




AMDの1コアはインテルよりトランジスターが多い?
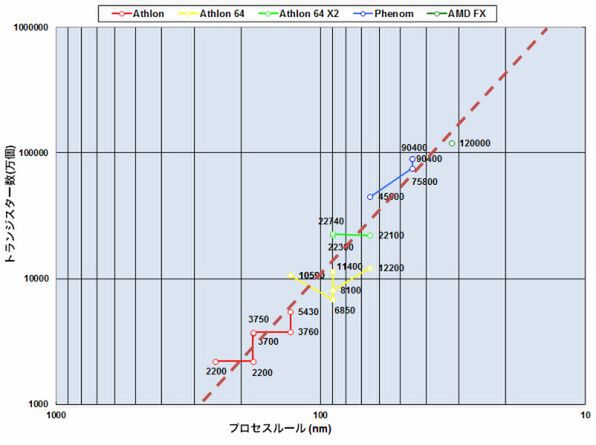
グラフ3 プロセスルールと総トランジスター数の変化
一方でCTIにあまり影響されないのが、総トランジスター数の変化だ(グラフ3)。こちらはプロセスの微細化にあわせて順調(?)に増加傾向にある。Bulldozerに関しては、2011年12月に「総トランジスター数を20億個から12億個に引き下げる」という発表があった。一次近似の直線(朱色の破線)で見ると、本来32nm世代なら15~16億程度になりそうな計算なので、おおむねこの範囲ということになる。
問題は、「これ以上トランジスター数を増やせるのか?」ということ。32nm SOIのままでトランジスター数を大幅に増やすのは、ダイサイズと消費電力の両面でかなりきつい。28nm世代まで行けば20億個位までトランジスター数が増やせるので、次の世代まではトランジスター数は増えないだろう、と想像される。
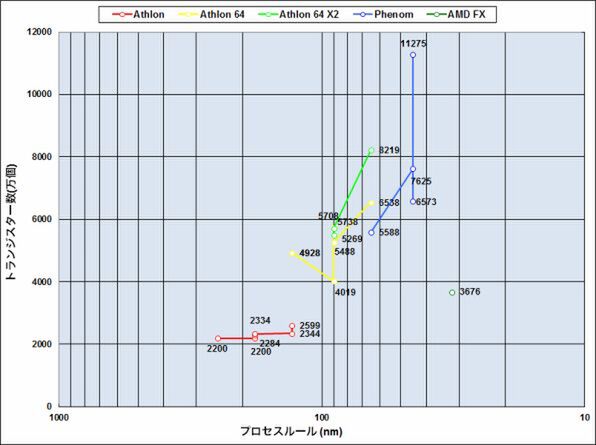
グラフ4 プロセスルールとコアあたりトランジスター数の変化
グラフ4は1コアあたりトランジスター数の概算である。冒頭で書いたとおり、今回はLlano/Trinityを入れていないので、計算式は以下のようになる。ちなみにAMDの場合は共有2次キャッシュを使わず、コアごとに独自の2次キャッシュが搭載されているが、一応これも外して算出した。
- (総トランジスター数-2次/3次キャッシュのトランジスター数)÷コア数
K7(Athlon)の世代は、おおむね2200万~2500万トランジスター程度で推移していた。これがAthlon 64以降で大幅に増えているのは、メモリーコントローラーやHyperTransportリンクの分が増えたからである。ではこれを除くとどの程度になるかは、実は90nmの世代だと比較的算出しやすい。
1ページ目の表1から関連項目を抜き出して見る。
- Orleans(1コア、2次 512KB):8100万トランジスター
- San Diego(1コア、2次 1024KB):1億1400万トランジスター
- Windsor(2コア、2次 1024KB):2億2740万トランジスター
WindsorとSan Diegoの差は1コア+2次キャッシュの1024KBとなり、これで1億1340万トランジスターとなる。一方San DiegoとOrleansの差は2次キャッシュ 512KB。その差が3300万トランジスターなので、2次キャッシュ 1MBを構成するのに必要なトランジスター数は6600万トランジスターとなり、純粋に1コア分のトランジスター数は以下のようになる。
- 1億1340万個 - 6600万個 = 4740万個
グラフ4の試算はラフなので、トランジスター数が多少多めに出ることは間違いない。しかし、前回のインテルのグラフ5と比較すると、大幅にトランジスター数が多いことが見て取れる。
ちなみにPhenom世代では、特にZosmaが1億1275万個と、異様にトランジスター数が多くなっている。これは、ZosmaはThubanと同じ6コアのダイを使いながら、2コアを無効化して4コアにしているために数字が跳ね上がって見えているだけで、実際はThubanと同じ6500万トランジスター/コア程度になっている。一方で、Bulldozerが3700万個程度に収まっているのは、2コアでFPUやデコーダを共有しているからだ。逆に言えば、こうした共有をしてもまだ1コア3700万個という、大きな数字になっているわけだ。
これらのグラフを眺めてみると、全体的にAMDはコアに費やすトランジスター数が、インテルより多めというのが一貫した傾向である。これはトランジスター数を容易に増やしにくい昨今の状況では、性能改善のボトルネックになりそうに思える。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















