



ロードマップでわかる!当世プロセッサー事情 第971回
GTC 2026激震! 突如現れたGroq 3と消えたRubin CPX。NVIDIAの推論戦略を激変させたTSMCの逼迫とメモリー高騰
2026年04月13日 12時00分更新

今年も3月16日からGTCが開催された。基調講演の模様はYouTubeで視聴できるが、今年の主な発表をまとめると、ハードウェアとしてはVera RubinとDGX Stationに加え、まったく予想していなかったGroq 3 LPXが発表された。

NVIDIAの推論アクセラレーターGroq 3 LPX
コンシューマー向けの話で言えばDLSS 5が目玉であるが、こちらはいずれKTU氏が解説するだろうから筆者のほうは置いておいてハードウェア側の話をしよう。今回はGroq 3 LPXを解説する。
突如発表されたNVIDIAとGroqの不可解なライセンス契約
事実上の買収か? 中心人物がこぞってNVIDIAへ移籍
最初にGroqについて。この連載でも582回と583回で補足する形で紹介したGroqのTSP(Tensor Streaming Processor)。今はTSPに代わりLPU(Language Processing Unit)という名称になっているが、名前が変わっただけで中身に違いはない。
そんなLPUだが、2025年12月にNVIDIAがGroqと非独占的なテクノロジーライセンスの契約を結んだというリリースが突如発表された。ちなみにこの件、NVIDIAからはアナウンスが一切ない。先のリリースによれば、以下のようになっている。
- NVIDIAはGroqの推論向けテクノロジーライセンスを入手する
- Groqそのものは引き続き独立企業として運営される
- GroqのCEOには、それまで同社の最高財務責任者(CFO)を務めていたSimon Edwards氏が就く
- Groqの創業者兼CEOだったJonathan Ross氏や社長を務めていたSunny Madra氏らのGroqの主要メンバーはNVIDIAに加わる
ライセンス金額は公式には明らかにされていないが、米CNBCによれば200億ドルもの金額だとしている。200億ドルという金額はテクノロジーライセンスとしては破格すぎる金額だし、Groqのテクノロジーを担っていた中核人材が全部NVIDIAに移籍してしまい、Groqそのものは既存のユーザーへのサポートのために残すと言わんばかりの対応なのは、事実上の買収である。
CUDA Tileの登場が示唆していた
Dataflowアーキテクチャーへの布石
これに先立つ2025年12月4日、NVIDIAは新しいCUDA Tileと呼ばれるAPIを発表した。もともとCUDAはGPUの仕組みをそのままソフトウェアから扱えるようにしたものであり、内部的にはSIMT(Single Instruction Multi Thread)構成になっている。
これはカーネルと呼ばれる1つのプログラムを、複数のスレッドが並行して実行する仕組みである。カーネル、つまりプログラムそのものはすべてのスレッドで共通だが、扱われるデータそのものはスレッドごとに異なっている。GPUは本来「ある瞬間の画面」を描画するためのものだが、描画処理(例えば明るさを半分に落とす)は画面全体に共通だが、扱われるピクセルデータはピクセルごとに異なっている。
理論上は各ピクセルの描画処理をそれぞれ別のスレッドに割り当てて、それぞれでカーネル(今回の例なら明るさを半分に落とす)を並行して実行することで、そのGPUの最大性能で描画する形になる。ただし、実際にはこんなことをしたらオーバーヘッドが大きすぎるので、それこそ4×4ピクセルや8×8ピクセルなどの塊で処理することになる。
GPU的な処理には適しているが、AI処理にはあまり適していない。この連載でも何度か説明してきた話だが、AIを処理するための定番アーキテクチャーといえばDataflowであり、GPUがSparsity(疎行列)などの対応をがんばってやっていることをDataflowは自然かつ低レイテンシーで実行できるし、ネットワークの規模に応じて演算要素の割り振りができるというメリットもある。
連載869回でインテルのDNNプロセッサーを使ってImageNetの処理を比較しているが、GPUは下の画像のスタイルの処理の振り方しかできない。

インテルのDNNプロセッサーでResNet-8を実行した場合の処理の流れとレイテンシーの分布
ところがDataflowでは下の画像の処理ができる。インテルのケースではコアの数が56個と少ないので、Dataflow式にするとレイテンシー(最初にデータを入れてから結果が出てくるまでの時間)こそやや長くなっているが、スループットや効率ではDataflowの方が優れているという結果になっている。
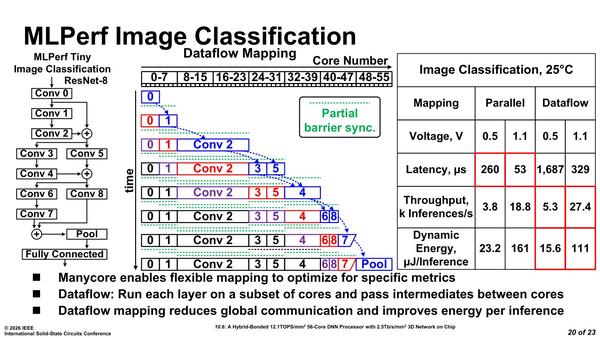
データフローでの処理の仕方
さてCUDA Tileである。CUDA TileはCUDAのSIMTモデルを完全に捨て、Dataflowのように処理を記述できるようになっている。もっとも現在のNVIDIAのハードウェアはDataflowのような処理が物理的に不可能なので、内部でこれをSIMTスタイルに変換して実行している。
その意味ではオーバーヘッドが大きいだけでしかないのだが、あえてこうした新しいプログラミングモデルを持ち込んできたというのは、長期的にDataflowのような(現在のGPUより)もっと効率のいいアーキテクチャーを導入するつもりがあると考えられ、そして今回のGroqの買収はそうした新しいアーキテクチャーを設計するための人員を確保した、と考えられるわけだ。
実際Jonathan Ross氏はGroqの前はGoogleでTPUの開発をしていた方であり、そう考えれば理解できる動きである。とまぁ1月の時点では筆者はそう考えていたわけだ。これがひっくり返って、もっと積極的にNVIDIAはGroqを取り込むという方向性が明らかになったのが今回のGTCでの発表である。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")
















