



ロードマップでわかる!当世プロセッサー事情 第869回
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度
2026年03月30日 12時00分更新

Meta、Alibaba、AMDとの比較で見えたIntelの独自性
Foveros Direct 3Dが可能にする演算とメモリーの極限接近とその価値
下の画像が過去のHybrid Bondingを実装した論文との比較である。
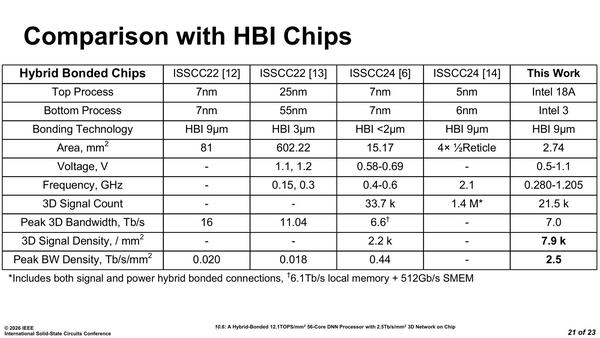
Hybrid Bondingを実装した論文との比較。あとは最先端プロセスを利用しての3D実装が可能になった、という点もアピールポイントかもしれない
ここでISSCC22の[12]というのはAMDの3D V-Cacheのインプリメント、ISSCC[23]はAlibabaの3D LogicとDRAMを積層したという論文、ISSCC[24]はMetaによるAR向けのアプリケーションプロセッサーの3D積層の論文、ISSCC[14]はAMDのInstinct MI300シリーズの実装に関する論文をそれぞれ指しており、なんというか単純な比較は難しいのだが、3D方向の配線密度はここに挙げられた現時点の実装に比べるとずっと高いことをアピールしている。同様にDNN PEの性能を比較したのが下の画像である。
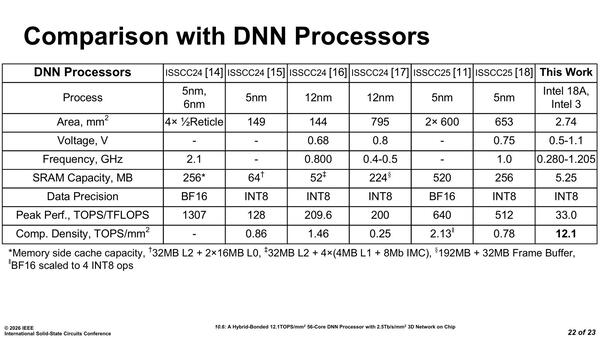
DNN PEの性能比較。ただこれ、SRAMがコアあたり96KBと小さいからこその数字であり、もっと広範なアプリケーション向けにSRAM容量を増やしたりすると下がりそうな気がする
ISSCC24[14]は上述のAMD Instinct MI300、ISSCC24[15]は韓国Rebellionsの5nmプロセスで製造されたML SoCの論文、ISSCC24[16]は蘭Axelera AIによる12nmで15TOPS/W、209.6TOPSの性能を出すEdge向けAI SoCの論文、ISSCC24[17]はIBMのNorthPoleという12nmプロセスのAIチップの論文、ISSCC25[11]はSambaNovaのSN40Lの実装、そしてISSCC25[18]は韓国FuriosaAIによるRNGDという5nmのLLM向けプロセッサーの論文である。
なんというかハイエンドからローエンドまでよりどりみどりという感じで一律に比較するのは難しいが、一応インテル的にはCompute Unitの演算密度(単位面積あたりの演算性能)では他を圧倒する、と主張している。
今回は純粋に研究目的での発表であって、これを商用化向けに考えるといろいろと困難が待ち受けているので設計の見直しは必要だろうが、3D実装にしたPIMに可能性があると示した(副次的に、Foveros Direct 3Dの性能の高さを立証した)ことでは、意味のある発表だと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























