




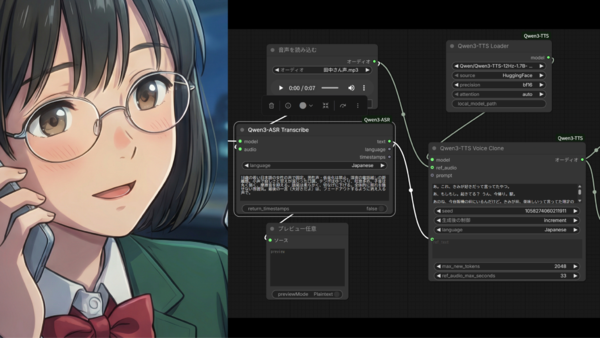
Qwen3-TTSで音声を生成しているComfyUIの画面と、ゲストキャラクターの田中さん(筆者作成)
高性能化する音声系のオープンモデルが話題になっています。1月22日に、アリババが「Qwen3-TTS Family」をオープンモデルとして公開しました。TTSは「Text-to-Speech」の略で、テキストを音声に変換するためのモデルです。わずか4秒ほどの音声ファイルを参考音声として読み込めば、かなりの精度で音声を再現できるという恐ろしく高性能なものです。筆者の声、動画AIから抽出した声などを使って、再現精度を検証しました。
Qwen3-TTSの強力さをわかりやすく理解できる例として、まず、筆者の音声で作例を作ってみました。2022年、YouTube Liveでの筆者の講演から、7秒分の音声を抽出しました。オンラインであることもあって若干音がこもっていますがよしとします。音声をQwen3-TTSに読み込ませ、過去の連載の冒頭を読み上げさせました。生成された音声は25秒となりました。たった7秒の声から生み出したにも関わらず、筆者の声真似を見事に実現しています。
▲筆者の声を使った作例。動画冒頭の7秒は筆者の元々の講演時の声、後半25秒がAI生成の声。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第150回
AI
無料でここまで? 動画生成AI「LTX-2.3」はWan2.2の牙城を崩すか -
第149回
AI
AIと8回話しただけで“性格が変わる” 研究が警告する「おべっかAI」の影響 -
第148回
AI
AIが15万字の小説を1週間で執筆──「Claude Opus 4.6」が示した創作の未来 -
第147回
AI
ゲーム開発開始から3年、AIは“必須”になった──Steam新作「Exelio」の舞台裏 -
第146回
AI
ローカル音楽生成AIの新定番? ACE-Step 1.5はSuno連携で化ける -
第145回
AI
ComfyUI、画像生成AI「Anima」共同開発 アニメ系モデルで“SDXL超え”狙う -
第143回
AI
AIエージェントが書いた“異世界転生”、人間が書いた小説と見分けるのが難しいレベルに -
第142回
AI
数枚の画像とAI動画で“VTuber”ができる!? 「MotionPNG Tuber」という新発想 -
第141回
AI
AIエージェントにお金を払えば、誰でもゲームを作れてしまうという衝撃の事実 開発者の仕事はどうなる? -
第140回
AI
3Dモデル生成AIのレベルが上がった 画像→3Dキャラ→動画化が現実的に - この連載の一覧へ








































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")











