



ロードマップでわかる!当世プロセッサー事情 第869回
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度
2026年03月30日 12時00分更新

エネルギー消費を据え置き、スループットを劇的改善
インテルが証明した3D接続のデメリットなき進化
さてこの論文は、3D接続にしたことによるPIMの効率改善である。その効果が明確なのが下の画像で、要はRISC-VコアとDNN PEを2次元平面で接続した場合と3次元接続した場合でのスループットの違いである。
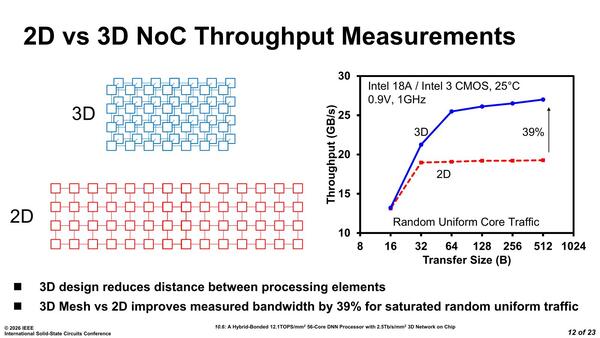
もっともこれは2Dメッシュ vs 3Dメッシュという話で、物理的に3D接続でなくても配線層で疑似的に3D接続すれば同じ効果が得られるとは思うのだが、ダイの外に配線を引き出すならまだしもダイ内でそんなことできるか? というと不可能ではないがとても大変だろう
転送サイズが小さい16Bytesではどちらも大して性能が変わらないが、2D接続は32Bytesの18GB/秒あたりでメッシュがボトルネックになってそれ以上上がらないのに対し、3Dでは512Bytesくらいまで継続的にスループットが向上するとする。
一方でエネルギー消費そのものは2Dだろうと3Dだろうとほぼ変わらないとしており、少なくとも3D接続によるデメリットがないことは確認できたとされる。
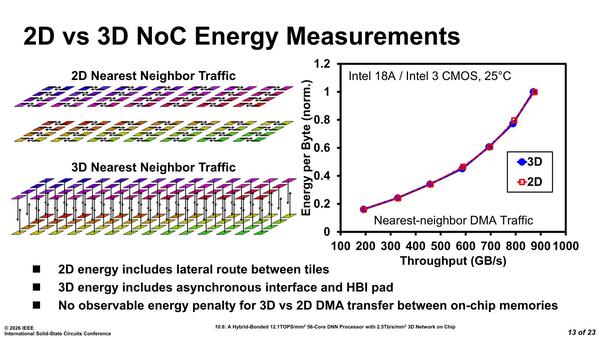
前ページ最初の画像で示したように、PHYにあたるものはなく、単にディファレンシャル化するバッファがあるだけなので、不要な電力消費が抑えられた(あとHybrid BondingなのでBumpを経由することでの損失抵抗もない)のがこの結果になったと考えられる
それとこのシステムの性能であるが、ピーク性能では1.2GHz駆動で33TOPSを記録するが、電圧も1.1Vと高めである。逆に電圧を下げると効率は16.1 TOPS/Wまで向上することが確認されたとする。
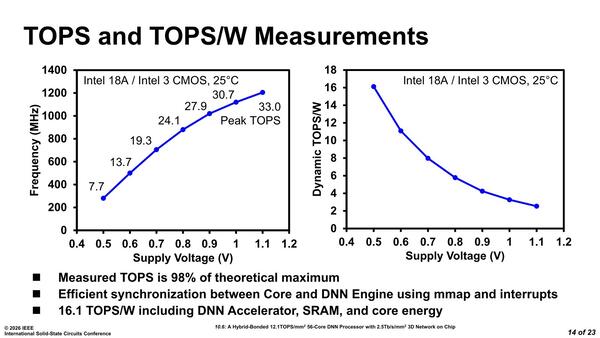
0.5VでもSRAMとDNN PE/RISC-V、ネットワークまで全部ちゃんと動作するとのこと。動作周波数は280MHzほどまで下がる
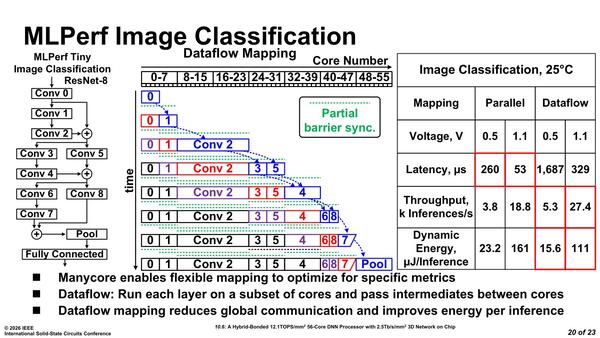
実際にこのチップでResNet-8を実行した場合の処理の流れ、それとレイテンシーの分布が下の画像となる。

あるいはコア数を64まで増やせば、Conv 2/4の時間はもう少し縮められたかもしれないが、加算がバカにならないので効果は限定的だろう
意外に処理時間が長いのがConvolution 2、次がConvolution 4での処理+加算となるが、ほかはわりとそれほど大きな時間を要しておらず、並列化がうまく機能していることが見て取れる。ただこれはパラレル(各処理を全コアを使って並列に行なう)マッピングの場合で、データフロー的に処理するとどうか? というのが下の画像だ。
レイテンシー重視ならパラレルマッピングの方が性能が高いが、スループットあるいは効率重視ではデータフローの方が効果的とされる
この図を見ると、そもそも56コアというやや中途半端なコア数は、ResNet-8でデータフロー的な処理をするのに最低56コア必要という判断で決まったのかもしれない。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























