




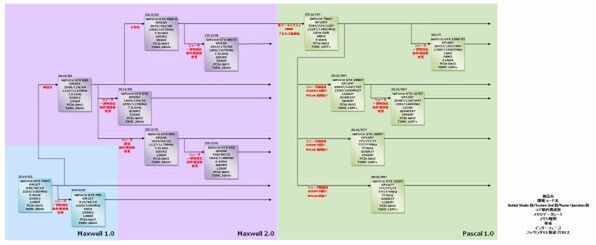
2014年~2017年のNVIDIA GPUロードマップ
GTC 2016で発表された
Tesla P100とDGX-1
ということで、いよいよGTC 2016の発表に移りたい。基調講演は塩田氏のレポートがあるほか、GTCでの発言がNVIDIAのブログに掲載されているので、これらをご覧いただきたいが、大きく5つの発表があった。
このうちここで取り上げるのは、Tesla P100モジュールとDGX-1である。

Tesla P100モジュールは、ほぼ内容のすべてがこの1枚に納まっているというべきか。基調講演のスライドより

DGX-1は、見た感じの高さは2U(高さ3.5インチ:1Uが1.75インチに相当)に見えるが、実際は3Uとのこと
※追記:記事掲載後、NVIIDAより高さは3Uとの指摘をいただきました。記事を訂正してお詫びします。(2016年4月14日)
Tesla P100はPascalコアと4つのHBM2メモリーを搭載したチップを、モジュール(先の画像ではSMX 2.0という仮称だったが、正式名称は不明)に搭載したもので、ここにもはっきり“HYPERSCALE DATACENTER GPU EVER BUILD”とあるようにデータセンター向けのものである。
前回のアップデートでも書いた通り、Tesla P100の最初の納入先はSummit/Sierraというスパコン向けで、これに続きほかにもいくつかのスパコン向けがある。
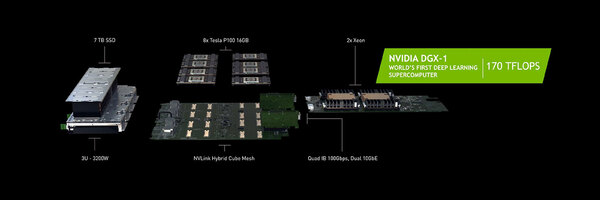
DGX-1そのものは単体サーバーであるが、おそらくSummit/Sierraに採用されるものも、これに似た構造になる(ただしCPUはPower)と思われる
おまけにDGX-1向けにもある程度の数を確保しなければならない。ダイサイズは驚きの610mm2に達しており、当然歩留まりが悪いので、本来は60個のSMs(Streaming Multiprocessors)を実装できるにも関わらず、うち4つをスペアに回した56個のSMとすることで歩留まり改善の方策を採っているが、これでどの程度歩留まりが上がるのかははっきりしない。
というわけで、やはりGeForce Titanの後継製品はかなり後にならないと登場しないと思われる。一応図では2016年10月と書いたが、これは多分に希望的観測であり、2017年までずれ込んでも不思議ではない。
さて、このTesla P100モジュールを搭載したサーバーBoxがDGX-1である。“250 servers in-a-box”とあるが、べつにP100モジュールが250枚入ってるわけでなく(もし250枚入ってて12万9千ドルだったら、超バーゲンプライスである。なにせ1枚「たった」516ドル相当だからだ)、合計性能が通常のサーバーの250台分に相当するの意味である。
内部は8枚のP100モジュールと、Dual Xeon搭載のカード、7TBのSSD、3ユニットで合計3200Wの電源、それとQuad InfinibandのI/F(100Gbps)と10GbEのI/F×2から構成されるものだ。さすがにこれは間違いなくHPC向けという扱いになる。
昨年のGTCでNVIDIAはDIGITS DevBoxというGeForce GTX Titan Xを4枚を搭載したワークステーションを発表したが、これの高性能版という位置付けになる。
基調講演でもいろいろわかったわけだが、もう少し細かい話が“Inside Pascal”というテクニカルセッションで披露された。ただ残念ながらまだセッション資料がアップロードされていない。
幸いにもこの内容のダイジェストとセッション資料の縮小版がNVIDIAのブログに掲載されているので、こちらを引用しながらもう少し話を説明したい。
まず最小構成だ。KeplerではSMX(SM eXtreme)が1つの固まりに、Maxwellではこれを内部四分割したSMM(Maxwell SM)になっている。SMXとSMMの内部構造を下の画像に示す。

SMXの内部構造
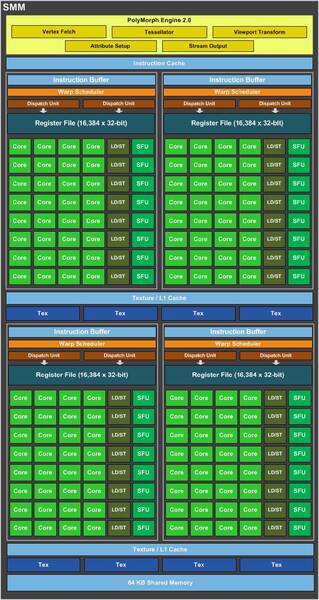
SMMの内部構造
SMXの場合、12つのコア(単精度演算ユニット)と4つのDP Unit(倍精度演算ユニット)、2つのLD/ST(Load Store Unit)、2つのSFU((Special Function Unit:特殊演算ユニット)がペアになっている。これを16ペアまとめており、1つのSMXには合計192のコアと64個のDP Unit、32個のLD/ST、32個のSFUが搭載されていた形だ。
一方SMMは4つのコアとLD/ST、SFUのペア8つで一塊になり、これが4つで1つのSMMを構成する。つまり1つのSMMには128のコアと32個のLD/ST、32個のSFUという計算になる。
対してPascalでは、4つのコアと2つのDP Unit(倍精度演算ユニット)、1つのLD/ST、1つのSFUがペアになっており、これを8個ならべた塊が2つでSMとなる。つまり1つのSMあたり、コアが64個、DP Unitが32個、LD/STが16個、SFUが16個という計算になる。
KeplerのSMX、およびMaxwellのSMMと比較すると、以下の違いがある。
- DP Unitがコアの半分の比率で搭載された:倍精度演算が、単精度演算のほぼ半分の速度で可能(昨年の発表では12TFLOPS vs 4TFLOPSで1/3相当だったため、だいぶブーストされた計算になる)。ちなみにMaxwellはそもそもDP Unitを持っていないし、Keplerはコア:DP Unitの比が3:1であり、昨年の発表はこれに準じたのかもしれない。
- LD/STの増強:LD/ST(ロードストアユニット)がKeplerの5割増になっており、より多くのメモリー帯域を利用できるようになった(Maxwellとは同等)。
- SMの粒度を微細化:KeplerではSMX全体で1つ、MaxwellではSMMの中を4分割としたが、PascalではSMのサイズそのものを半分に減らした。

ちなみにこのSMを10個まとめた塊がGPC(Graphics Processing Clusters)と呼ばれる。Tesla P100ではこのGPCを合計6個搭載する
ややわかりにくいが、Keplar世代では1つのSMX(つまり192個のコア)あたり、Warp Schedulerが4つ、Dispatch Unitが8つという形になっていた。Maxwellでは128コアあたり、Warp Schedulerが4つ、Dispatch Unitが8つとなっている。
これに対してPascal世代では64コアあたりWarp Schedulerが2つ、Dispatch Unitが4つとなっている。したがって仮に192コア相当で比較した場合、下の表のようになっている。
| 192コア相当で比較した場合のWarp SchedulerとDispatch Unitの数 | ||
|---|---|---|
| Warp Scheduler | Dispatch Unit | |
| Kepler | 4基 | 8基 |
| Maxwell | 6基 | 12基 |
| Pascal | 6基 | 12基 |
Warp、というのはNVIDIA用語で、GPUのコア上で動かすスレッド(処理の流れ)を32本(つまり32スレッド)束ねたものであり、Dispatch UnitはどのWarpを実際にコアで動かすかを決める部分である。要するにMaxwell/Pascalでは、Keplerの1.5倍の数のスレッドを同時に発行できることになる。
では、PascalはMaxwellと同等の効率なのか? というと、細かく効率を上げるための工夫がなされている。それはRegister FileとShared Memoryのサイズである。こちらを比較すると以下のようになっている。
| Register FileとShared Memoryのサイズ | ||
|---|---|---|
| Register File | Shared Memory | |
| Kepler | 64K/8 Dispatch | 64KB/8 Dispatch |
| Maxwell | 64K/8 Dispatch | 64KB/8 Dispatch |
| Pascal | 64K/4 Dispatch | 64KB/4 Dispatch |
Register Fileは、各々のWarp内のスレッドが直接演算のために利用するもの、Shared Memoryはすべてのスレッドで共有できるメモリー領域(1次キャッシュとしても利用可)であるが、Kepler/Maxwellは8Warpあたり6万5536個、つまり1Warpあたり8192個、スレッドあたり256個のRegister Fileが利用できるのに対し、Pascalではこれが倍増している計算だ。
利用できるShared Memory量も同じようにKepler/Maxwellが256Byte/スレッドなのに対し、Pascalでは512Bytes/スレッドまで利用可能である。要するにPascalはKeplerと比較すると(同じコア数なら)スレッド数が1.5倍稼動できる。
Maxwellと比較すると同等であるが、利用できるRegister FileやShared Memoryの量が倍増しているので、より長時間メモリー待ちに陥らずに稼動させ続けることが可能だ。これにより、Keplerは元よりMaxwellと比較しても実行効率を大幅に改善していると思われる。
※お詫びと訂正:記事初出時、Maxwellのコア数が192とありましたが、正しくは128となります。記事を訂正してお詫びします。(2016年4月14日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















