




gpt-oss-20bの出力例 まずは自己紹介から
それではいよいよローカルでgpt-oss-20bを動かしてみよう。まずは日本語でのやりとりが可能かどうかを確かめるため下記のプロンプトからスタート。
プロンプト:日本語で自己紹介して
一瞬推論に入るが、すぐに回答を生成開始。ブラウザー経由のChatGPTと比べると多少ゆっくりではあるが、しっかりとした日本語で自己紹介をしてくれた。
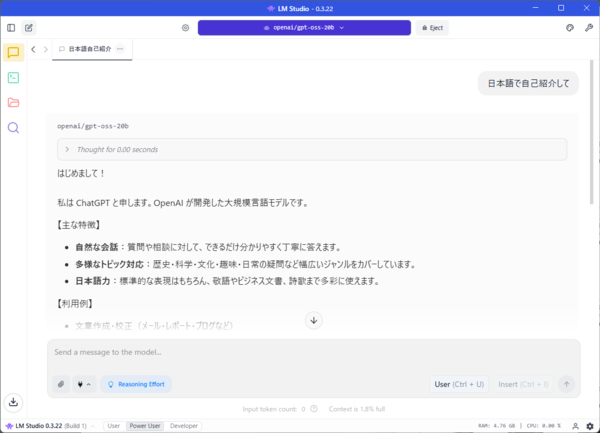
回答の末尾には生成速度などの統計が表示されている。これは、ローカルLLMがどの程度のスピードで応答を生成したか、どれくらいの長さのテキストを返したか、そしてどのように出力を終了したかを示す情報だ。
たとえば「13.45 tok/sec」は1秒あたりに出力されたトークン数を意味し、この数値が大きいほど生成が速いことを示す。「335 tokens」は生成されたトークン(語や記号などの単位)の総数、「0.26s to first token」は最初の文字が返ってくるまでの時間で、応答の開始速度を表している。
また、「Stop reason: EOS Token Found」は、文の終わりを示す特殊なトークン(EOS=End of Sequence)が出現したことで自然に出力が終了したことを意味する。他にも、指定したトークン数の上限に達した場合は「Length」、あらかじめ設定した文字列が出たときは「Stop Sequence」などと表示される。
この統計は主に開発者やパワーユーザー向けの情報だが、応答速度や処理量の目安として知っておくと役に立つ。

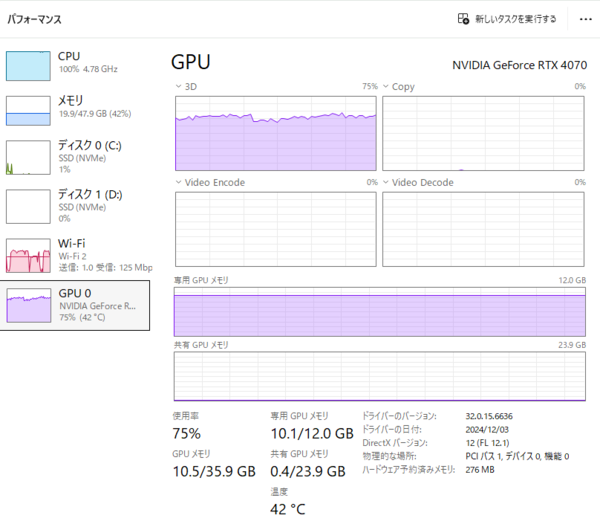
タスクマネージャーで回答生成中のマシンの状態を確認すると、GPUとCPUの双方に大きな負荷がかかっているのがわかる。GPUの使用率は75%、GPUメモリは12GB中10.1GBが専用メモリとして使用されている。これは、量子化済みの20Bモデルをフルに活用して推論をしている状況だと考えられる。
一方、CPUの使用率は100%に達しており、すべてのコアがフル稼働している状態だ。ローカルLLMの実行中は、GPUによる推論処理に加えて、CPU側でも入出力の管理やトークンのバッファリングなどが並列的に行われるため、高負荷になりやすい。また、システムメモリ(RAM)も47.9GB中19.9GBが使用されており、モデルのロードやプロンプト処理に伴う一時的なワークスペースとして機能していると考えられる。
本記事はアフィリエイトプログラムによる収益を得ている場合があります
この連載の記事
-
第47回
AI
9Bなのに120B超え!? Qwen3.5-9BがローカルAIの常識を変えた -
第46回
AI
面倒なファイル整理、AIに丸投げできる? 「Claude Cowork」をガチ検証 -
第45回
AI
面白すぎて危険すぎ! PCを“勝手に動かす”AI、OpenClaw(旧Moltbot/Clawdbot)とは -
第44回
AI
「こんなもの欲しいな」が、わずか数時間で形になる。AIツール「Google Antigravity」が消した“実装”という高い壁 -
第43回
AI
ChatGPT最新「GPT-5.2」の進化点に、“コードレッド”発令の理由が見える -
第42回
AI
ChatGPT、Gemini、Claude、Grokの違いを徹底解説!仕事で役立つ最強の“AI使い分け術”【2025年12月最新版】 -
第41回
AI
中国の“オープンAI”攻撃でゆらぐ常識 1兆パラ級を超格安で開発した「Kimi K2」 の衝撃 -
第40回
AI
無料でここまでできる! AIブラウザー「ChatGPT Atlas」の使い方 -
第39回
AI
xAI「Grok」無料プラン徹底ガイド スマホ&PCの使い方まとめ -
第38回
AI
【無料】「NotebookLM」神機能“音声概要”をスマホで使おう! 難しい論文も長〜いYouTubeも、ポッドキャスト化して分かりやすく - この連載の一覧へ















の31.5型ディスプレーはうっとりするほどキレイだった、でもお値段は……")



























で240Hz&0.03msという欲張り4Kゲーミングディスプレーが至高の逸品すぎた")





