



ロードマップでわかる!当世プロセッサー事情 第849回
d-MatrixのAIプロセッサーCorsairはNVIDIA GB200に匹敵する性能を600Wの消費電力で実現
2025年11月10日 12時00分更新

Hot Chips 2025で発表があったプロセッサーで今回取り上げるのはd-Matrix社のCorsairである。これはCIM(Compute In-Memory)方式(同社はDIMC:Digital In-Memory Computingと称している)を利用したAI推論向けである。
CIMについては、連載606回のSamsung PIMや連載591回のMythic AMPなどいくつか紹介してきているが、基本は、DRAMやフラッシュなどのメモリー素子に、SRAMよりも高い記憶密度で演算機構を組み込むというものである。これに対してCorsairはDIMCという名前からわかるように、SRAMベースのCIMになっているのが特徴的である。
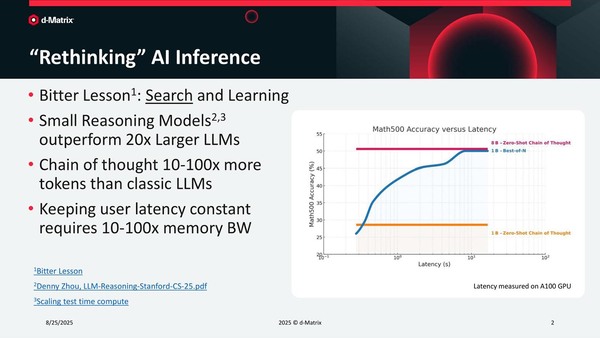
右グラフはA100を使った場合のテストで、COT(Chain-of-Thought:思考の連鎖)を長くとるとデータ形式が1Bでも8Bとほぼ変わらない精度になるが、猛烈にレイテンシーが増える。それだけ連鎖を長くつないでいるため、連鎖を短くすると精度がガタ落ちになるので、どうやって1Bのまま精度を高めつつレイテンシーを減らすかがカギ、という話だ
SRAMと演算器を密結合させた
AI推論向けプロセッサーのCorsair
まず同社の基本的な考え方は、小規模なモデルでもそれなりにレイテンシーをかければ精度は十分に上がるし、性能も大規模モデルの20倍以上に達するが、より長大なChain-of-Thought(思考連鎖)が必要になるというもの。だからレイテンシーが増えるわけで、これを高速化するにはメモリー帯域が足りないのである。
別の例では音声認識を例にとっている。これも精度を引き上げるためには大規模モデルを使うとともに、性能を引き上げるためにはBatch Sizeを長く取るのが効果的だが、ある程度Batch Sizeをとっても性能が頭打ちになってくる。この主要因は、Tokenの生成がメモリー性能に依存するからだ。
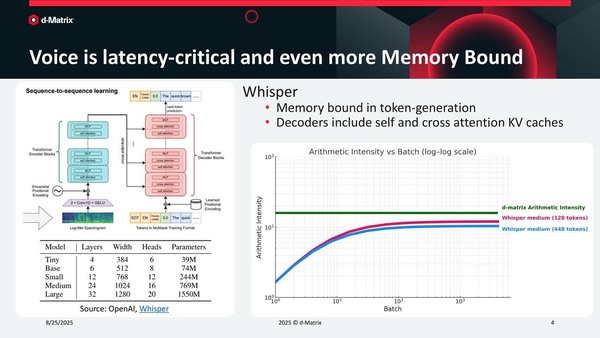
音声認識の例。WhisperとはOpenAIのWhisperのこと
そこでd-Matrixが考えたのは、SRAMと演算器の密結合である。「そんなのこれまでもあったじゃないか」という声も聞こえてきそうだが、このあたりの話は後述する。今回発表されたCorsairは、8つのチップレットから構成される形になっている。

それぞれのチップレットに2個ずつ、LPDDR5-6400(32bit幅)が接続されるはずだが、それはチップレット周囲のカバーに隠れて見えない
そのチップレットの構造が下の画像だ。4つのスライスから構成されるクワッドという管理単位が4つで1つのチップレットである。つまり1つのチップレットにスライスが16個搭載される格好だ。

チップレットの正確なサイズは公開されていないが、上の写真から推察するに21.7×14.3mmといったところで310.3mm2前後かと思われる
現在のCorsair搭載カードは、1枚のPCIeカードに8枚のチップレットが搭載されるだけである。これは物理的な配置がこれ以上難しいということもあるが、消費電力が600Wと結構なもの(概算で言えばチップレット8つで600W、すなわち1個あたり75W)であり、これ以上搭載が難しいという話でもある。
ところで2つ上の画像を見るとカード上端がやはりコネクター構造になっているのがわかる。これは2枚のCorsairカードをブリッジで接続するためのもので、こうすることで16チップレットの構成を容易に取れるとする。

カード上端がコネクター構造になっているのは、2枚のCorsairをブリッジで接続するため。いにしえのSLIブリッジやAMDのInstinct MI100のXGMIブリッジカードを連想する構成である
さらに大規模な構成が必要な場合、64チップレットまでの構成が可能である。これは1つのサーバーシャーシの中にCorsairカード×2の構成を2つ搭載し、間をPCIeスイッチで接続。このサーバーシャーシ2つは、PCIeスイッチまたは同社のJetStream I/Oアクセラレーターを使って接続するというものだ。

2枚のCorsairカードと1枚のJetStreamでペアを組む構成となる。Scale upはPCIeスイッチ同士をOCuLink(PCIe Gen5なのでCopperLink)ケーブルで接続する形を想定している模様。レイテンシー的にこれが限界なのだろう
JetStreamは正式には今年9月8日に発表されたばかりの製品なのでHot Chipsの時点ではまだ未公開であり、それもあってか詳細が明らかにされていないが、通常のイーサネットカードよりも低いレイテンシーで通信ができるというものである。
2枚のCorsairカードと1枚のJetStreamでペアを組む構成では、それぞれのシャーシのJetStream同士をネットワークスイッチを経由して接続することで、3つ以上のサーバーをスケールアウトのように接続することも可能だ。ただスケールアウトの場合では、当然通信のレイテンシーが大幅に増えるので、スケールアップのケースではPCIeでの接続を考えており、2シャーシまでを想定している模様だ。
この連載の記事
-
第864回
PC
なぜAMDはチップレットで勝利したのか? 2万ドルのウェハーから逆算する経済的合理性 -
第863回
PC
銅配線はなぜ限界なのか? ルテニウムへの移行で変わる半導体製造の常識と課題 -
第862回
PC
「ビル100階建て相当」の超難工事! DRAM微細化が限界を超え前人未到の垂直化へ突入 -
第861回
PC
INT4量子化+高度な電圧管理で消費電力60%削減かつ90%性能アップ! Snapdragon X2 Eliteの最先端技術を解説 -
第860回
PC
NVIDIAのVeraとRubinはPCIe Gen6対応、176スレッドの新アーキテクチャー搭載! 最高クラスの性能でAI開発を革新 -
第859回
デジタル
組み込み向けのAMD Ryzen AI Embedded P100シリーズはZen 5を最大6コア搭載で、最大50TOPSのNPU性能を実現 -
第858回
デジタル
CES 2026で実機を披露! AMDが発表した最先端AIラックHeliosの最新仕様を独自解説 -
第857回
PC
FinFETを超えるGAA構造の威力! Samsung推進のMBCFETが実現する高性能チップの未来 -
第856回
PC
Rubin Ultra搭載Kyber Rackが放つ100PFlops級ハイスペック性能と3600GB/s超NVLink接続の秘密を解析 -
第855回
PC
配線太さがジュース缶並み!? 800V DC供給で電力損失7~10%削減を可能にする次世代データセンターラック技術 -
第854回
PC
巨大ラジエーターで熱管理! NVIDIA GB200/300搭載NVL72ラックがもたらす次世代AIインフラの全貌 - この連載の一覧へ






































")
















