
Ryzen 7のダイを4つ搭載したMCMが
Naplesか?
ではNaplesは? というと、ずばりこのRyzen 7のダイを4つ搭載したMCM(Multi-Chip Module)になるだろうと筆者は考えている。
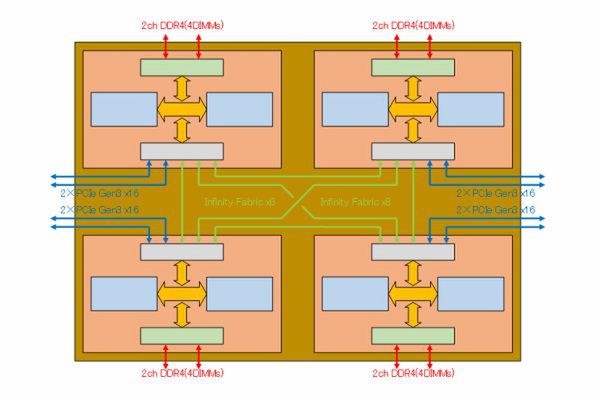
Naplesの内部構造推定図。茶色がMCMのインターポーザーで、その上にRyzen 7のダイが4つ搭載される
このケースでは、各々のダイからメモリーチャンネルが2本づつ、PCI Express Gen3が32レーンづつ出る形になる。それとは別に、各コア間の接続にSerDesをx8レーンを利用しての接続が行なわれていると思われる。
このあたりはOpteronの4ソケット構成に近いのだが、Opteronの場合はプロセッサーあたり3本のHyperTransport Linkが出つつも、うち1本はチップセットの接続に必要で、完全対称型にはできなかったのだが、Naplesの場合はそれぞれのRyzenのダイから外向けのPCI Expressとは別に32レーン分のI/Fがあり、このうちの3本を相互接続に使うことで完全対称型の接続が可能になっていると思われる。
これでは、まだSerDesが8レーン残ってることになるが、AMDによるNaplesのプレビュービデオの1分40秒手前あたりで、「チップセットが要らなくなった」としている。

Naplesのプレビュービデオより。これは以前の2PサーバーがNaplesベースに変身を遂げていく過程の中で出てくる話で、チップセットがすっ飛ばされているのがわかる
上の予想図には示していないが、おそらくNaplesは4つのRyzenのダイ以外にサウスブリッジにあたるI/Oハブも搭載されており、これとダイの間をあまったx8レーンでつなぐのではないかと筆者は考えている。
この方式のメリットは2つある。まず1つ目は将来ラインナップを作りやすいこと。今回はハイエンドの4ダイだが、1/2/3ダイでも同様の構成が可能である。1/2/3ダイの場合、利用できるメモリーチャンネルやPCI Expressレーンに制限が出てくるという問題はあるが、動かないわけではないからだ。
もう1つのメリットは、コスト面に関する話だ。たとえばNaplesを物理的に1ダイで作ろうとすると、さすがにRyzenのダイのそのまま4倍にはならないにしても、3倍ではきついだろう。現実問題として700mm2を超える巨大なダイになるのは間違いない。当然歩留まりは悪いだろう。
MCMで4ダイ構成にすれば、こうした生産面での懸念はかなり減る。あらかじめスクリーニングしてちゃんと動くダイ4つを後工程でMCM化すればいいからで、MCMを利用することに起因するコスト増を勘案しても十分利益が出ると思われる。
ところで、SerDesとPCI Expressが入り混じっているのは意図的である。SerDesそのものは汎用のもので、最近では1レーンあたり56Gbpsもの転送速度を出すものが普通に存在する。これは特にネットワークの分野で、40/50/100/200/400Gbpsのイーサネットの普及が始まりつつあり、さまざまなメーカーが高速なSerDesを用意しようとしていることに対応するためだ。
たとえばCredo Semiconductorは昨年9月、TSMCの28nm/16FF+/16FFCに対応した56/112GbpsのPAM4対応SerDesを発表している。PAM4というのは信号を4値にすることで、1回の転送で2bitを転送できるようにしたものなので、実質的な信号速度は28/56GT/秒になるが、それでも相当早い。
GlobalFoundriesも同様に、56GbpsのPAM4対応SerDesを14LPPの上で提供することを昨年12月に発表しており、こちらも信号速度は28GT/秒になる。この56Gbps対応SerDesをGlobalFoundriesはHSS(High-Speed SerDes)と称しているが、HSSを利用してたとえばPCI Express Gen4やHBMのI/Fなどを作ることも可能としている。
つまり信号速度は最大28GT/秒(カタログによれば30GT/秒あたりまで行けるらしい)というだけで自在に制御でき、またSerDesの手前にプロトコルや変調を入れることで、さまざまな特定プロトコルに対応できるわけだ。
こうした高速なSerDesを複数搭載しておけば、8GT/秒まで速度を落とし64b/66bの変調を入れればPCI Express Gen3として使えるし、Infinity Fabricとして使うときはもっと速度を上げれば、性能を落とさずに接続できることになる。
先の予想図で4つのダイの間を相互接続するInfinity Fabricの速度がどの程度かはわからないが、あくまでシリコンインターポーザーの上で、しかも距離が短いので信号の振幅はかなり小さくても問題ないはずで、30GT/秒程度の信号転送速度は十分確保できるだろう。
8bit幅なら30GB/秒という計算で、もしなんならPAM4変調も入れれば60GB/秒もの帯域が利用できることになる。内部接続としてこれは十分な速度であろう。
2ソケット構成での予想
さて、次は2ソケット構成である。2ソケット構成の場合、PCI Expressレーンを半減させ、あまった分をInfinityFabricとしてソケット間接続に使う形になっている。その場合の接続はどのようになるのかという、これまた筆者の想定図が下の画像となる。
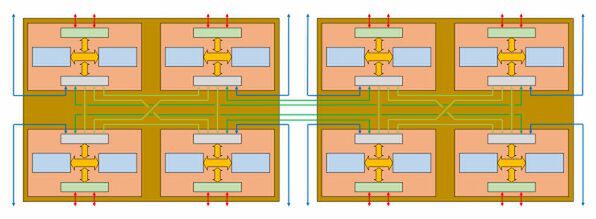
2ソケット構成の場合のNaples想定図
今度はMCM内部ではなくソケット間、つまり一旦ソケットを経由して基板を通り、再びソケット経由でつなぐ構成になる。こうなるとSerDesそのものは56Gbpsと言っていても、信号経路に反射や減衰の影響になりそうなものが多く介在することになるため、どうしても信号速度は落とさざるを得ない。
個人的には、x16レーンをそのまま使い、速度はMCMの場合の半分(たとえばMCM内部が30Gbpsでつながっているとしたら、ソケット間は15Gbps)に落とすのではないかと思う。ただレーン数はx16で内部接続の倍なので、帯域そのものに違いはない。
この場合、それぞれのRyzenのダイはHyperCubeに近い構造でつながることになる。これはマルチプロセッサーを構成する場合に非常に都合が良いというのはかつてスーパーコンピューターの系譜の連載の中でいくつか事例を示して紹介した通りだ。
強いて言うなら、1ソケット内のインターコネクトに比べると、ソケット間のインターコネクトがやや見劣りするが、これはむしろソケット内のインターコネクトが異様にリッチすぎると考えたほうが妥当な気がする。

Naplesは2Pまでを想定しており、4P以上はおそらく考えていないだろう。将来的にはまた話が変わってくるかもしれないが
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第885回
PC
TSMCも次世代「CFET」の全貌を披露! Forksheetスキップの背景と、世界最小6T SRAM実証で見えた2030年への布石 -
第884回
PC
Samsungが次世代CFETの試作に成功! IBMの10万ドル方式に対抗する、量産重視な「一括形成プロセス」のリアリティ -
第883回
PC
TSMCのA16プロセスの詳細が判明! 性能向上の主因はトランジスタではなく裏面電源供給(SPR)にあり? -
第882回
PC
IBMが0.7nmチップの製造に成功! 変態的CFET構造NanoStackの凄みと、あまりに高すぎる製造コストの壁 -
第881回
PC
同一周波数で消費電力18%削減! 進化した「Intel 18A-P」はどこが変わったのか? -
第880回
PC
次世代NVLinkの布石か? TSMCの光電融合技術「COUPE」がもたらすAIサーバーの光接続 -
第879回
PC
なぜAIには「光」が必要なのか? NVIDIAが解説するスケールアップネットワークの低遅延・省電力化戦略 -
第878回
PC
もはや銅配線は限界? 3200Gイーサネット実現に立ちはだかる200GT/秒の壁 -
第877回
PC
「不良品ゼロ」と「水冷NG」の狭間で。ルネサスが明かした車載チップレットSoCのリアル -
第876回
PC
このままではメモリーが燃える! HBM4/5世代に向けた電力供給の限界と、Samsungが示すパッケージ協調設計の解 -
第875回
PC
1000A超のAIプロセッサーをどう動かすか? Googleが実践する垂直給電(VPD)の最前線 - この連載の一覧へ












