



ロードマップでわかる!当世プロセッサー事情 第971回
GTC 2026激震! 突如現れたGroq 3と消えたRubin CPX。NVIDIAの推論戦略を激変させたTSMCの逼迫とメモリー高騰
2026年04月13日 12時00分更新

GPUはもう計算だけではない
NVIDIAがLPUの力を借りて挑む、LLM推論の限界突破
先にNVIDIAの発表を説明しておきたい。LLMの推論に関し、NVIDIAは2025年からDynamoと呼ばれるフレームワークをオープンソースで公開している。もともとLLMの推論ではPrefillと呼ばれる、入力されたプロンプト全体を処理し、最初のトークンとKV-Cacheを生成するフェーズと、Decodeと呼ばれる、直前のトークンを基にKV-Cacheを再利用して次のトークンを1つずつ生成するフェーズの2段階の処理に分割される。
下の画像はこれを模式図的に示したものであるが、当初はこのPrefillとDecodeを1つのシステム内で実行していた。
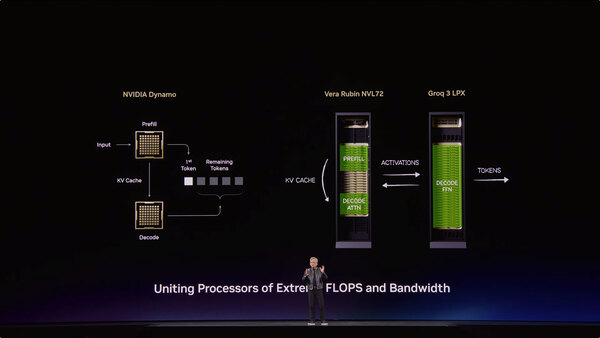
もうここでVera RubinとGroq 3の位置付けが示されてしまっているが、これは後述する
KV-Cacheは、KeyとValueの組み合わせである。LLMで採用されているTransformerというモデルでは、Query(Q)とKey、Valueという3つの行列を利用して入力された単語内の関連性を計算する仕組みになっている。Queryに対してどのValueを返すのが適切かを計算するのがAttentionと呼ばれるものである。
| KV-Cacheの役割 | ||||||
|---|---|---|---|---|---|---|
| Query | 現在の単語が「何を探しているか」を示す | |||||
| Key | 検索対象のラベルで、単語が「どんな情報を持っているか」を保持する | |||||
| Value | 実際の情報の値。要するに情報の「具体的な内容」を保持する | |||||
LLMでは入力された単語を随時処理していく。だから最初のトークンはPrefillで生成される形だが、2つめの単語が入力されるともう一度トークンのAttentionの計算がされ直される。以後、単語が入るごとにAttentionの計算がやり直されるため、計算量が爆発的に増える。
これを少しでも軽減するために、Prefillの段階でKeyとValueをセットにしたKV-Cacheを構築しておき、Attentionの再計算はこのKV-Cacheを利用することで計算負荷を減らそうというものだ。このAttentionの再計算を行うのがDecodeである。
DecodeにはこのAttentionに加えてもう1つ、FFN(Feed Forward Network)という処理が入る。Attentionはトークン同士の関係性、いわば文脈情報が出力される形だが、FFNはこれを最終的に出力される文章に変換する役割を果たすと言えるだろう。この変換に際しては、猛烈にメモリー帯域が必要になる。これは猛烈な量でKV-Cacheを参照するためだ。この結果、Prefillでは計算能力が重要になる一方、Decodeではメモリー帯域が重要になる。
そこでNVIDIAはRubinにGroqのLPUを組み合わせることを決めた。実際Rubin単体でのLLMのスループットは、Blackwell比で2~10倍程度だが、ここにGroq 3 LPXを組み合わせることで、ユーザーあたり400 トークン/秒における性能をNVL72の35倍近くまで引き上げられる、としている。
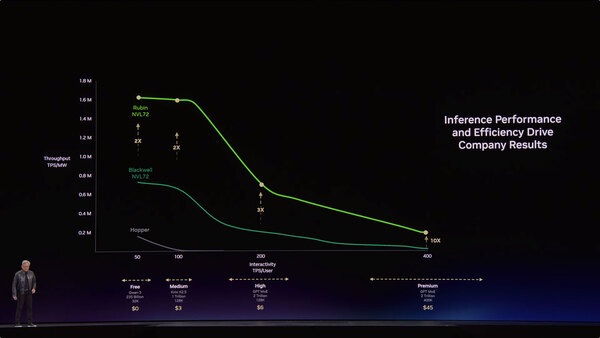
RubinのLLMスループットは、Blackwell比で2~10倍。ユーザーあたりのトークン量が増えるほど加速度的に性能が劣化するのは仕方がないところ
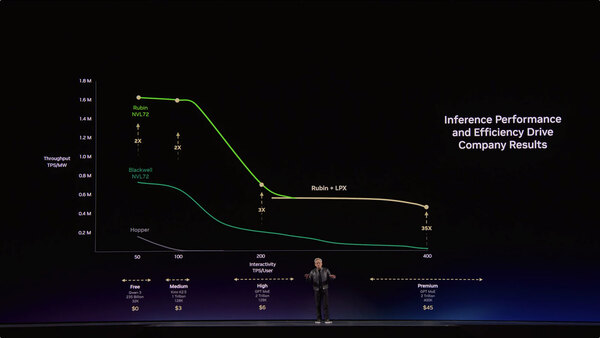
Groq 3 LPXを組み合わせと、NVL72の35倍近くまで引き上げられる。要は、最も高額なプランを選択したユーザー向けの処理性能が大きく向上するわけだ
さらに言えば、これまで処理性能が恐ろしく落ちていた1000トークン/秒の領域でも結構なスループットを維持できるとしている。これはAI推論のサービスを提供しているベンダーにとって、売り上げを10倍に伸ばせるチャンスだ、としている。
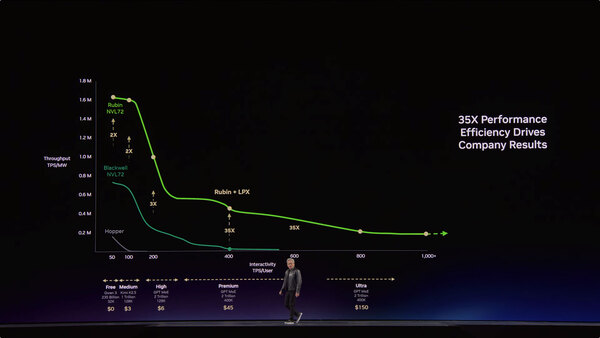
200トークン/秒あたりまでの性能はGroq 3 LPXを併用しても高速化しない。ピーク性能は上がらないが実効性能が上がる、という効果が期待できるわけだ
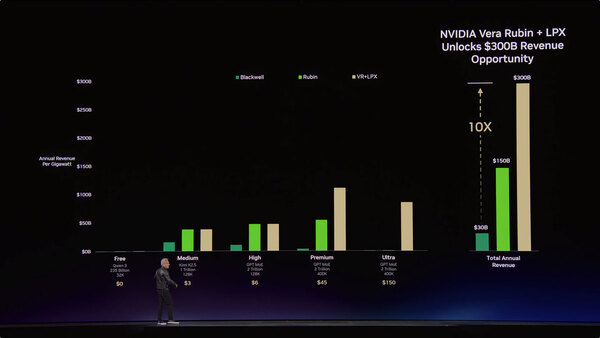
実効性能の向上により、Premium/Ultraといった、お金をたくさん払ってくれるユーザーからの売上が大きく伸びるという皮算用である。実際にはPremium/Ultraの価格が下落しそうな気もするのだが……
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")
















