





SSEに関する改良点の説明。なぜ64bit幅だったかというと、「MMX」や「3DNow!」といった64bit SIMD命令用のユニットに、SSEを追加する形で実装したから
次のポイントは128bit SSE動作だ。元々SSE自身は128bitの演算命令で、これにあわせてSSEレジスターも128bit幅となっている。だが、これまでは64bitの演算器を2つ組み合わせて処理していた。これを128bit幅に拡張することで、SSE命令の処理性能を改善するという話である。上の図でもわかるとおり、SSE周りの回路はおおむね倍の規模となっている。もっとも、FPUと異なりSSEではそれほど複雑な浮動小数点演算を行なうわけではないので、これによってダイサイズが大きく膨らむわけではない。
DRAMに関しては、「Griffon」こと「Turion X2」で導入された「Independent DRAM Controllerモード」を搭載している。ほかにもメモリーコントローラー周りを再設計するとともに、バースト転送動作の高速化や、ハードウェアプリフェッチの増設などを行なっている。

「Independent DRAM Controller」についての解説。2チャンネルのDRAMを同期して動かすか、非同期で動かすかを選択できるもの。Ganged Mode/Unganged Modeなどと呼ばれることもある
もっともこの時点でのプリフェッチとは、直前にアクセスされたアドレスを元に、プリフェッチ対象アドレスを推定するアドレスベースの技術だ。命令を解釈してプリフェッチ対象を推定する、「IPベースプリフェッチ」が搭載されるのは「Llano」までお預けとなっている。
3次キャッシュの搭載は当初から推定されていた。だがAMDの場合、ダイサイズに占めるコアの割合が高く、また製品競争力的にインテルほどアグレッシブな価格をつけることができないため、あまりダイサイズを大きくできない。この結果、インテルが2006年に投入した「Conroe」(初代Core 2 Duo)では4MB、2007年の「Penryn」(2代目Core 2 Duo)では6MBもの共有2次キャッシュを搭載したのに対して、Barcelonaの共有3次キャッシュ容量は2MBにすぎない。
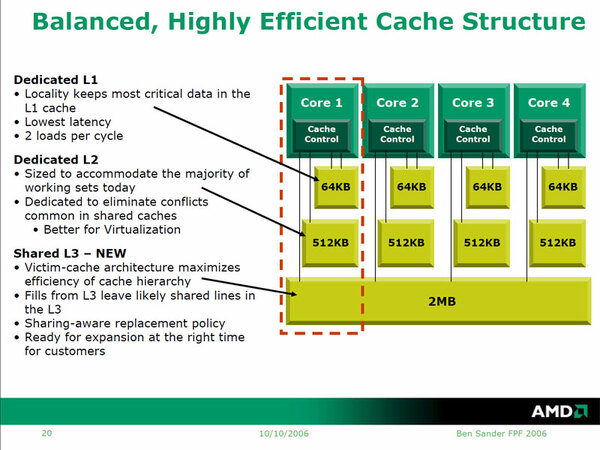
Barcelonaのキャッシュ構成。各コアの2次キャッシュを128KB~256KB程度に抑えて、3次キャッシュを4MB程度のInclusive構成にするというアイデアも試されたとは思われる。しかし2次キャッシュに手を入れると面倒なことになるという判断からか採用されなかった
もっともこれは「2次キャッシュが512KBもあるから」とも言えるのだが、この結果として3次キャッシュを通常の「Inclusive Cache」(包括的キャッシュ)にすると効果がないので(下手をすると各コアの2次キャッシュのコピーで終わる)、3次キャッシュもまた「Exclusive Cache」(排他的キャッシュ)構成となることが明らかにされた(キャッシュについての関連記事はこちら)。
最後の仮想化での目玉は「Nested Paging」と呼ばれる技法である。仮想化環境の上で複数の仮想OSが動いているというケースでは、ページアクセスに際して2回のアドレス変換が必要になる。
- 仮想OS上の仮想アドレス→実マシン上の仮想アドレス→実マシン上の物理アドレス

「Nested Paging」に関する解説。インテルもNehalemの世代で、「EPT」(Extended Page Table)という名称でこれをサポートした
「実マシン上の仮想アドレス→実マシン上の物理アドレス」の変換は、CPU内部のMMU(メモリー管理ユニット)というハードウェアが処理する。この際に、MMU用のキャッシュとして働くのが「TLB」(Translation Lookaside Buffer)で、うまくTLBがヒットすれば非常に高速に変換される。問題は「仮想OS上の仮想アドレス→実マシン上の仮想アドレス」の変換だ。当初はこれをすべてソフトウェアで実現していたために、大変処理が遅かった。
これを改善するのがNested Pageだ。「仮想OS上の仮想アドレス→実マシン上の仮想アドレス」の変換もMMUでまとめて扱えるようになり、これにあわせてTLBの構造も拡張されている。このNested Pageという技法そのものは、2005年の「Pacifica」(AMD-Vの開発コード名)発表の際にすでに明らかにされていたが、実装はBarcelonaでようやく実現された。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ











の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")





























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






















