



ロードマップでわかる!当世プロセッサー事情 第849回
d-MatrixのAIプロセッサーCorsairはNVIDIA GB200に匹敵する性能を600Wの消費電力で実現
2025年11月10日 12時00分更新

CorsairはNVIDIAのGB200に匹敵する性能
そんなCorsairであるが、600Wの消費電力に対して38TOPS/Wの効率であり、性能はFP4の場合で2400~9600TOPS、別の言い方をすれば2.4~9.6PFLOPSという性能だと同社は主張する。

38TOPS/Wに600Wをかけると22800TOPS/Wとなる計算だが、この38TOPS/Wはあくまでも条件が一番良い時の数字であって、フル駆動ではもっと効率は落ちる。詳細は後述する
余談ながらBlackwellの性能はFP4の場合、GB200が10PFLOPS、GB300で15PFLOPSとされており、つまりGB200に匹敵できる性能を持つことになる。もっともスケールアウトの性能で言えばNVLinkを持つGB200の方が圧倒的に優位ではあるのだが、Corsairは推論向けのプロセッサーであり、またモデルを小規模なものに抑えつつ精度を引き上げるという工夫をしているので、複数枚のGPUを使わずに済む。つまり1枚で完結させる性能が重要、ということもできるのかもしれない。
チップレットの中身をもう少し見てみよう。下の画像がその構造であるが、それぞれのスライスはGM(Global Memory)とDRE(Data Reshape Engine)、それと2つのStash Engineから構成される。
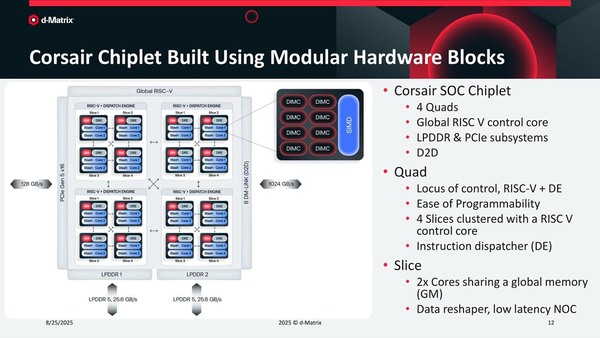
スライスにあるGlobal Bufferは、2つのStash Engineに対してデータを配分するために設けられているものと思われる
そのStash Engine(これはApollo Coreという名前だそうだ)の中身は、8つのDIMCコアと1つのVector SIMDから構成されている。そのDIMCとVector SIMDの詳細は次の画像で示される通りだ。
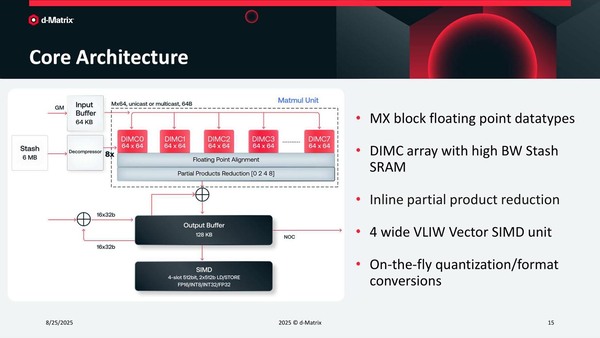
GMから渡されるのは重みデータで、これはすべてのDIMCにマルチキャストされる。一方で演算対象となるデータはStashから渡される形になる
DIMCの手前には64KBのInput Bufferが置かれ、そこから8つのDIMCにデータが配分される。DIMCはすべて64×64のMatMulの演算を実行でき、その結果をOutput Buffer(128KB)に書き込む。その結果に対して、必要ならVector SIMD演算が行えるという仕組みだ。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第868回
PC
物理IPには真似できない4%の差はどこから生まれるか? RTL実装が解き放つDimensity 9500の真価 -
第867回
PC
計算が速いだけじゃない! 自分で電圧を操って実力を出し切る賢すぎるAIチップ「Spyre」がAI処理を25%も速くする -
第866回
PC
NVIDIAを射程に捉えた韓国の雄rebellionsの怪物AIチップ「REBEL-Quad」 -
第865回
PC
1400WのモンスターGPU「Instinct MI350」の正体、AMDが選んだ効率を捨ててでも1.9倍の性能向上を獲る戦略 -
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 - この連載の一覧へ




















で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")


































