




Blue Gene/Lの回の最後で、Blue Gene/Pと一緒にBlue Gene/Cの話を少しだけ触れたが、今回のスーパーコンピューターの系譜では、このBlue Gene/CことCyclops64を取り上げたい。
Blue Gene/L→Blue Gene/Pの開発は、CPUコアとFPUを若干強化し、Blue Gene/Lで問題だった部分を修正/改良した程度で、むしろプロセスの微細化により、消費電力を下げてより高い密度でプロセッサーを集約できるようにしたのが最大の違いである。
ただし逆に言えば、性能/消費電力の改善はもっぱらプロセスの微細化「だけ」に頼った、という言い方もできる。もう少し思い切った性能改善の方法はないものか? ということで、Blue Geneシリーズの一環の研究プロジェクトとして始まったのが、Cyclops64である。
当初はBlue Gene/Cと呼ばれていたはずだが、これがCyclops64に名前が変わった理由はよくわからない。ただ研究を進めていく過程で明らかに既存のBlue Gene系列と異なるアーキテクチャーになってしまったので、誤解を招かないように名称が変わったのかもしれない。
ちなみに、このCyclops64はBlue Gene系列とやや異なり、IBMの単独開発ではなく、米エネルギー省(ここがプロジェクトの出資元)、米国防省、IBMを含むいくつかの企業、それと大学(デラウェア大など)の共同プロジェクトとなっている。
ではどう思い切った改善をしようとしたか? という話であるが、まず最初にここからスタートした。ここでType II、つまり多数のコアを実装するというアイディアは、以下の原理から生まれている。

Cyclops64開発のきっかけ。Type Iは既存の延長であり、Type IIは全く新しい構成にするという話
- Flops are cheap!
(演算性能の実現には、さほど費用がかからない!)
- Memory per core is small
(コアあたりのメモリー量が少なすぎ)
- Cache-coherence is expensive
(キャッシュコヒーレンシを実装するのは高くつく)
- On-chip bandwidth can be enormous!
(チップ間転送速度はもっと巨大化できる!)
ちなみにこの4つも上の画像と同じ論文からのものである。具体例として、例えば130nmプロセス/1GHz動作で製造した場合、64bitのFPUそのものは1mm2未満に収まり、その電力もたかだか演算1回あたり50pJ(ピコ・ジュール)に納まる。したがって、14×14mmのダイ(~200mm2)に200個のFPUを収めることすら可能である。

内部のレジスター演算だけであれば、1演算あたり10pJ程度で済むが、オンチップのグローバルメモリーでは1nJ(=1000pJ)と100倍に増え、外部メモリーを利用するとさらに消費電力が増える
問題は、その演算に必要なデータのやり取りに、大きな消費電力がかかることで、これがコストとなって跳ね返る。ではどうするかといえば、上に挙げた4つの原理に忠実なチップを作ればいい。そうして設計されたのがCyclops64である。

Cyclops64のプロッッサー概要。TUはThread Unitで整数演算ユニット、SPはScratch Pad、GMはGlobal Memoryの意味である
上の画像の右側に説明があるが、メインになるのは1命令実行のシンプルなRISCコアである。ただし同時に2スレッドを実行できようにしているのは、おそらくメモリーアクセス待ちなどを考慮したためだろう。
スレッド構成が“non-preemptive”とあるので、あるスレッドが実行中にメモリーアクセス待ちなどで待機状態に入ると、もう1つのスレッドに制御が切り替わる構成と思われる。
TUは図では2つ書かれているが、実際にはインテルのハイパー・スレッディングなどと同様に、一部のレジスター類などが2スレッド分用意され、処理パイプラインそのものは1本と思われる。この2つのTUに1つのFPUを組み合わせている。
またコアにはシンプルなスクラッチパッドがスレッド毎に用意されている。このスクラッチパッドの容量は16KBで、レジスターよりやや遅い(読み込みに2サイクル、書き込みに1サイクル)とされる。
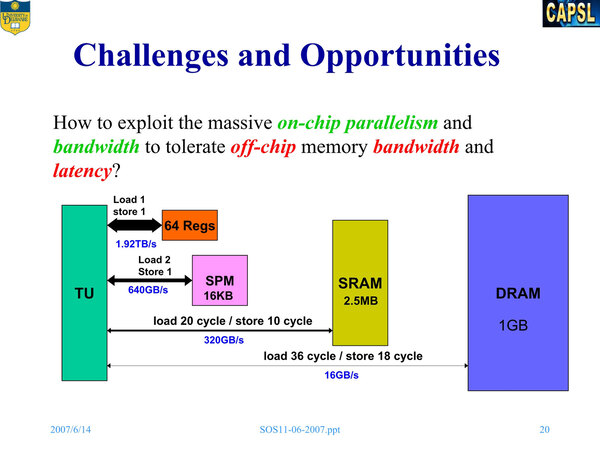
SRAMが2.5MBという計算になる理由がよくわからないが、160wayのSRAMバンクを80本のクロスバー接続で共有しているためら、一度にアクセスできるメモリー量は半分という意味なのだろうか?
これとは別に、グローバル・メモリーが32KB×2装備されている。こちらは名前の通り、C64チップ上のすべてのスレッドからアクセス可能である。
前述のプロッッサー概要の画像では、コアと一体化しているようにも見えるが、ちょうどCore iシリーズのLLCのような形で、クロスバーとのリンクは共有しているが、実体としては別に実装されているようだ。結果、グローバル・メモリーは160wayの32KBで合計5120KB実装されている計算になる。
キャッシュとしては、プロッッサー概要の画像の右上にicache-5Pというユニットが4つづつ4組で合計16個搭載されているのがわかる。これはもう名前の通り、命令キャッシュである。5つのプロセッサーコアあたり1つの32KB命令キャッシュが搭載される。
一方、データキャッシュは存在しない。これは設計原理の“Cache-coherence is expensive”に従ったものだ。データキャッシュを持つと、当然キャッシュコヒーレンシは実装しないわけにはいかないからだ。
データキャッシュを省く代わりにグローバル・メモリーをコアのそばに置くことで、アクセス性能をそう悪化させずにキャッシュコヒーレンシを省く、というトレードオフが行なわれた。
この80個のコアはクロスバーで相互接続され、さらにi-Cacheのほか、4chのDDR2 SDRAMのI/F、ノード間接続用のA-Switch、さらにI/Oや管理用のHost I/Fなどもクロスバーにつながる形である。
インテルは2007年に80コアの試作チップを発表したが、こちらはSRAMをシリコン貫通VIAを使って積層するという冒険的な構成だったのに対し、Cyclops64はもう少し現実的な構成を取っていることがわかる。
Cyclops64の演算性能は
Blue Gene/Qとさほど変わらず
Cyclops64コアは500MHz駆動を想定しており、FPUはMAC演算を1サイクルで実行できるため、1コアあたり1GFLOPS、80コア全体で80GFLOPSの性能を持つ。
このチップと外付けで1GBのメモリー、IDEのHDD、その他(管理用のギガビットイーサや、ノード間接続用のI/F)をまとめて1枚の基板に収めることで1ノードが構成される。
ノードを合計48枚装着したバックプレーン3つで1つのキャビネットを構成し、このキャビネットを96個並べて、1.1PFLOPSのシステムを作る、というのが当初の想定であった。
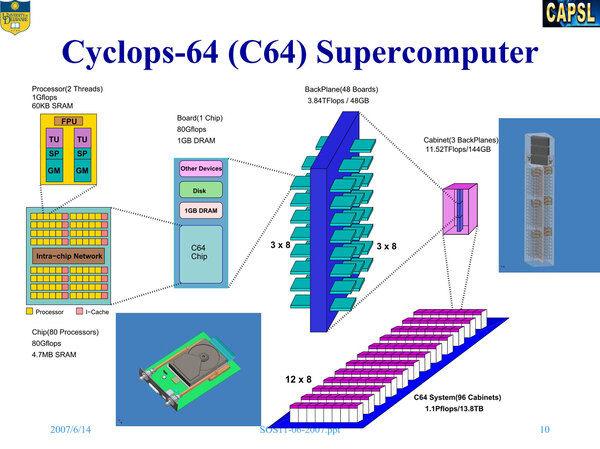
左下のボードの絵を見ると、手前に2つのパイプが引き出されているが、どうもこれは液冷用の配管の模様。右上にキャビネットの図があるが、上に3つ縦置きされた黒いものが液冷用の熱交換器と思われる
のちに構成はやや変更され、1枚のボードには4つのCyclops64チップと合計4GBのメモリーが搭載され、このボード48枚×3で1つのキャビネットを構成、キャビネット72本で1.1PFLOPSのシステムとされた。
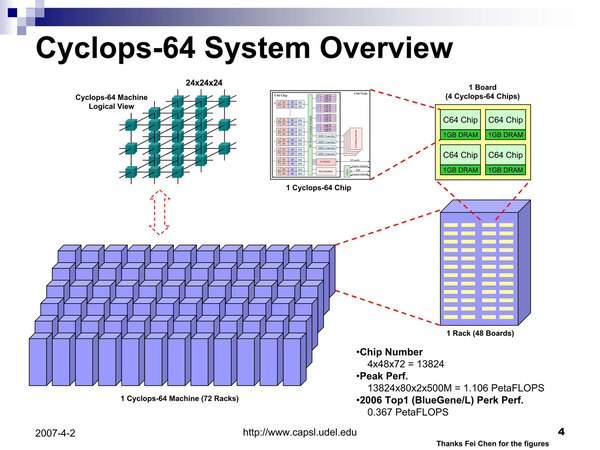
1枚のボード上に多くのチップを搭載すれば、通信のレイテンシーはバックプレーンを通すよりは高速化できるし、集積度も上がるのでメリットが大きいと思われたのかもしれない。また、すべてのノードにHDD(しかもIDE!)を搭載するのはメンテナンス上賢明ではないという判断も生まれたのだろう
Blue Gene/Lがキャビネット64本で367TFLOPS、Cyclops64はキャビネット72本で1106TFLOPSなので、あまり改善したという気はしない。実際Blue Gene/Qはキャビネット72本で1002.7TFLOPSという性能なので、どっこいどっこいというところ。
ただCyclops64とBlue Gene/Lは130nmプロセス、Blue Gene/Pは90nmプロセスなので、Cyclops64も90nmプロセスを利用すれば、もう少し動作周波数を上げつつ、消費電力を下げてBlue Gene/Pを上回る性能を出せたかも知れないが、Cyclops64開発のきっかけであったType IIのアーキテクチャーのメリットが出せたか、と問われると微妙なところではある。
※お詫びと訂正:記事初出時J(ジュール)の単位に誤りがありました。記事を訂正してお詫びします。(2015年3月22日)
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ



















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































