



ロードマップでわかる!当世プロセッサー事情 第869回
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度
2026年03月30日 12時00分更新

研究用と割り切ったINT8固定設計
3D積層チップが示す、将来の商用プロセッサーへの布石
下の画像は、Foveros Direct 3Dを利用した接続部の構図である。24×23のパッドが9μm間隔で配され、中央にデータ(Up/Down)が置かれる格好である。後で出てくるが、1つのコアのサイズもおそらく216×207μm程度なので、ほぼコアの全面にこのPadが置かれる格好になる。
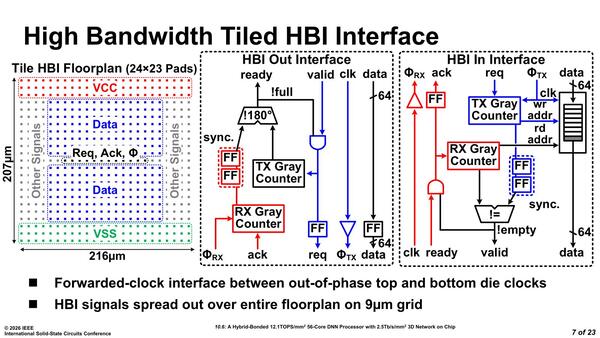
Foveros Direct 3Dを利用した接続部の構図。上の画像の脚注などで「256bitはどこに消えた」と思われるかもしれないが、上り下りともに64bit幅のディファレンシャルなので信号ピンは上り下りともに128ピン、トータルで256ピンと考えられる
信号がSingle Endedではなくディファレンシャルなのはやや意外だった。この変換をするのが、HBI Out Interface右下のFF:FlipFlopと、HBI In Interface右上のBufferと思われる。
次にDNN PEの中身が下の画像である。まず16行16列の行列演算器(Systolic Array)があり、ここでの合計を合算して(Bias Addition)、正規化し(Batch Norm)、最後にアクティベーションするという、もう本当にCNNの演算だけを行なう仕組みになっている。
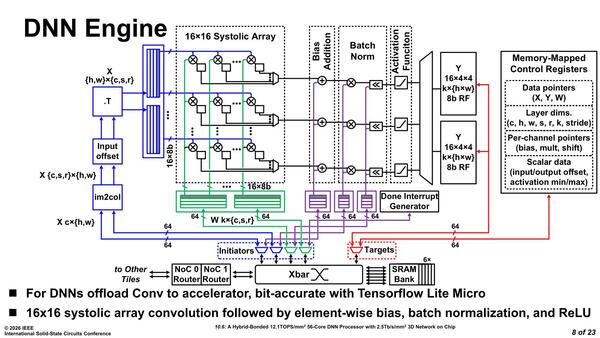
この書き方からするとTensorflow Lite Microを動かすのが前提の構成になっている(もちろんほかのフレームワークも利用可能だろう)
精度はINT8固定だが、研究用だからこれで良しとしたのだろう。そのDNN PEであるが、これは本当にアクセラレーターで他の処理ができないので、制御はRISC-Vコアが担う形になる。下の画像はその動作をまとめたものだが、入力されるマップが1つを同時に複数のコアで分割するのか、複数のマップをそれぞれ独立して処理するのかで動作が変わってくる。
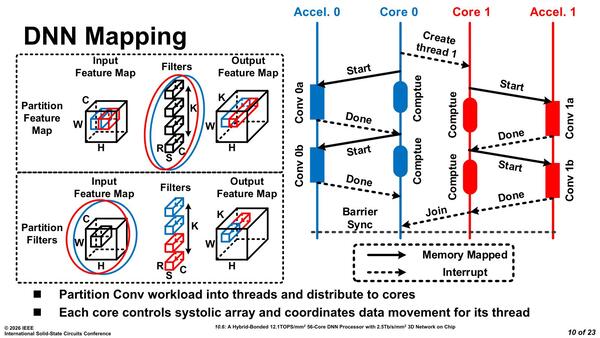
右側の動作フローは、左側で言えば上側のPartition Feature Mapの場合の処理となる。この場合Core 0がプライマリーとなり、それがCore 1、Core 2、...にCreate Threadを発行してそれぞれ処理を行なわせ、最後にJoinで同期を取る格好だ
ただ個々のコアは自身のDNN PEで処理することそのものは変わらず、コア同士の制御はRISC-V側で管理するというシンプルな仕組みになっている。これを見ていると、RISC-Vコアはもう少し強力なものにして、1つのRISC-Vコアで複数のDNN PEを駆動するようにした方がオーバーヘッドが少なそうな気もするのだが、あくまで研究用のコアだからこれで良しとしたのであって、商品化するとなるとまた実装は変わってくるのだろう。
実際のテストシステムが下の画像だ。ダイサイズは3.3×0.83mmと、かなり横長の構成である。チップのサイズに比してヒートシンクがやけに大きい気がするが、テスト用だからだろう。

このページ最初の画像で説明したダイ(この写真で言えばTile)の大きさはこの寸法からの逆算である。Chip Bridge/Chip IOの面積がよくわからないから断言はできないが、少なくとも横幅が216μm未満ということはないだろう。つまりChip BridgeとChip IOの面積は276×829μm程度になると考えられる
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























