




CTIの効果が最もあったのは、90nm世代だろう。最初に登場したD Steppingの「Winchester」コアは、動作周波数こそ2.2GHz止まりだったが、消費電力を大幅に改善したコアだった。これに続くE Steppingの「San Diego」を経て、最終的に90nm世代はF SteppingのWindsorまで改善を続けた。Windsorはコア数を2倍に増やしながら、動作周波数も3.2GHzまで引き上げることに成功しており、同一プロセスでトータル性能を3倍近くまで引き上げていた。
AMDとインテルでの
プロセス改善に対する取り組みの違い
こうした改善はインテルではありえない。インテルの場合「Copy Exactly」(厳密に同一なコピー)という方法で、同一プロセスの製造を複数のファブで行なっているからだ。例えば90nmの場合、インテルはまずオレゴン州にある「D1X」という量産技術開発用のファブで、量産技術を開発している。ここで90nmの量産技術を確立して、ある程度の歩留まりが実現できるようになったら、その技術をそのまま他のファブ、90nm世代では同じオレゴン州の「D1C」「D1D」、ニューメキシコ州の「Fab 11X」、アリゾナ州の「Fab 12」、さらにアイルランドの「Fab 24」に持ち込んで、そっくり同じように量産している。
こうした状況では、例えば「もう少し90nmトランジスターの性能を改善する方法が見つかった」と言っても、これをすべてのファブに適用させるには時間がかかる。また、基本として改善の作業はD1Xが行なうが、D1Xは90nmの量産技術が確立したら、次は65nmの量産技術に取り組む※1。いつまでも90nmの改良には携わっていられない。
※1 実際は複数世代の開発が、多少オーバーラップしながら進められている。
そんなわけでインテルでは、あるプロセス世代の技術を延々と改善するというケースは稀で、次世代プロセスをさっさと確立してそちらに移行する方が普通である。結果として、インテルでもしばしばあるステッピング変更は、プロセスそのものは同一であり、回路側を改変している。AMDのように、回路側とプロセスの両方を変更するというのは、インテルではありえない。
こうしたCTIによる性能改善が、AMDでのプロセスと最高動作周波数の関係を、非常にわかりにくくしているのは間違いないだろう。しかし漸近線を引いてみて意外に思ったのは、「Bulldozer」コアのAMD-FX(Zambezi)の動作周波数が、漸近線からそれほど大きくは離れていないことだ。インテル版の同じグラフでの、Pentium 4の乖離具合と比較すると、ずいぶんまともだ。
だが現時点では、Bulldozerの第2世代である「Piledriver」コアがどこまで周波数が伸びるかがちょっと予想できない。これは、AMDが製造部門をGLOBALFOUNDRIES社として分離してしまっているため、CTIがどこまで現在でも継承されているか不明なためだ。ただしPiledriver世代では、例えば連載141回で取り上げた新技術の導入もあり、最大動作周波数は32nm SOIプロセスのままでも、5GHz近くまでは伸びるかもしれない。もっとも5GHzに到達するのは、32nm SOIよりもう少し微細化した先になりそうだと考えている。
Phenom II以前と以後で変わった
AMD CPUのダイサイズ
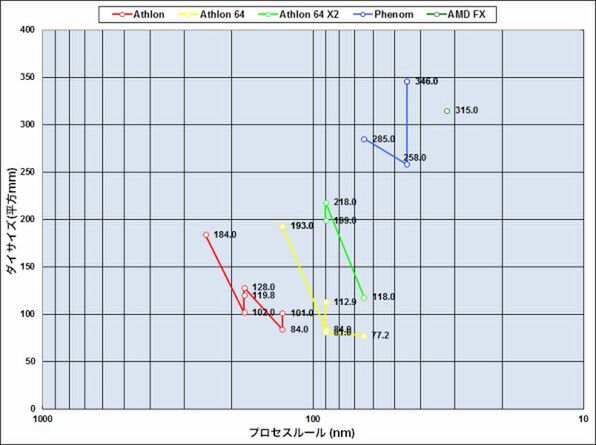
グラフ2 プロセスルールとダイサイズの変化
次のグラフ2は、プロセスとダイサイズの関係を比較したものだ。Athlon 64 X2までの世代では、なんとかしてダイサイズを200mm2以下に抑えよう、という努力が明白だった。Athlon 64 X2の世代では200mm2を超える製品もあったが、最終的には118mm2まで縮小するなど、この200mm2をひとつの敷居にしたいという傾向が明白で、可能なら100mm2以下に抑えたかったようだ。
ところがPhenom II以降は、「300mm2前後でも構わない」という方向へと、AMDの方針が明確に切り替わったのがわかる。ここにはPhenom II X2やAthlon X2などの2コア製品はプロットしていない。実はこうした2コアの製品も、当初は4コアのダイをそのまま利用して出荷しており、後追いでAthlon II X4(169mm2)やAthlon II X2(117.5mm2)といった製品が投入されている。Athlon II X4/X2はAMDのラインナップではバリュー市場向けなので、原価を下げないと商売にならないのだろうが、メインストリーム向けは200mm2を超えるダイで構わない、という割り切りがあるように思える。
同じくグラフ2にはプロットしていないが、Llanoもダイサイズは228mm2と大きい。Trinityはダイサイズが明示されていないが、Llanoよりやや大きい程度なので、おおむね200~250mm2の範囲に納まっている。4コア化やGPU統合といった対応にあわせて、インテルのグラフと比較してもダイサイズが大きめになることを、「それでも良し」と割り切っているようだ。
この連載の記事
-
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 -
第757回
PC
「RISC-VはArmに劣る」と主張し猛烈な批判にあうArm RISC-Vプロセッサー遍歴 - この連載の一覧へ






が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")





























