



ロードマップでわかる!当世プロセッサー事情 第851回
Instinct MI400/MI500登場でAI/HPC向けGPUはどう変わる? CoWoS-L採用の詳細も判明 AMD GPUロードマップ
2025年11月24日 12時00分更新

MI450はHeliosというラックで提供する
実は、Instinct MI450の世代ではHeliosというラックが提供されることがすでに公開されている。このHeliosの中身が下の画像で示されている。

Helios。幅広に見えるが、実際には高さが通常のラックより低めなのかもしれない
このHeliosの中身が下の画像で示されている。Rubin Ultra世代のKyber Bladeのミッドプレーン同様に、配線はMI450やスイッチの裏側にある、縦方向のシャーシ内のバックプレーン基板で接続されるように見える。Kyber Bradeのミッドプレーンは72層基板を使っていると評判だが、Heliosのバックプレーンもこれに匹敵する層数になりそうだ。

Heliosの中身。72枚のGPUがおのおの3.6TB/秒で接続されているとすれば、合計帯域は3.6×72=259.2TBでほぼ260TB/秒になる計算だ
これを見ると、下の画像のようになるはずだ。要するにMI450同士を直接相互接続しているとスケーラビリティに欠けるので、NVLinkと同様にこちらもインフィニティ・ファブリック・スイッチを間に挟んだのだろう。

この場合の接続図は下図のようになるであろう。1枚のMI450から9本のインフィニティ・ファブリック・リンクが出て、それが9枚のスイッチにそれぞれ接続される格好だ。この構造は、隣接するMI450同士であってもスイッチを挟むことで2-hopとなり、ややレイテンシーの面では不利ではあるが、その代わり72枚まで規模を2-hopのままで拡張できる。
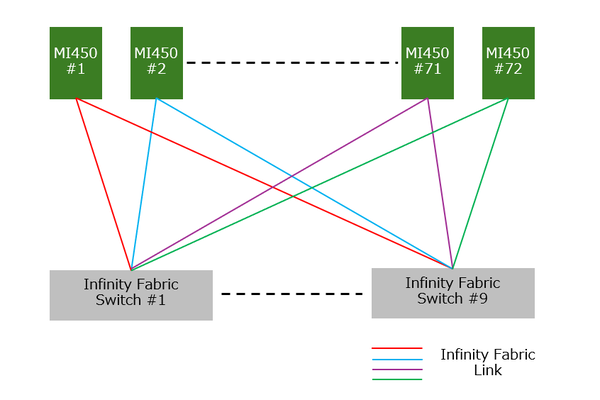
トータルの性能という意味では1-hopで相互接続するよりも有利である。同じ理由でNVIDIAもV100に搭載されたNVLink 2からNVSwitchと呼ばれるスイッチを間に挟み込む方式に切り替えている。NVIDIAの場合、Blackwell世代ではカードから100GB/秒のNVLinkが18本出て、それが18台のスイッチにそれぞれ接続される形態だが、AMDは転送速度を高めに取る方向に舵を切った。ちなみにNVIDIAもRubin/Rubin UltraのNVLink 6/7では3600GB/秒と、MI450と同じ帯域になっている。
一方Scale out Bandwidthであるが、あるいはUALinkをそのまま出せるような工夫がなされている可能性がある。UALinkの最初のバージョンは正式名称がUALink 200G 1.0となっており、仕様にも明確に「物理層は200GBASE-KR1/CR1、400GBASE-KR2/CR2、ないし800GBASE-KR4/CR4に準拠する」と記述されている。
これらの規格はIEEE P802.3djを基にしており、1レーンあたり200Gbpsの銅配線ベースの信号である。なお、IEEE P802.3djは現在Draft 2.2をベースにまだ標準化作業が行なわれている最中で、標準化が完了するのは2026年9月頃の予定だ。
要するに1レーンあたり25GB/秒になり、これを12本束ねると300GB/秒になる。こちらは物理層がイーサネットベースなので、200Gbps/レーンをサポートするイーサネット用のスイッチをベースとしたUALink用のスイッチに接続される格好だ。
実際には12本束ねるというよりも、2本束ねて1レーン(50GB/秒)とし、それを6レーン出すようにするはずだ。こちらはHeliosに隣接するラックにUALinkスイッチを設けて、そこで複数のHeliosラック同士をつなぐ形になるのだと思われる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ































で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")






























