




前回はインテルのプロセス技術を軸に、CPU実装の変化を比較してみた。今回はAMDである。対象としたのは表の5グループ20製品である。
| K7からZambeziまでのAMD CPUの変遷 | ||||||||
|---|---|---|---|---|---|---|---|---|
| 製品グループ | コード名 | プロセス(nm) | 最高周波数(GHz) | ダイサイズ(mm2) | 総トランジスター数(万個) | コア数 | 2次キャッシュ(KB) | 3次キャッシュ(KB) |
| Athlon | K7 | 250 | 0.70 | 184.0 | 2200 | 1 | - | - |
| K75 | 180 | 1.00 | 102.0 | 2200 | 1 | - | - | |
| Thunderbird | 180 | 1.40 | 119.8 | 3700 | 1 | 256 | - | |
| Palomino | 180 | 1.73 | 128.0 | 3750 | 1 | 256 | - | |
| Thoroughbred | 130 | 2.20 | 84.0 | 3760 | 1 | 256 | - | |
| Barton | 130 | 2.20 | 101.0 | 5430 | 1 | 512 | - | |
| Athlon 64 | SledgeHammer | 130 | 2.40 | 193.0 | 10590 | 1 | 1024 | - |
| ClawHammer | 130 | 2.60 | 193.0 | 10590 | 1 | 1024 | - | |
| Winchester | 90 | 2.20 | 84.0 | 6850 | 1 | 512 | - | |
| San Diego | 90 | 2.60 | 112.9 | 11400 | 1 | 1024 | - | |
| Orleans | 90 | 2.60 | 81.0 | 8100 | 1 | 512 | - | |
| Lima | 65 | 2.80 | 77.2 | 12200 | 1 | 1024 | - | |
| Athlon 64 X2 | Toledo | 90 | 2.60 | 199.0 | 22300 | 2 | 2048 | - |
| Windsor | 90 | 3.20 | 218.0 | 22740 | 2 | 2048 | - | |
| Brisbane | 65 | 3.10 | 118.0 | 22100 | 2 | 1024 | - | |
| Phenom | Agena | 65 | 2.60 | 285.0 | 45000 | 4 | 2048 | 2048 |
| Deneb | 45 | 3.70 | 258.0 | 75800 | 4 | 2048 | 6144 | |
| Zosma | 45 | 3.50 | 346.0 | 90400 | 4 | 2048 | 6144 | |
| Thuban | 45 | 3.70 | 346.0 | 90400 | 6 | 3072 | 6144 | |
| AMD FX | Zambezi | 32 | 4.50 | 315.0 | 120000 | 8 | 8192 | 8192 |
「K6」を入れるべきか迷ったのだが、AMDの場合「K7」の世代と「K8」の世代でプロセス技術の断絶がある関係で、メインと言えばK8以降のSOIプロセスであろう。比較対照用にK7は入れたが、K6世代の説明は省略している。またAPUの「Llano」「Trinity」は、総トランジスター数こそ公開されているが、GPUの分がまるで不明である。しかもTrinityはまだモバイル向けのみ公開されていて、デスクトップ向けの動作周波数が不明なので、こちらも除外した。
CTIにより、同じプロセス世代でも
改善を続けるAMDの方針
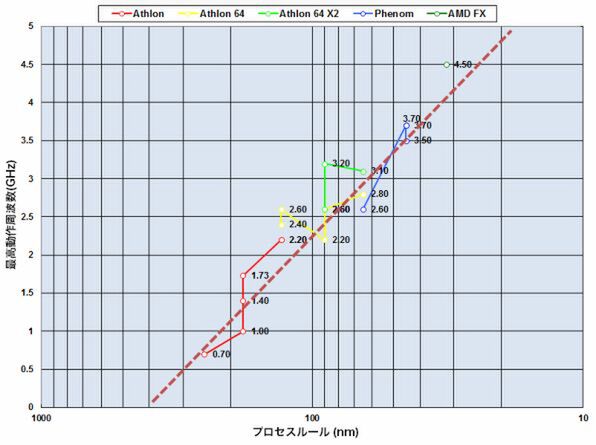
グラフ1 プロセスルールと最高動作周波数の変化
まずはプロセスと最高動作周波数の関係を見てみよう(グラフ1)。朱色の破線は前回同様に一次近似を取ってみたものだが、意味が見出せないというか、長期的には直線近似っぽくはなっているが、あまりあてにならない。その理由は「CTI」(Continuous Transistor Improvement)による改善である。CTIというのは、あるプロセスノード(この例なら90nm)が立ち上がったあとでも、引き続きプロセスを改善し続ける技法である。
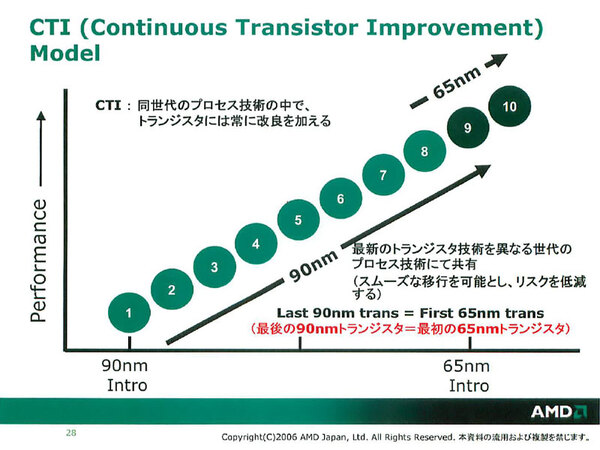
AMDによる「CTI」の説明図。継続してプロセスを改善すること(2006年1月の記者説明会資料より引用)
グラフ1で言えば、例えば180nmプロセスを使うAthlonグループの、「K75」から「Palomino」への変化からこの傾向を見て取れる。130nm SOIを使う「SledgeHammer」から「ClawHammer」(Athlon 64グループ)、90nm SOIを使う「Winchester」から「Orleans」まで(同じくAthlon 64)、「Toledo」から「Windosor」(Athlon 64 X2)までも同様だ。
またグラフ1からは読みにくいが、45nm SOIを使うPhenomグループの「Deneb」から「Thuran」までも、動作周波数こそ上がっていないがコアの数が「4」から「6」へと1.5倍に増えているあたり、トランジスターの改善があったことがうかがえる。
この連載の記事
-
第768回
PC
AIアクセラレーター「Gaudi 3」の性能は前世代の2~4倍 インテル CPUロードマップ -
第767回
PC
Lunar LakeはWindows 12の要件である40TOPSを超えるNPU性能 インテル CPUロードマップ -
第766回
デジタル
Instinct MI300のI/OダイはXCDとCCDのどちらにも搭載できる驚きの構造 AMD GPUロードマップ -
第765回
PC
GB200 Grace Blackwell SuperchipのTDPは1200W NVIDIA GPUロードマップ -
第764回
PC
B100は1ダイあたりの性能がH100を下回るがAI性能はH100の5倍 NVIDIA GPUロードマップ -
第763回
PC
FDD/HDDをつなぐため急速に普及したSASI 消え去ったI/F史 -
第762回
PC
測定器やFDDなどどんな機器も接続できたGPIB 消え去ったI/F史 -
第761回
PC
Intel 14Aの量産は2年遅れの2028年? 半導体生産2位を目指すインテル インテル CPUロードマップ -
第760回
PC
14nmを再構築したIntel 12が2027年に登場すればおもしろいことになりそう インテル CPUロードマップ -
第759回
PC
プリンター接続で業界標準になったセントロニクスI/F 消え去ったI/F史 -
第758回
PC
モデムをつなぐのに必要だったRS-232-CというシリアルI/F 消え去ったI/F史 - この連載の一覧へ








が四角い地球を襲う!5月23日発売『デジボク地球防衛軍2(略)』の魅力をチェック")






















