




画像生成AIを使うためのツール
ローカルで画像生成を行うためのツールは多種多様に存在する。ここでは、導入の容易さ・操作性・カスタマイズ性の観点から、現在広く使われている代表的なツールを紹介する。
Fooocus(最も手軽に始められる)
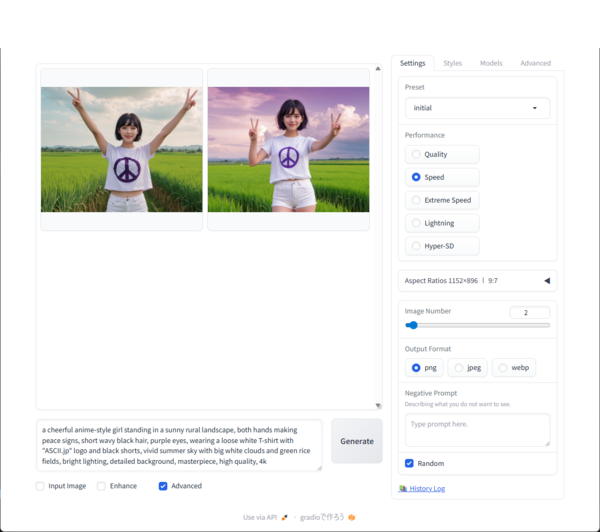
「Fooocus」は、SDXLモデルを手軽に利用できるよう最小限の設定で構成されたツール。複雑な環境構築やPython操作を必要とせず、アプリを起動してテキストを入力するだけで画像生成できる。自動で適切なパラメータを調整してくれるため、初心者でも比較的安定した生成結果を得やすい。
UIは直感的で、プロンプトやスタイルのテンプレートも充実。まず「画像を生成してみる」体験として非常にハードルが低く、ローカル画像生成をこれから学びたい人に向いている。
Stability Matrix(初心者にも安心の公式統合ツール)

「Stability Matrix」は、Stability AIが支援する一体型のローカル向け管理・実行ツールで、モデル管理・UI実行・拡張インターフェースを一つにまとめている。Web UI/デスクトップ版どちらでも提供され、「ワンクリックでインストール」や「複数UIパッケージの一元管理」などが可能。
このため、Python環境やGit操作などに自信がない初心者でも導入が比較的容易。さらに、公式ツールであるためモデル更新・セキュリティ・互換性面で安心感が高い。使い始めてから、将来的に拡張やカスタマイズを考える人にとっても安心できる選択肢だ。
ComfyUI(高機能・柔軟性重視。クラウド対応も進展)
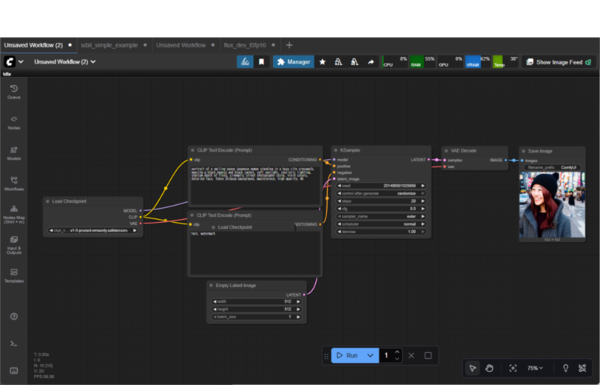
「ComfyUI」は、ノードベースのワークフローで画像生成プロセスを構築できる高機能ツールだ。プロンプト、LoRA、ControlNetなどを視覚的に組み合わせて制御でき、複雑な生成パイプラインを自由に設計できる。高度な設定や細かなパラメータ調整をしたいユーザーにとって、最も柔軟性の高い環境といえる。
2024年10月にリリースされた「ComfyUI V1」および「ComfyUI Desktop」では、導入手順が大幅に簡略化された。従来はPythonやGitのセットアップが必要だったが、Desktop版ではワンクリックで起動できるスタンドアロン構成が採用されている。これにより、初心者でも比較的スムーズにComfyUIを使い始められるようになった。
さらに2025年11月現在、公式の「Comfy Cloud」がパブリックベータとして公開されている。インストール不要でブラウザからComfyUIを利用でき、NVIDIA A100(40GB)GPU上で動作。400以上のオープンソースモデルや17種類の拡張ノードがプリインストールされており、月額20ドルで最大8時間/日まで利用できる。クラウド環境でもローカル同様のワークフローが再現できる点が大きな特徴だ。
このようにComfyUIは、ローカルとクラウドの両面で利用環境が整い、クリエイターや開発者が場所を問わず同一の制作フローを共有できるプラットフォームへと進化しつつある。
AUTOMATIC1111 WebUI
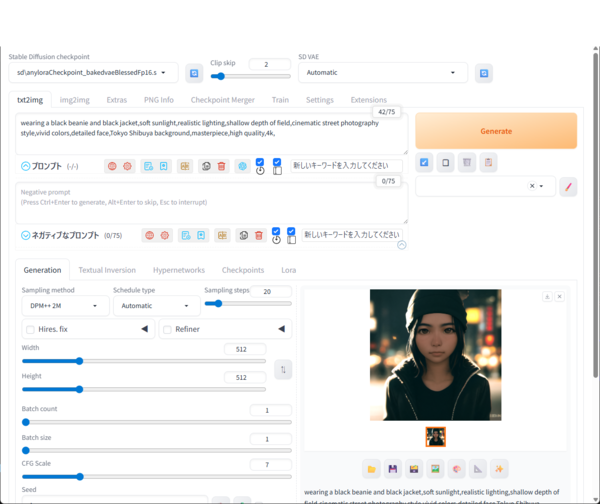
「AUTOMATIC1111 WebUI」は、長年にわたってStable Diffusion WebUI環境のデファクトスタンダードとして使用されてきたツールだ。Webブラウザ操作でプロンプト入力・LoRA・ControlNetなど多彩な機能を扱える。拡張機能(Extension)も豊富で、カスタマイズ性は極めて高い。
一方で、導入にはPython環境の準備・コマンド操作などやや技術的な知識が必要なため、初心者には敷居が高め。現在では、より手軽な「Fooocus」「Stability Matrix」などに導入ユーザーが流れてきている。
その他のツール
そのほかにも、「InvokeAI」や「DiffusionBee」といったツールがある。InvokeAIは安定したバッチ処理や画像管理機能に強みを持ち、DiffusionBeeはMac向けに設定簡易化されたアプリとして人気がある。どちらも導入ハードルは低く、まずはローカル画像生成を体験してみたいユーザーに向いている。
様々な付随する技術
画像生成AIの品質や表現力を高めるためには、モデル本体だけでなく、生成を補助する技術も重要だ。Stable Diffusion系では、「ControlNet」や「LoRA」といった拡張技術が大きな役割を果たしており、これらを組み合わせることで、構図の制御やスタイルの再現など、より緻密な生成が可能になる。
ControlNet(構図やポーズを精密に制御)
ControlNetは、既存の画像やポーズ情報をもとに生成結果を制御する技術だ。例えば、人物の輪郭やポーズ、構図を保持したまま、衣装や背景だけを差し替えるといった使い方ができる。OpenPoseやCanny、Depthなどの入力データを利用し、自由な構図生成を安定して再現できるのが特徴だ。
特に商業用途では、構図の一貫性を保ちながら複数のバリエーションを生成できるため、イラスト制作やプロダクトデザインの現場でも広く使われている。
LoRA(軽量な学習によるスタイル適用)
LoRA(Low-Rank Adaptation)は、モデル全体を再学習することなく、新しいキャラクターや画風を軽量に学習・適用できる技術。数百MB規模の小さな追加データを読み込むだけで、既存モデルに特定のスタイルや人物の特徴を反映できる。
ユーザーコミュニティによって数多くのLoRAモデルが共有されており、「特定の絵柄」「人物」「衣装」「構図傾向」などを簡単に再現できるようになっている。生成AIを自分の表現スタイルに合わせて拡張できる点で、最も広く使われている技術のひとつだ。
LCM-LoRA(高速生成を実現する軽量拡張)
LCM-LoRA(Latent Consistency Model LoRA)は、LoRAの仕組みを応用して生成速度を大幅に向上させる技術。従来は20~30ステップ程度必要だった拡散プロセスを、わずか数ステップで完了できるようにする。これにより、SDXLやFLUX.1といった高精度モデルでも高速に画像生成を行える。
品質を大きく損なわずに処理時間を短縮できるため、リアルタイム生成や動画生成の分野でも活用が進んでいる。今後、軽量モデル時代の標準技術のひとつになると見られている。
これらの技術は単独でも強力だが、組み合わせることでさらに表現の幅が広がる。ローカル環境での画像生成を深める上で、理解しておきたい基本要素といえる。
この連載の記事
-
第40回
AI
Suno級がローカルで? 音楽生成AI「ACE-Step 1.5」を本気で検証 -
第39回
AI
欲しい映像素材が簡単に作れる! グーグル動画生成AI「Veo 3.1」の使い方 -
第38回
AI
最新の画像生成AIは“編集”がすごい! Nano Banana、Adobe、Canva、ローカルAIの違いを比べた -
第37回
AI
画像生成AIで比較!ChatGPT、Gemini、Grokどれを選ぶ?得意分野と使い分け【作例大量・2025年最新版】 -
第36回
AI
【無料で軽くて高品質】画像生成AI「Z-Image Turbo」が話題。SDXLとの違いは? -
第35回
AI
ここがヤバい!「Nano Banana Pro」画像編集AIのステージを引き上げた6つの進化点 -
第33回
AI
初心者でも簡単!「Sora 2」で“プロ級動画”を作るコツ -
第32回
AI
【無料】動画生成AI「Wan2.2」の使い方 ComfyUI設定、簡単インストール方法まとめ -
第31回
AI
“残念じゃない美少女イラスト”ができた! お絵描きAIツール4選【アニメ絵にも対応】 -
第30回
AI
画像生成AI「Midjourney」動画生成のやり方は超簡単! - この連載の一覧へ




とは")
















の1台が今ならオトク!")
























")

