



ロードマップでわかる!当世プロセッサー事情 第852回
Google最新TPU「Ironwood」は前世代比4.7倍の性能向上かつ160Wの低消費電力で圧倒的省エネを実現
2025年12月01日 12時00分更新

Tensor Coreの構造は、TPU v3に類似しているが
XLUとSparseCoreが追加されている
Ironwoodの内部構造が下の画像だ。個々のTensor Coreの構造は、TPU v3のものに似ているが、TPU v3に見当たらないのがXLUである。これはCross Lane Unitの略で、TPU v4世代で追加されたものだが、単純に言えばVmem(Vector Memory)の転置やシャッフルといった並び替えをするためのエンジンである。
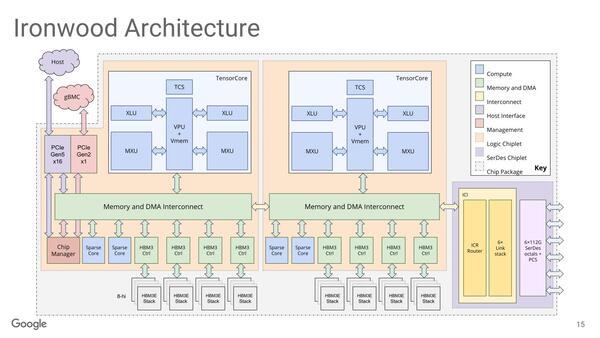
SerDesタイルは、1ページ目最後の画像でいうところのキューブ内部の接続に利用する。上下左右前後にそれぞれ2本ずつのリンクが必要なので、合計6本というわけだ
同様にTPU v3までになかったものにSparseCoreが挙げられる。こちらの構造が下の画像で、おのおの16個のタイルからなり、事前学習あるいは強化学習の微調整の際の演算オフロード、大規模レコメンデーションモデル向けの埋め込み処理などを担当する。
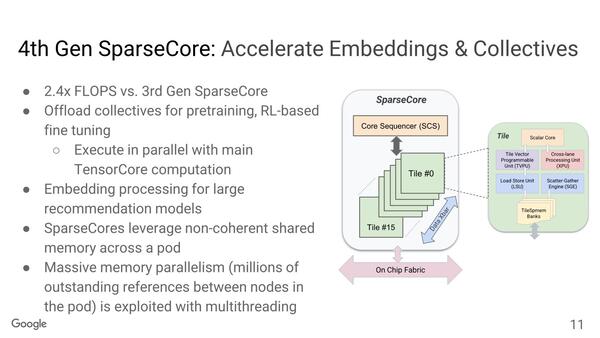
SparseCore1個あたり16タイルからなり、おのおのが独立して動作する。Tensor Coreとも独立して動作する仕組みである
実際にはこのIronwoodが4枚乗ったボードが利用されており、つまり16枚のIronwood Trayで1つのキューブを実装する形になる。Ironwoodだけなら結構実装密度を高められそうだが、実際にはCPU ホストのシャーシと対になる形で収められている。

Ironwoodトレイそのものは1Uで収まる規模に見える。OSFPはキューブを構成する16枚のIronwoodトレイの相互接続用であろう。残り2つの用途はよくわからない
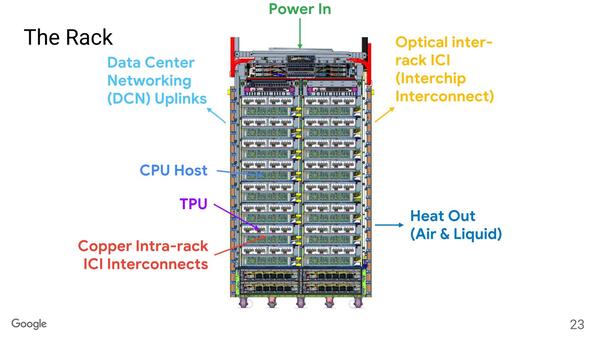
消費電力が低めなので、電源供給用のサイドカーは不要のようだ。先程の試算でも20KWくらい。多めに見積もっても30KW程度で、普通のデータセンターに楽に設置できる計算になる
ラック1本にはIronwood Trayが16枚、Ironwoodが64チップとなり、つまりラック1本で1つのキューブを構成する形だ。したがって、9216チップのSuperPodを構成するためには、ラックが144本必要になる計算だ。実際データセンターの写真を見ると、なかなか壮観である。

おもしろいのが電力に関する話である。複数の処理が走っている際には常時稼働状態が続くとはいっても、ミクロで見ると細かく休止状態が入ることは珍しくない。その場合、Photo02でいうところのJobに属するすべてのキューブが一斉に稼働したり休止したりするので、1個1個で言えば160W程度であってもラック単位では20KW、Job単位ではMW規模で消費電力が変動する。
これをもう少し平滑化するための試みとしてGoogle Project Smoothieというプロジェクトが進行中であり、Ironwoodもこれに対応したハードウェアおよびソフトウェアが実装されているとされる。
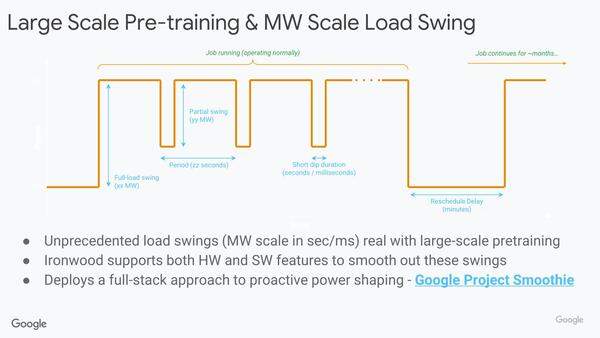
ミリ秒から分の規模まで休止状態はさまざまだが、1つのJobそのものは数ヶ月単位のものもある、というのがすごい
具体的には、TPUコンパイラの中に計測用のStubを埋め込んでおき、適当なタイミングで電力変動に関するワークロードの主要な指針(具体的になにかは未公開)を測定する。その結果を基に、演算ブロックの稼働状況を動的に調整して、時間経過にともなう利用率を平滑化するとしている。
素人考えには、処理の区切りがつきそう、例えば畳み込みが終わって全結合に入ることを検出して、その少し手前から動作周波数を落とすといったことが思いつくが、本当にそういう実装なのかどうかは不明である。
ちなみにIronwoodは学習から推論まで幅広く利用できるとしているが、推論はともかく学習でFP8のまま行けるのかは不明だ。ただBF16のサポートに関しては今のところ明示されていない(可能/不可能のレベルで不明)。
Ironwoodのチップの原価そのものはBlackwellとそう変わらない(Blackwellも2ダイ+8×HBM3e構成である。SerDesチップレットがある分若干割高な程度)が、性能消費電力比を大幅に引き上げることに成功した。
SuperPodそのものは9216チップが上限だが、複数のSuperPodをスケールアウト的に接続することは可能であり、10月にはAnthropicが100万個規模のIronwoodを使う計画があることが明らかにされている。
したがって、Blackwell同様にこちらもスケールメリットによる価格低減の効用はしっかり受けていると考えられ、販売価格そのものもBlackwellより安くても不思議ではない。
おまけに昨今のデータセンターでは供給電力量が問題になりつつあるご時世だけに、チップ単価よりもこの性能消費電力比(≒ランニングコスト比)がBlackwellより大幅に良い、というあたりがIronwoodの最大のメリットである。Metaが導入を決めたのもこのあたりが理由なのかもしれない。
この連載の記事
-
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 - この連載の一覧へ














で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")









































