




2010年にOpteronは
Socket C32とSocket G34に切り替わる
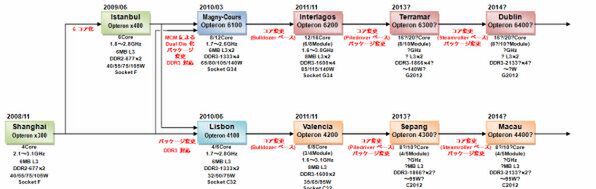
AMD サーバーCPUの2008~2014年にかけてのロードマップ
2010年3月に、Opteronは製品ラインナップを整理。「Opteron 6000」シリーズと「Opteron 4000」シリーズに編成された。最初に登場したのは、MCM構造を取った8/12コアの「Opteron 6100」シリーズ。それから3ヵ月ほど遅れて、MCMではない「Opteron 4100」シリーズが投入されている。
これらの製品に使われているコアは、既存のShanghai/Istanbulコアそのままである。特に「Lisbon」の場合、既存のOpteron x300/x400シリーズとの差は以下の2点だけだ。
- DDR3メモリーをサポート
- パッケージを「Socket C32」に変更
C32は1、2プロセッサー構成用ということで、HyperTransport Linkは2本のみとされ、うち1本がCPU同士の接続に、もう1本はチップセットとの接続用とされる(図1)。
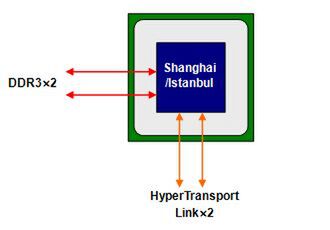
図1 Socket C32タイプOpteronのメモリーインターフェースとHyperTransport Linkの構造
他方で、「Socket G34」は2、4プロセッサー構成用となっており、こちらは2つのダイをパッケージ上に搭載して、ダイ間を2本のHyperTransport Linkでつなぐという構成になっている(図2)。
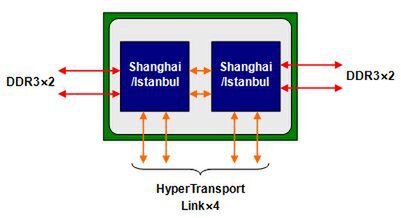
図2 Socket G34タイプOpteronのメモリーインターフェースとHyperTransport Linkの構造
ちなみにこのHyperTransport Linkは、片方がx16でもう片方はx8という構成になっている。もともと「Barcelona」(2007年のクアッドコアOpteron)以降のダイは、x16のHyperTransport Linkを4本搭載し、これをx8×8として使うことも可能だった。そのため、この構成だと本来ならx8 Linkが両方のダイで1本ずつ余るはずだが、これを無理に使うのはやめたようだ。
また、結果としてHyperTransport Linkが4本ずつ出ているので、これを使えば8プロセッサー以上の構成も可能であるが、現実問題として4プロセッサーまでで制限されている。これはHyperTransport Linkがプロセッサーの数(厳密に言えばノード数)を3bitで管理しており、図2の構成だとひとつのパッケージに2つのノードがある計算になるので、4プロセッサー構成でノード数の上限に達してしまうからである。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ






































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





























