



ロードマップでわかる!当世プロセッサー事情 第865回
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略
2026年03月02日 12時00分更新

鍵を握るのは「配線層(BEOL)」の電力制御
肥大化する消費電力への回答
省電力についてもいろいろ工夫されているとする。そもそもTSMC N5→N3Eで、同一消費電力で5%程度の動作周波数向上が可能であり、加えてクリティカルパス(そこの速度で回路全体の速度が決まる、一番タイミングが厳しいところ)のみ高速型トランジスタを使い、それ以外は極力省電力型を使う工夫をしたとしている。
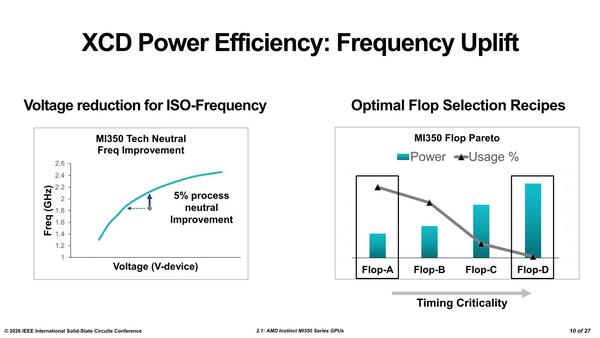
省電力に関する工夫。もっともクリティカルパス以外は省電力型のトランジスタを使う、という技法自体はもう当たり前になっているのが昨今の動向ではあるので、今さら書く必要もないのでは? という気もしなくはない
全体としての省電力の目標は、Cac/Op(Capacitance per Operation:1回の動作でスイッチされる実効容量のこと)を30%以上削減することだった。Cac/Opというのは、1回の動作でスイッチングされる際の実効容量で、スイッチングに要するエネルギー量はこのCac/Opに比例して大きくなるため、これを減らすのは消費電力削減には重要である。
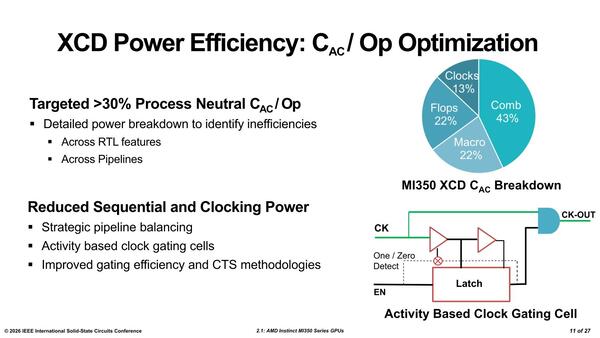
Activity Based Clock Gatingというのは、実際に動作している状況に応じて細かく不要部分へのクロック供給を停止して回路を休止状態に置くことである。CTSというのはClock Tree Synthesis(クロックツリー合成)で、クロック信号をチップ全体に分配するツリー構造の構築方法である
しかもProcess Neutral、つまりプロセス微細化で削減される分とは別にこれを実現するというもので、そのための技法として回路設計レベルでの工夫のほか、クロック・ゲーティングをかなり積極的に行なうことで目標を達成しようと苦労したようだ。
もう一つ示されたのがBEOL(Back End of Line:後工程)での最適化である。BEOLは、要するに配線層である。LSIは、まずトランジスタ層を先に製造し、その後で配線層の構築を行なう。そこでトランジスタ層(と場合によってはその真上のM0~M3の配線層あたりの配線層まで)をFEOL(Front End of Line)、配線層をBEOLと称するわけだが、最近のデザインのトレンドで言うとFEOLにおける消費電力は(主にトランジスタの改良や、M0~M3の改良などによって)微減の方向にある。
ところがBEOL、つまり配線層が層数の増加などにより消費電力がだんだん増加しつつあり、これがFEOLの減少分を埋めて余るほど大きくなっているので、トータルで消費電力がやや増えるという傾向にあるとしている。このBEOLにおける消費電力の削減もいろいろ工夫したという。

具体的には、配線の配置を「注意」深く行なった(The design also emphasized careful floorplanning)ほか、機械学習ベースの配線ツールを利用してCacの削減に努めたとしている
ではトランジスタ数を増やしてなにを強化したのか? まずLDS(Local Data Share)の容量を従来の64KBから160KBに強化している。またMI300X(CDNA3)ではLDSに対して128バイト/サイクルでリードアクセス可能だが、MI350X(CDNA4)ではこれが256バイト/サイクルと2倍になっている。

LDSはスクラッチパッドのように利用できる領域で、複数のスレッド間でのデータ共有に利用可能である
おもしろいのは構成も少し変わっていることで、CDNA3ではCUあたり64KBを32バンクで構成しており、つまり1バンクあたり2KBなのに対し、CDNA4では160KBを64バンクに分割しており、バンクあたり2.5KBに増量されていることだ。
この変更の理由は明確にされていないが、おそらくはアプリケーションでの利用のされ方からのフィードバックであろう。単純にHBMの容量と帯域が増えているのもやはり性能面には寄与するが、ただこれはプロセス微細化とは関係ない話である。
さてトランジスタを30%増加して、なにを実現したのか? というのが下の画像だ。つまりMatrix Coreそのものの性能を強化したわけだ。
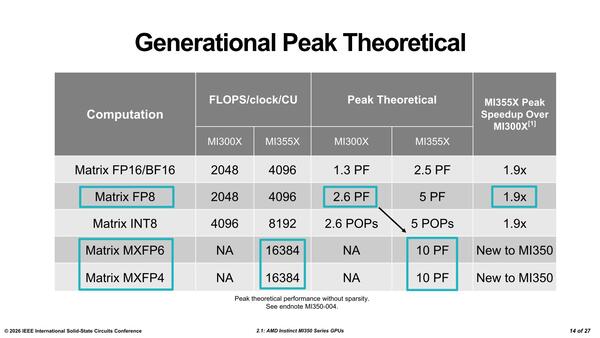
Matrix Coreはスループットを倍にし、さらにMXFP6/MXFP4のサポートでピーク性能を従来比の4倍近くにしたという計算になる
ちなみにCUとMatrix Coreの比は1:4でこれはCDNAから変わっていない。したがってMatrix Coreそのものに手を入れたものと考えられる。
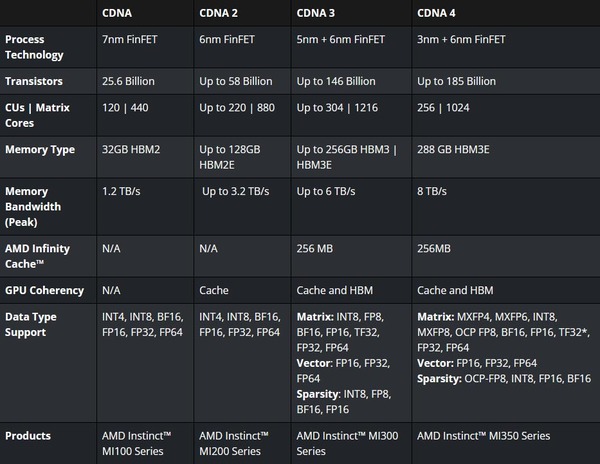
CUとMatrix Coreの比は1:4でこれはCDNAから変わっていない。それはいいが、CDNAのMatrix Coreの数は480のはずである
画像の出典は、AMDの"AMD CDNA Architecture"より
CUそのものについてはMI300シリーズと変わらない、という話は連載829回で説明しているとおりである。要するにLDSとMatrix Coreの強化のために30%ほどトランジスタ数が増え、これをプロセス微細化や回路設計の工夫でなんとか同じダイサイズに押し込めたのがMI350シリーズというわけだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第870回
PC
スマホCPUの王者が挑む「脱・裏方」宣言。Arm初の自社販売チップAGI CPUは世界をどう変えるか? -
第869回
PC
半導体プロセスの新たな覇権! インテルのDNNプロセッサーはAMDやMetaを凌駕する配線密度と演算密度 -
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")

















