンリンだが、同社が足で稼いで作った精密な地図とデジタルの巨人グーグルが結びついたことで、長い歴史を持つ地図のレベルが上に上がったのは事実だ。また、ナビゲーションアプリを手がけるNAVITIMEは、MaaSという概念が生まれる20年も前から交通機関をまたいだモビリティサービスを意識していたという。
両者で共通しているのは、お金、時間、労力をかけてデータを作っていることだという。ゼンリンは毎年100億円以上をかけて地図データを整備し、精度の担保は最終的には人間が行なっている。NAVITIMEは30人の調査員が全国各地の駅に足を運んで緻密な調査を展開している。「氷山の下にあるような、一見不可能に見えて放置されている課題や非効率を、愚直に時間をかけて解決しているところに大きなポイントがあるのではないか」と朝倉氏は指摘する。とはいえ、地図や交通といった分野だけとっても情報を集約するのは難しい。これはレスキューナウが取り組む災害情報の分野でも同じだという。
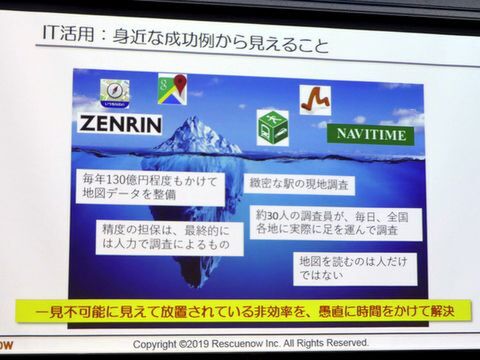
地道な努力で情報を収集・加工・整備するゼンリンとNAVITIME
災害情報は利用する個人や組織によって利用目的が異なり、タイミングや情報の種類も多岐に渡る。しかも状況は刻一刻と移り変わり、利用する形式も異なる。日本には数多くの災害情報システムが存在している。しかし、朝倉氏は「こうした多種多様な情報ニーズに対して、システム導入の目的を満たすための、情報の取り扱いの大変さ、困難さ、非効率的に真剣に対峙しているだろうか?」と疑問を投げかける。
たとえば、道路情報は警察庁や県警、国交省、自治体、道路会社などの情報が日本道路交通情報センターを介して統一データとして提供されるため、運行情報は使いやすくなっている。気象データも同じく、気象庁の情報が気象業務データ支援センターを通じて、統一されたデータで提供される。
しかし、それ以外の危機管理情報はデータ仕様が統一される仕組みがなく、政府機関、自治体、消防機関、警察機関、医療機関、NPO、ライフライン、ボランティアなどがおのおののタイミングとデータ仕様で関係者に丸投げされる。しかも、前述した道路や気象の情報を横断的に利用するのも難しく、連携も実現していないというのが現状だ。
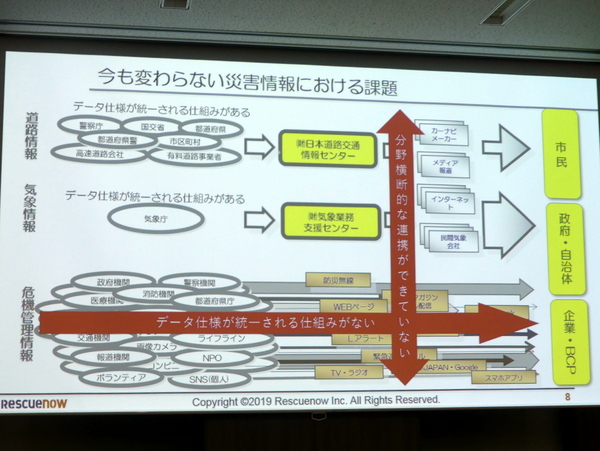
気象や交通の情報に対して、災害分野情報は統一される仕組みがない
最近は横断的な情報共有・利活用を可能にする「SIP4D:府省庁連携防災情報共有システム)の開発も進められており、災害情報を仲介するハブ機能や「ISUT」と呼ばれる災害情報の集約支援チームが用意される。オープンデータも同じで、単にデータを公開するだけではなく、システムで処理・活用するための施策にフォーカスが当たりつつある。朝倉氏は、「システムを作って終わるのではなく、稼働・運用させるために汗をかかないと、上のシステムが活きてこないという認識を関係者が持ちつつある」と今後の動きに期待した。
想定外の事象を扱うからこそ、必ず人が介在する
20年に渡って災害情報を提供してきたレスキューナウは、国内2カ所に危機管理情報センターを持ち、24時間365日の有人体制で、前述したような多種多様な情報を収集する。これらの情報は整理・加工された後、独自のリアルタイム危機管理情報データベースに格納し、情報配信サービスや企業の危機管理サービスなどに配信している。
危機管理情報センターは、グリーン、イエロー、レッドという3つのステータスによって、それぞれオペレーションの体制を変えているという。コードレッドになると、2km範囲内の社宅に在住するメンバーが出社し、発令20分以内に緊急体制がひかれる。大災害発生時は60分以内に54項目におよぶオペレーションが実施。リアルタイムの危機管理情報において、32カテゴリ、120項目をカバーし、年間の配信件数(手動配信)は約52万件におよぶ。「想定外の事象を扱うからこそ、必ず人が介在するオペレーションの仕組みを作って運用している」と語る。
レスキューナウの情報収集では「収集するデータと出力するデータ」はイコールではないという考え方がある。気象やフライト情報、メディアやWeb、SNS、センサー、J/Lアラートなどの収集データは発生場所、深刻度、種類などを付与した独自フォーマットに加工し、レスキューナウの著作物として配信を行なっている、また、レスキューナウ側で事実確認を行なうため、情報の精度は重視していない。配信すべき情報は取材という形でレスキューナウ自身が情報元に確認し、あとからの問い合わせに対応できるように履歴もとっているが、万が一誤っていた場合でも、情報元にクレームを挙げることはないという。
人力で精度を担保している部分も大きいレスキューナウだが、オペレーションの高度化も推進している。データは「NEWSPIDER」というツールで一元的に収集し、速報性があるものはRIC/OSというシステムで入力/承認を経て、データベースに登録される。「今まではクローラーで集めた情報を人手で入力していたが、今は入力は自動化して、承認を人手でやるオペレーションに変えようとしている」(朝倉氏)。また、すぐに登録できない情報はいったん学習型解析エンジンに登録し、学習とフィードバックを繰り返して精度を向上させている。
データベースに登録された情報は、ポータルサイトや乗り換え系サービス、TVやWebのメディア、サイネージ、自治体の防災サービスの一部のほか、事業会社での安否確認、地図システムなどで用いられている。多様な災害情報をシステムで利用可能な形に加工することで、リアルタイムな地図化も可能になる。「ここまでの情報を一元的にまとめた事例は今まであまりなかったのではないか。これは技術がなかったのではなく、データを揃えるという作業があるから、こうした表現が可能になったのではないか」とアピールする。

多様な災害情報をリアルタイムに地図化
本記事はアフィリエイトプログラムによる収益を得ている場合があります



