




ファウンダリーロードマップシリーズの最後はインテルで締めたい。インテルは今年3月28日、Tecnhnology and Manufactureing Dayというイベントを米国で開催、同社のプロセス技術の最新動向について説明した。このイベントのスライドから、かいつまんで動向を追っていきたい。

インテルが建設中のFab 42
14nm++は同一消費電力なら
性能を25%ほど改善できる
まず14nm世代について説明しよう。以前も紹介したが、インテルは14nmに続き14nm+と14nm++の2つの派生型をリリースすることを決めており、Kaby Lakeには14nm+が利用されている。その14nm+と14nm++についての説明が今回あった。

14nm+は2016年初頭に、14nm++は2016年末に利用可能になった模様
この図、横軸は登場時期であるが、縦軸のほうはトランジスタの性能(左)とトランジスタの消費電力(右)で、14nm+/14nm++は消費電力そのものは14nmと同等だが性能が上がっており、特に14nm++は最初の10nmを上回る性能になっている、としている。
その14nm+について。下の画像はNMOSとPMOSの動作特性をまとめたもので、同じリークなら駆動電流が平均12%ほど向上しているという。
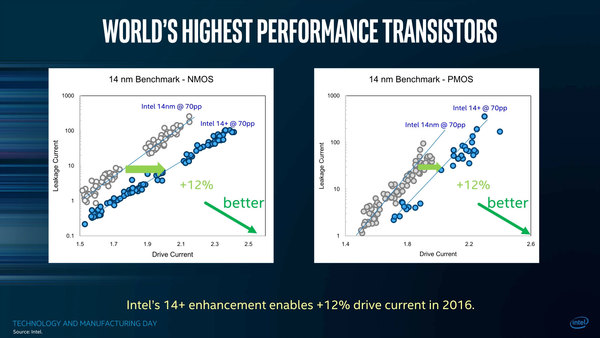
NMOSとPMOSの動作特性。駆動電流を増やすと当然リークも増えるが、その傾きの傾向が改善し、同じリークならより駆動電流を増やせるようになった
これが14nm++になると、14nm比で23~24%の改善になるという。ただしよく見ると、14nmと14nm+は70ppなのに対し、インテルの14++は84ppとある。
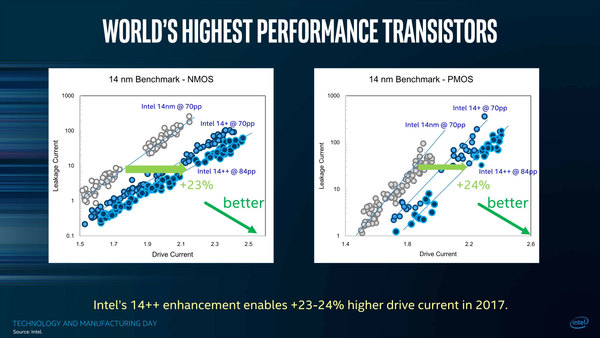
14nm+と14nm++の比で言えば10%ほどの改善といったところ
これはなにかというと、Gate Pitchである。Gate PitchはCPP(Contacted Poly Pitch)などと呼ぶことも多く、CPPとFin Pitchの値から擬似的にプロセスノードの数字が算出できる、という話は連載391回でも紹介した。
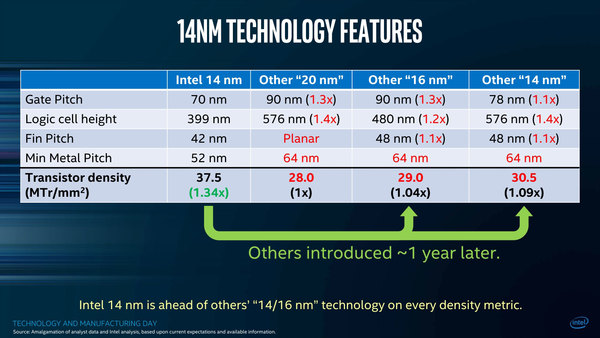
主要なファウンダリーの性能比較。Other “20nm”と“16nm”はTSMC、Other“14nm”はサムスンと思われる
話を戻すと、14nm/14nm+については、上の画像に示されるようにGate Pitchは70nmのままで実装されるが、14nm++に関してはGate Pitchを再び84nmに広げる。
実のところ、当初は14nm+がこの84nm Pitchになる模様だったが、いろいろ間に合わないということでこれを14nm++という形で後送りにして、とりあえずGate Pitchを変更しないまま部分的に性能を改善したのが14nm+ということになったらしい。
もちろんこうなると、物理実装に関しては基本的な寸法が変わってしまうので、再設計になってしまうことになる。実はKaby Lakeも、当初は84nmの14nm+向けに設計を始めたものの、これが14nm++にずれたことで名前をCoffee Lakeに更新。一方既存のSkylakeを14nm+で製造したものが新Kaby Lakeということになるらしい。このあたりは次回また説明したい。
ちなみに下の画像はその競合プロセスとの性能比較で、14nm世代の場合はTSMCの16FF+や14LPPと同等よりやや劣る程度のスペックだったのが、14nm+で大きく改善できたとしている。
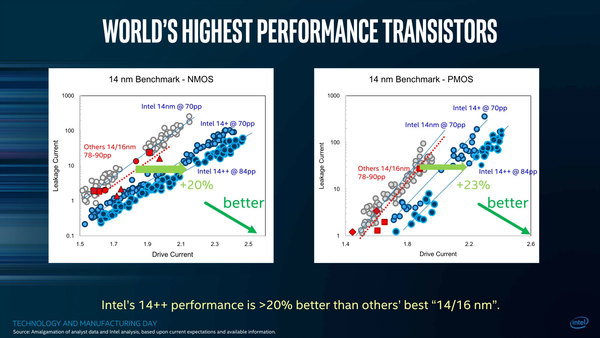
競合プロセスとの性能比較。赤が競合プロセスだが、○と□のどちらがTSMCでどちらがサムスンかは不明
結果として、14nmと比較した場合、14nm++では同一消費電力なら性能を25%ほど改善でき、同一周波数なら消費電力を52%下げられるとしている。ただし上にも書いた通り、既存の設計そのままで14nm++に移行することはできず、物理設計のやり直しになるのは避けられない。

同様に、14nm+では同一消費電力なら性能を10%アップ、同一動作周波数なら消費電力を40%弱カットできる
また14nm++世代では、少なくともGate Pitchはむしろ増える方向にある。他のジオメトリーがどうなっているかは開示されていないが、少なくともトランジスタサイズは良くて14nm+ととんとん、おそらくは増えるだろうと思われる。これはそのままエリアサイズの増大につながる。そうなるとインテルにとって、あまりおいしい選択肢ではない。
デスクトップCPUは6コアに、モバイルは4コアにそれぞれコア数を増やすうえ、GPUに関してはまだ全然性能が足りていないため、よりシェーダー数を増やす必要があり、これはそのままエリアサイズ増大につながる。したがって、インテルとしては14nm++を利用する自社製品はCoffee Lakeのみに留めて、むしろファウンダリーオプションとして提供する方に注力すると思われる。
現状、14nm世代の製品は9月と言われているCoffee Lakeが最後になるようで、Cannon LakeやIce Lakeは10nmであることが公式に発表されているし、その先も14nmに戻る気配はない。
もっとも14nm世代は業界的にも比較的長く利用される(Long-lived Node)と認知されており、インテルも14nm++をそうした用途向けに展開していきたいのだろう。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































